o1 Vision + System Prompt Support: The Pro Tier Expands

Table of Contents
o1 Vision + System Prompt Support: The Pro Tier Expands #
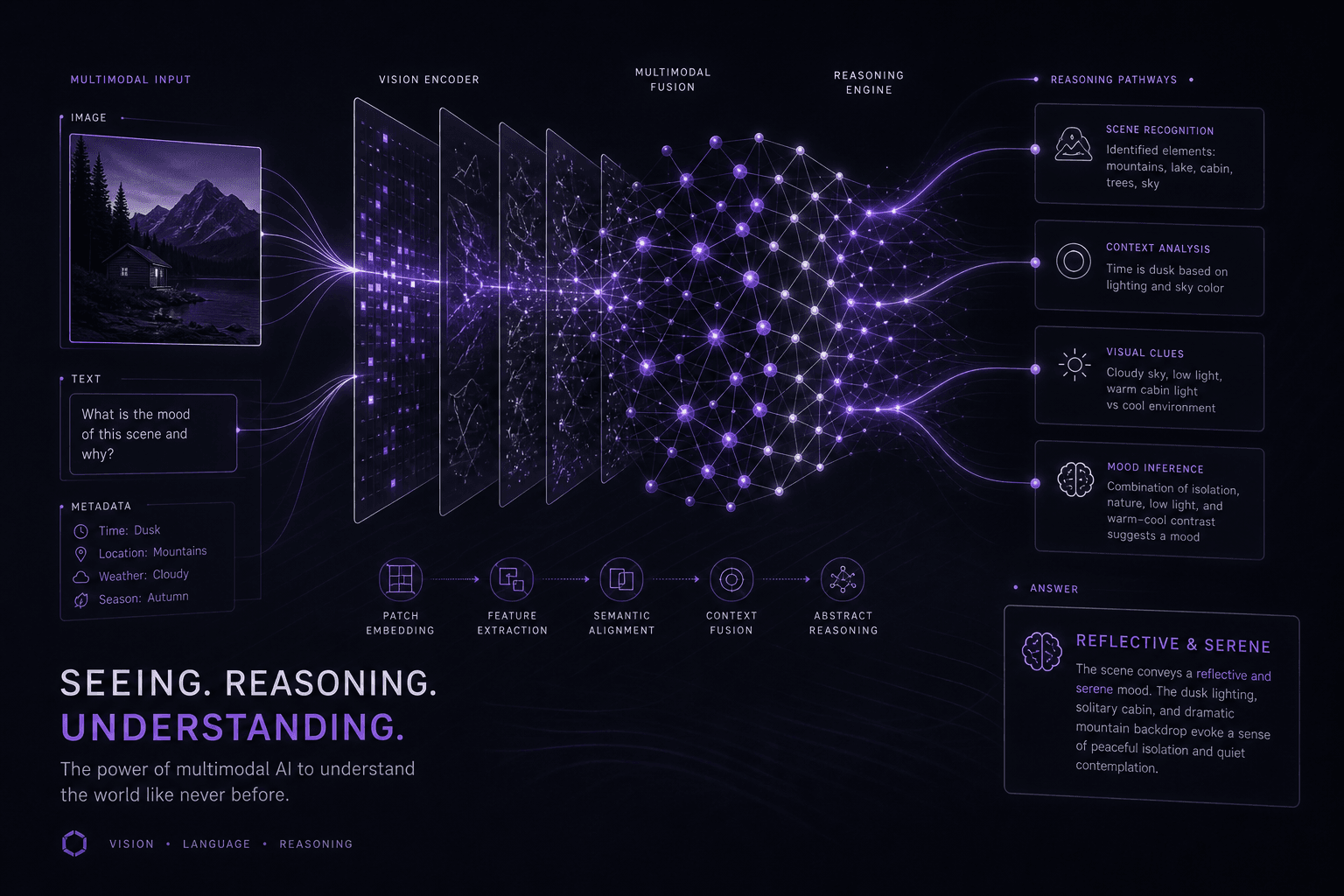
OpenAI's o1 reasoning model now supports vision capabilities and developer messages, extending chain-of-thought reasoning to visual analysis tasks. Released on December 17, 2024, these additions transform o1 from a text-only reasoning engine into a multimodal system capable of analyzing images, diagrams, charts, and visual data with the same deliberate reasoning approach that distinguishes it from standard LLMs.
