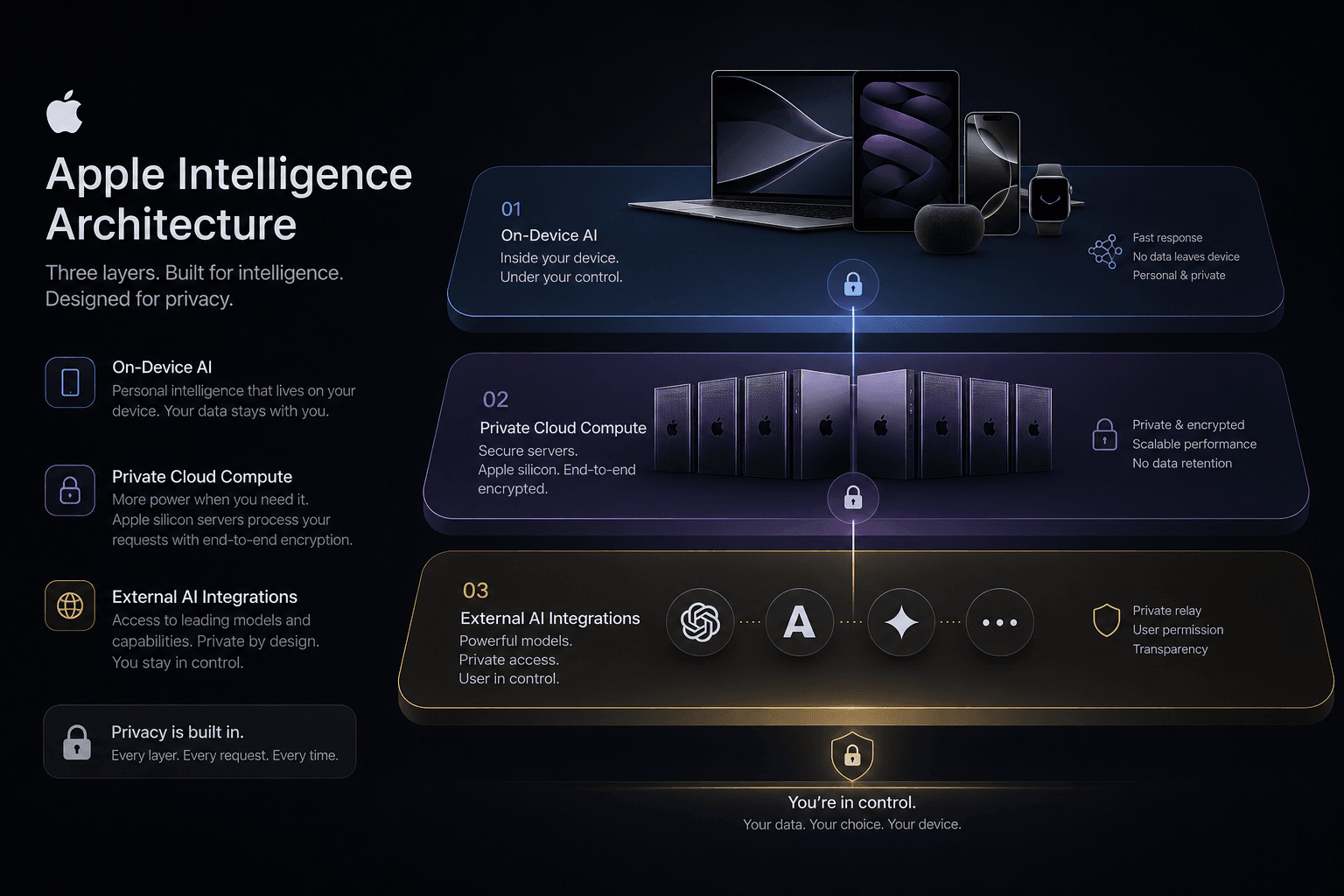
Apple's Three-Tier Model Architecture: On-Device, Private Cloud, and ChatGPT Explained

Table of Contents
Table of Contents #
- The Architecture Unveiled This Week
- Tier 1: On-Device Processing
- Tier 2: Private Cloud Compute
- Tier 3: ChatGPT Integration
- How Apple Decides Which Tier to Use
- Privacy at Every Layer
- Device Requirements
- Comparison: Apple vs Google vs Samsung
- What This Means for Developers
- The Long Game: Why This Architecture Matters
- FAQ: Apple Three-Tier AI Architecture
- The Bottom Line
The Architecture Unveiled This Week #
This week at WWDC 2024, Apple revealed that Apple Intelligence is built on a three-tier architecture designed to balance privacy, performance, and capability—processing locally when possible, escalating to purpose-built cloud servers for complex tasks, and integrating ChatGPT as an optional external fallback.