The update arrives alongside o1's general availability through OpenAI's API and ChatGPT Pro, representing a significant expansion of the model's practical utility for developers building vision-enabled applications.
What Just Shipped: o1 Vision and Developer Messages #
OpenAI delivered two major capabilities to the o1 model family this week: native vision input support and a new developer message format replacing the traditional system message. These features address the most requested additions since o1-preview launched in September.
Vision support enables o1 to accept image inputs—base64-encoded images or image URLs—alongside text prompts, applying its chain-of-thought reasoning to visual analysis. This includes photographs, diagrams, charts, screenshots, and documents. The model processes visual content through the same reasoning pipeline that produces its distinctive step-by-step analysis on text tasks.
Developer messages represent an architectural shift in how instructions are passed to reasoning models. Unlike system messages in standard GPT models, developer messages establish a clear chain-of-command hierarchy: developer instructions take precedence over user instructions when conflicts arise. This distinction matters for reasoning models because the chain-of-thought process must respect hard constraints (API schemas, safety boundaries, format requirements) even when users attempt to override them.
How o1 Vision Changes the Multimodal Landscape #
o1 vision introduces reasoning-first visual analysis, a fundamentally different approach than GPT-4o's immediate-response pattern. When presented with a complex diagram or chart, o1 doesn't generate an instant description—it works through the visual logic methodically.
Consider a financial analyst examining a quarterly earnings slide. GPT-4o vision provides immediate surface-level descriptions: "This shows Q3 revenue at $2.4M with a 15% increase." o1 vision produces deliberate analysis: "The revenue trend shows three consecutive quarters of acceleration... the margin expansion suggests operational leverage... the geographic breakdown indicates emerging market dependency." The reasoning model identifies patterns, draws inferences, and surfaces insights that require cognitive effort rather than pattern matching.
The practical impact extends across use cases:
- Scientific analysis: o1 can work through experimental data visualizations, identifying methodological issues or unexpected correlations
- Technical troubleshooting: Screenshot analysis includes systematic reasoning about what components might fail based on error patterns
- Document understanding: Complex form parsing with verification steps that catch inconsistencies
- Code review: Visual analysis of architecture diagrams with reasoning about coupling, dependencies, and potential bottlenecks
Developer Messages vs System Messages: The Chain-of-Command Shift #
OpenAI replaced system messages with developer messages in o1 to establish unambiguous precedence for critical instructions. The naming change signals a functional difference: developer messages carry authority that user messages cannot override through prompt injection or social engineering.
In traditional GPT models, the boundary between system and user messages is soft. Cleverly crafted user prompts can often override system instructions—a persistent challenge for production deployments. Developer messages in o1 create a hard boundary. When a developer message specifies "always respond in JSON format," the reasoning model treats this as an immutable constraint regardless of user requests.
The implementation matters for production systems:
{
"model": "o1",
"messages": [
{
"role": "developer",
"content": "You are a data extraction assistant. Always respond with valid JSON containing 'extracted_fields' and 'confidence' keys."
},
{
"role": "user",
"content": "Extract data from this invoice image..."
}
]
}This chain-of-command structure becomes essential for vision applications where users might upload manipulated images designed to override instructions. The reasoning model's deliberate processing can catch inconsistencies between visual content and user claims, using developer-provided constraints as the authoritative source.
o1 Vision vs GPT-4o Vision: Capability Comparison #
o1 vision and GPT-4o vision serve different purposes—speed versus depth, immediate response versus deliberate analysis. Understanding when to use each determines application success.
| Capability | GPT-4o Vision | o1 Vision | Recommendation |
|---|---|---|---|
| Response latency | ~500-800ms | 5-30 seconds | GPT-4o for real-time, o1 for analysis |
| Complex reasoning | Surface patterns | Deep inference | o1 for multi-step visual logic |
| Simple description | Excellent | Overkill | GPT-4o for basic image captions |
| Error detection | Moderate | High | o1 for quality-critical workflows |
| Chart/diagram analysis | Descriptive | Analytical | o1 for insight extraction |
| Cost per request | Lower | Higher (~6x) | GPT-4o for high-volume, o1 for precision |
The cost differential is significant: o1 vision pricing runs approximately 6× higher than GPT-4o vision due to the reasoning overhead. For applications processing thousands of images daily, this cost structure demands careful routing logic—GPT-4o for initial filtering and simple extraction, o1 for complex analysis requiring verification.
Benchmark results show the expected pattern: o1 outperforms GPT-4o on visual reasoning tasks by substantial margins while showing no advantage (and often disadvantage) on simple recognition tasks. The MMMU benchmark (multimodal multi-discipline understanding) demonstrates 78.1% accuracy for o1 versus 69.1% for GPT-4o—a meaningful improvement for applications requiring genuine comprehension rather than description.
Code Example: Using o1 with Images #
Implementing o1 vision requires the standard OpenAI SDK with the new developer role and image URL or base64 encoding. The structure parallels GPT-4o vision but with role substitution.
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="o1",
messages=[
{
"role": "developer",
"content": "Analyze this architectural diagram and identify potential single points of failure. Respond with specific component names and mitigation strategies."
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Review this system architecture for our payment processing pipeline."
},
{
"type": "image_url",
"image_url": {
"url": "https://example.com/architecture-diagram.png"
}
}
]
}
]
)
print(response.choices[0].message.content)For base64-encoded images, the pattern follows GPT-4o:
import base64
with open("chart.png", "rb") as image_file:
base64_image = base64.b64encode(image_file.read()).decode('utf-8')
response = client.chat.completions.create(
model="o1",
messages=[
{
"role": "developer",
"content": "Extract all numerical data from this chart and verify that percentages sum to 100%. Report any discrepancies."
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Analyze this quarterly budget allocation chart."
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/png;base64,{base64_image}"
}
}
]
}
]
)The Reasoning Effort Parameter: Controlling Compute #
o1 introduces a reasoning_effort parameter allowing developers to trade accuracy for speed across low, medium, and high settings. This control proves especially valuable for vision applications where not every image requires maximum analysis depth.
The parameter affects the length and complexity of the internal chain-of-thought:
- Low: Minimal reasoning steps, fastest response, suitable for simple visual queries
- Medium: Balanced reasoning depth, default setting for general use
- High: Extended chain-of-thought, maximum analysis depth for critical decisions
For a document scanning application processing thousands of receipts daily, reasoning_effort: "low" handles straightforward extraction while reasoning_effort: "high" processes flagged anomalies requiring verification. This tiered approach optimizes cost without sacrificing capability where it matters.
Initial testing suggests the latency spread ranges from ~5 seconds (low) to ~30+ seconds (high) for complex visual inputs. The cost difference between settings is roughly 2-3×, making the parameter an essential optimization lever for production deployments.
Real-World Use Cases for o1 Vision #
Production applications for o1 vision cluster around domains where visual analysis errors carry significant consequences. The reasoning overhead pays for itself in quality-critical workflows.
Medical Imaging Support
Radiology workflows increasingly involve AI-assisted preliminary screening. o1 vision's deliberate analysis can flag potential findings with explanatory reasoning chains—"This shadow pattern suggests possible nodule formation based on density distribution..."—giving radiologists structured context rather than raw classifications.
Financial Document Verification
Invoice processing and financial statement analysis benefit from reasoning-driven verification. o1 can cross-check line items against totals, verify compliance with formatting standards, and flag anomalies with explanations—"The subtotal calculation appears inconsistent with the itemized amounts; potential data entry error in line 3."
Engineering Diagram Review
Technical schematic analysis requires understanding component relationships, not just identifying parts. o1 vision can trace signal paths, identify potential interference sources, and verify compliance with design standards through structured reasoning.
Quality Control Visual Inspection
Manufacturing defect detection gains explanatory power—"The surface irregularity pattern suggests tooling wear rather than material contamination, based on the consistent directional marking..."—enabling targeted maintenance rather than generic rejection.
API Pricing and Availability #
o1 vision commands a premium price reflecting its reasoning overhead, currently approximately $15 per million input tokens and $60 per million output tokens. Vision inputs add additional costs based on image size and detail level.
| Model | Input | Output | Vision Input (per image) |
|---|---|---|---|
| GPT-4o | $2.50/M | $10/M | ~$0.005-0.015 |
| o1 | $15/M | $60/M | ~$0.03-0.09 |
The cost multiplier reflects the compute intensity of chain-of-thought generation. For applications where accuracy prevents costly errors—compliance verification, medical screening, financial validation—the price premium often pays for itself through error reduction.