Four days ago, Tim Cook took the stage at Apple's annual developer conference and unveiled what analysts are calling the most sophisticated AI infrastructure strategy in the consumer tech industry. While Google and Samsung have raced to integrate cloud AI into their devices, Apple took a fundamentally different path—announcing a three-tier system that prioritizes on-device processing while maintaining privacy even when cloud computation is necessary.
This architecture represents Apple's response to a critical question: how do you deliver capable AI without forcing users to choose between functionality and privacy? Their answer is a tiered system that routes requests intelligently based on complexity, privacy requirements, and capability needs.
The Three Tiers at a Glance #
┌─────────────────────────────────────────────────────────────────────────┐
│ Apple Intelligence Architecture │
├─────────────────────────────────────────────────────────────────────────┤
│ │
│ TIER 1 TIER 2 TIER 3 │
│ ON-DEVICE PRIVATE CLOUD CHATGPT │
│ ━━━━━━━━━ ━━━━━━━━━━━━ ━━━━━━━ │
│ │
│ • Foundation Models • Apple Silicon • GPT-4o │
│ • Neural Engine • Cryptographic • External │
│ • 35 TOPS (A17 Pro) Verification Knowledge │
│ • ~99% of requests • Complex reasoning • Creative tasks │
│ • Zero latency • Stateful tasks • Deep expertise │
│ • Maximum privacy • Verifiable privacy • Opt-in only │
│ │
│ [Instant] [2-4 seconds] [3-6 seconds] │
│ [No network] [Encrypted] [Permission-based] │
│ │
└─────────────────────────────────────────────────────────────────────────┘Tier 1: On-Device Processing — The foundation runs on your device's Neural Engine, handling the vast majority of requests instantly without any network connection. Apple's optimized foundation models execute locally on A17 Pro and M-series chips.
Tier 2: Private Cloud Compute — When requests exceed on-device capabilities, Apple Intelligence escalates to dedicated Apple silicon servers with cryptographic privacy guarantees that prevent data storage or access by anyone, including Apple itself.
Tier 3: ChatGPT Integration — For specialized knowledge, creative tasks, and complex reasoning, Apple offers optional access to GPT-4o through a partnership with OpenAI—entirely permission-based with explicit opt-in for each request.
Why This Architecture Matters Today #
The three-tier approach isn't just an implementation detail—it's a strategic statement about the future of AI. By routing ~99% of requests to on-device processing, Apple achieves what competitors haven't: AI that works offline, responds instantly, and never exposes personal data to cloud infrastructure.
| Competitor | Architecture | Primary Processing | Privacy Model |
|---|---|---|---|
| Apple | Three-tier | On-device (99%) | Cryptographic verification |
| Cloud-first | Cloud (Gemini) | Standard cloud policies | |
| Samsung | Hybrid | Mixed on-device + Google Cloud | Varies by feature |
| OpenAI | Cloud-only | Cloud (GPT-4o) | OpenAI terms of service |
William Spurlock, an AI automation engineer and custom web designer, notes that this architecture fundamentally changes the economics of AI deployment. "Most AI applications today are built around API calls to cloud providers—every request costs money, adds latency, and creates a privacy exposure. Apple's approach flips that model: the vast majority of AI work happens locally at zero marginal cost, zero latency, and zero privacy risk."
The announcement this week establishes Apple as a serious AI platform with a differentiated approach that competitors will struggle to replicate—built on a bet that the future of AI is distributed, personal, and private.
Tier 1: On-Device Processing #
The foundation of Apple Intelligence is on-device processing using optimized foundation models that run directly on the A17 Pro and M-series Neural Engine, handling approximately 99% of requests instantly without any data leaving your device.
Apple Intelligence starts local. When you ask Siri to summarize a notification, rewrite an email, or generate a custom emoji, the processing happens entirely on your device's Neural Engine—no network request, no cloud server, no data transmission. This is possible because of significant hardware investments Apple made years ago, now coming to fruition with the A17 Pro and M-series chips.