Availability includes:
- ChatGPT Pro: Full access to o1 with vision
- API: Tier 5 developers and above (requires $1,000+ historical spend)
- Azure OpenAI: Rolling out to eligible enterprise customers
Rate limits remain restrictive compared to standard models—approximately 20 requests per minute for most API tiers—reflecting the compute intensity of reasoning generation.
What This Means for Builders #
The o1 vision expansion creates new architectural possibilities for multimodal applications requiring analytical depth. Builders can now deploy reasoning-capable visual analysis in production systems, though cost and latency constraints demand strategic implementation.
Key architectural considerations:
Hybrid Routing: Most applications benefit from tiered processing—GPT-4o vision for initial screening and simple extraction, o1 vision for flagged items requiring verification. This pattern maintains throughput while ensuring accuracy for edge cases.
Async Processing: The 5-30 second latency makes o1 vision unsuitable for synchronous user-facing interactions. Queue-based architectures with progress indicators provide better UX for reasoning-intensive tasks.
Caching Strategy: Identical or similar images processed repeatedly should cache reasoning outputs. The deterministic nature of o1's reasoning (temperature fixed at 1) enables effective caching strategies.
Developer Message Design: The shift from system to developer messages requires revising prompt templates. Treat developer messages as immutable constraints that establish ground rules, not as conversational context.
Frequently Asked Questions #
Does o1 support vision capabilities as of December 2024? #
Yes, o1 now supports vision capabilities as of the December 17, 2024 update. The model accepts image inputs including photographs, diagrams, charts, and documents through the same API structure as GPT-4o vision. Both base64-encoded images and image URLs are supported. The vision capability extends o1's chain-of-thought reasoning to visual analysis tasks.
What's the difference between developer messages and system messages in o1? #
Developer messages establish a hard precedence hierarchy that system messages in standard GPT models do not enforce. When conflicts arise between developer instructions and user requests, developer messages always take precedence. This prevents prompt injection attacks from overriding critical constraints like output format or safety boundaries. The naming change from "system" to "developer" signals this architectural difference in authority.
How does o1 vision compare to GPT-4o vision for image analysis? #
o1 vision provides deeper analytical reasoning while GPT-4o vision offers faster response times. On the MMMU multimodal understanding benchmark, o1 achieves 78.1% accuracy versus GPT-4o's 69.1%. However, o1 responses take 5-30 seconds versus GPT-4o's sub-second latency. For simple description tasks, GPT-4o is more cost-effective. For complex analysis requiring inference and verification, o1's reasoning depth justifies the cost and latency overhead.
Can I use o1 vision through the API or only in ChatGPT Pro? #
o1 vision is available through both ChatGPT Pro and the OpenAI API. API access requires Tier 5 status (approximately $1,000 in historical API spend). The API implementation uses the same endpoint structure as other vision models with the model: "o1" parameter and developer role replacing system messages. Rate limits are lower than standard models—approximately 20 requests per minute for most tiers.
What image formats does o1 vision support? #
o1 vision supports PNG, JPEG, WEBP, and non-animated GIF formats through base64 encoding or URL references. The same format limitations apply as GPT-4o vision—no PDF documents, video files, or animated GIFs. Maximum image size and resolution limits follow GPT-4o specifications. For best results, high-resolution images with clear text and structured layouts produce the most reliable analysis.
Does o1 vision support function calling with image inputs? #
Function calling with o1 vision is supported but with important limitations. The reasoning model can analyze images and determine appropriate function calls based on visual content, but the extended latency (5-30 seconds) makes real-time tool use patterns impractical. The feature works best for analytical workflows where the vision analysis drives structured data extraction through function schemas rather than interactive tool chains.
What is the reasoning_effort parameter and how does it affect vision tasks? #
The reasoning_effort parameter controls the depth of chain-of-thought generation with low, medium, and high settings. For vision tasks, low effort (5 seconds) handles straightforward image description and simple extraction. Medium effort (default, ~10-15 seconds) balances depth and speed for general analysis. High effort (30+ seconds) provides maximum reasoning depth for complex diagrams, scientific images, or verification-critical applications. The parameter affects both latency and cost—high effort consumes approximately 2-3× more tokens than low effort.
Should I migrate my vision workflows from GPT-4o to o1? #
Migration makes sense for workflows requiring analytical depth, verification, or error detection—not for simple description or high-volume processing. The cost differential (6× higher) and latency penalty (seconds vs. milliseconds) mean GPT-4o remains optimal for many use cases. Consider o1 for medical imaging support, financial document verification, engineering diagram analysis, and quality control where reasoning depth prevents costly errors. Hybrid architectures using both models maximize efficiency.
Does o1 vision support video analysis or only static images? #
o1 vision supports only static images, not video files or frame sequences. For video analysis, extract key frames and process them individually, or use GPT-4o's native video capabilities. The reasoning model's architecture is optimized for single-image analysis with extended chain-of-thought processing rather than temporal sequence understanding. Future updates may extend support, but video analysis currently requires frame extraction workflows.
Are there rate limits specific to o1 vision API calls? #
o1 vision shares the same restrictive rate limits as o1 text—approximately 20 requests per minute for most API tiers. These limits reflect the compute intensity of reasoning generation. Batch processing patterns work better than real-time streaming for o1 vision applications. Enterprise customers on Azure OpenAI may negotiate higher limits, but the fundamental constraint is compute availability for chain-of-thought generation.
Can I combine developer messages with vision inputs in the same request? #
Yes, developer messages work alongside vision inputs and are the recommended pattern for production o1 vision applications. The developer message establishes constraints and output format requirements while the user message contains the image and task description. This combination provides the chain-of-command benefits for multimodal workflows where output consistency and constraint enforcement matter.
What are the latency differences between o1 vision and GPT-4o vision? #
o1 vision responses range from 5-30 seconds depending on reasoning_effort settings, while GPT-4o vision typically responds in 500-800 milliseconds. The 10-60x latency difference fundamentally shapes appropriate use cases. GPT-4o vision suits real-time applications like live camera analysis or interactive user experiences. o1 vision fits asynchronous workflows like document processing pipelines, batch analysis jobs, and quality verification systems where accuracy trumps speed.
The Bottom Line: Reasoning Vision Becomes Real #
o1 vision represents a genuine expansion of multimodal AI capabilities—the first widely available model combining visual perception with structured reasoning. The chain-of-thought approach to image analysis produces different outputs than immediate-response vision models: explanatory rather than descriptive, analytical rather than observational.
For builders, this creates new architectural possibilities but demands strategic implementation. The cost and latency constraints mean o1 vision complements rather than replaces GPT-4o vision in most applications. Hybrid architectures—fast screening with GPT-4o, deep analysis with o1—optimize both efficiency and accuracy.
The developer message addition addresses a real production concern: prompt injection in multimodal applications. The hard precedence hierarchy enables trust in constraint enforcement even when processing untrusted user uploads. This security improvement, combined with reasoning-driven accuracy, positions o1 vision as a specialized tool for quality-critical visual workflows.
As 2024 closes, the multimodal AI landscape includes fast perception (GPT-4o), deep reasoning (o1), and open-weight alternatives (Llama 3.2, Pixtral). The builder's task is routing tasks to the appropriate capability tier—a complexity that didn't exist a year ago but now defines production AI architecture.
Related reading: OpenAI o3 Announcement: 87.5% on ARC-AGI | OpenAI Shipmas Day 1: Full o1 + ChatGPT Pro | Year-End Model League Tables 2024
Ready to build AI-powered workflows with the latest multimodal capabilities? Book an AI automation strategy call and let's architect your vision-enabled agent pipeline.
Related Posts

Google I/O 2026 Action List: How I Prompted Gemini 3.5 Flash and Antigravity Workflows
Google I/O 2026 just reset the AI tooling landscape. Here's the 9-action checklist for builders who want to ship this week, not just watch the keynote.

Anthropic vs. OpenAI vs. Google: The State of the Frontier in May 2026
A head-to-head breakdown of the three AI giants in May 2026: Claude Opus 4.6, GPT-5.3 and 5.4, Gemini 3.1 Pro. Real specs, real pricing, and what actually matters for builders.

Kimi K2 Open Weights: How I Prompted Moonshot's Frontier Model for Agentic Tool Use
How I direct Kimi K2 by Moonshot AI for agentic workflows, long-context tool calling, and workflow automation. A 1 trillion parameter MoE model with competitive benchmarks at 5-17x lower cost than GPT-5 and Claude.