The Neural Engine Hardware #
The A17 Pro chip powering iPhone 15 Pro and Pro Max features a 16-core Neural Engine capable of 35 trillion operations per second (TOPS). This is roughly double the performance of the A16 Bionic in standard iPhone 15 models, which explains why Apple Intelligence is restricted to Pro devices.
| Chip | Neural Engine | Performance | Apple Intelligence |
|---|---|---|---|
| A17 Pro | 16-core | 35 TOPS | ✅ Full support |
| A16 Bionic | 16-core | 17 TOPS | ❌ Not supported |
| M1/M2/M3 | 16-core | 11–18 TOPS | ✅ Full support |
| M3 Pro/Max | 16-core | 18+ TOPS | ✅ Full support |
The Neural Engine isn't just about raw TOPS—it's about sustained performance. Running foundation models requires consistent matrix multiplication throughput without thermal throttling. The A17 Pro's 3nm manufacturing process and improved thermal architecture enable sustained AI workloads that would cause older chips to overheat and slow down.
On-Device Foundation Models #
Apple developed a family of foundation models specifically optimized for on-device inference. These aren't full-scale GPT-4 class models—they're efficient, task-specialized systems that handle:
- Writing Tools — Rewrite, proofread, summarize, extract key points, convert to tables or lists
- Genmoji — Generate custom emoji from text descriptions entirely locally
- Image Playground — Create stylized images in Animation, Illustration, or Sketch styles
- Notification Summaries — Distill multiple notifications into coherent briefs
- Smart Reply — Suggest contextually relevant responses in Messages and Mail
- Siri Command Processing — Parse natural language and execute device commands
Apple trained these models using adapter techniques—small, task-specific layers that sit atop a base model. This approach allows efficient specialization without requiring massive models that wouldn't fit in device memory. The base model plus task-specific adapters can be loaded and unloaded dynamically based on what you're doing.
Memory Architecture #
A critical factor in on-device AI is memory bandwidth. Foundation models require rapid data movement between memory and processing units. Apple silicon's unified memory architecture provides dramatically higher bandwidth than traditional separated CPU/GPU memory pools.
All Apple Intelligence-compatible devices have at least 8GB of RAM. Loading even compressed foundation models requires substantial memory headroom above what the operating system consumes. The A17 Pro and M-series chips can access memory at speeds that keep the Neural Engine fed with data during inference.
Capabilities and Limitations #
On-device processing excels at:
| Task Type | Performance | Privacy |
|---|---|---|
| Text rewriting | <100ms | Maximum |
| Grammar checking | <100ms | Maximum |
| Short summarization | <200ms | Maximum |
| Genmoji creation | 1–2 seconds | Maximum |
| Simple image generation | 2–4 seconds | Maximum |
| Siri command parsing | <100ms | Maximum |
However, on-device models have limitations:
- Context window — Smaller than cloud models; long documents may require cloud escalation
- Knowledge cutoff — Local models don't have broad world knowledge beyond their training
- Creative complexity — Poems, stories, and creative writing beyond simple templates need Tier 3
- Multi-step reasoning — Complex analysis chains exceed on-device capability
The Privacy Advantage #
When processing happens on-device, privacy is inherent. Your prompts, your data, your context—none of it leaves your iPhone. This isn't a policy guarantee; it's an architectural impossibility of data exfiltration. There's no network connection to intercept, no server to compromise, no database of queries to leak.
For sensitive applications—health data, financial information, personal communications, proprietary business content—on-device processing enables AI capabilities that would be irresponsible to send to cloud providers. This architectural privacy opens use cases that cloud-first AI simply cannot address.
Developer Access #
Developers don't directly access the on-device foundation models—Apple doesn't expose APIs for arbitrary inference on their optimized models. Instead, developers integrate through purpose-built frameworks:
- Writing Tools — Available automatically in standard text controls; customizable for specialized domains
- Image Playground API — Embed image generation directly in your apps
- App Intents — Expose your app's actions to the AI system for Siri integration
This is a curated approach: Apple controls the model, the inference, and the exposure points. Developers gain powerful capabilities without managing model weights, inference optimization, or memory management—but they're working within Apple's framework rather than building arbitrary AI features.
Tier 2: Private Cloud Compute #
Private Cloud Compute is Apple's new server infrastructure that processes complex Apple Intelligence requests on dedicated Apple silicon servers with cryptographic privacy guarantees that prevent data storage or access by anyone—including Apple.
When an Apple Intelligence request exceeds on-device capabilities—complex reasoning, large document analysis, or sophisticated multi-step tasks—the system doesn't route to standard cloud AI providers. Instead, it escalates to Private Cloud Compute (PCC), a purpose-built infrastructure Apple unveiled this week that extends the security and privacy of Apple devices into the cloud for the first time.
This isn't marketing spin. PCC is architecturally different from every cloud AI service that came before it, with technical guarantees enforced by cryptography and hardware security rather than privacy policies and trust.
The PCC Hardware Stack #
Private Cloud Compute runs on custom-built server hardware bringing Apple silicon to the data center. These servers include the same hardware security technologies found in iPhone:
- Secure Enclave — Isolated security processor handling cryptographic operations
- Secure Boot — Cryptographic verification that only authorized code executes
- Code Signing — Enforceable guarantee that only approved software runs
- Hardware-rooted keys — Unique device keys that cannot be extracted
The servers run a hardened operating system based on iOS and macOS foundations, stripped to the minimum necessary for large language model inference. Apple excluded traditional data center components like remote shells, interactive debugging tools, and general-purpose logging systems that could expose user data.
Cryptographic Attestation #
Before your device sends any data to PCC, it performs cryptographic attestation to verify the server it's talking to:
┌─────────────────────────────────────────────────────────────────────────┐
│ Private Cloud Compute Attestation Flow │
├─────────────────────────────────────────────────────────────────────────┤
│ │
│ 1. DEVICE REQUEST │
│ Device asks load balancer for PCC nodes capable of handling │
│ the specific inference request │
│ │
│ 2. NODE SELECTION │
│ Load balancer returns subset of nodes with available capacity │
│ (Load balancer has NO user identifying information) │
│ │
│ 3. CRYPTOGRAPHIC VERIFICATION │
│ Device validates each node's certificate rooted in Secure Enclave │
│ Device confirms node's software image matches public transparency log│
│ │
│ 4. END-TO-END ENCRYPTION │
│ Device encrypts request directly to verified node's public key │
│ Only the verified PCC node can decrypt the request │
│ │
│ 5. PROCESSING & RESPONSE │
│ PCC node processes request using cloud foundation models │
│ Response encrypted back to device │
│ All request data cryptographically erased after response │
│ │
└─────────────────────────────────────────────────────────────────────────┘Your device will only send data to PCC nodes that cryptographically attest to running software that matches publicly listed images. If a server can't prove it's running authorized code—no data transmission occurs.
Stateless Computation Guarantee #
The defining characteristic of PCC is stateless computation on personal data. Apple designed the system with five enforceable requirements:
- Exclusive purpose — Data sent to PCC is used only for fulfilling your specific request
- No retention — Data is deleted immediately after the response is returned; nothing is logged or stored
- No Apple access — Data is never available to Apple staff, even those with administrative access
- Cryptographic erasure — The Secure Enclave randomizes encryption keys on every reboot, cryptographically wiping all storage
- Address space recycling — Memory regions handling user data are periodically purged
This isn't a policy—it's enforced by hardware. The Secure Enclave's key management, combined with the absence of persistent storage mechanisms, makes data retention technically impossible.
Target Diffusion: Preventing Targeted Attacks #
PCC includes sophisticated measures to prevent attackers from targeting specific users:
- OHTTP relay — Third-party relay hides your source IP address before requests reach PCC infrastructure
- RSA Blind Signatures — Single-use credentials authorize requests without tying them to your identity
- Node subset encryption — Your device encrypts requests only for a subset of nodes, not the entire service
- Non-identifiable metadata — Request metadata contains no personally identifiable information about your device
Even if an attacker compromised a PCC node, they couldn't steer specific users' traffic to that node. Targeting an individual would require compromising the entire PCC infrastructure—a broad attack likely to be detected.
Verifiable Transparency #
Apple committed to an extraordinary transparency measure: every production PCC software image will be publicly available for security research. This includes:
- OS and applications in binary form
- Security-critical source code (periodically published)
- sepOS firmware and iBoot bootloader in plaintext (a first for Apple)
- Publicly inspectable transparency log of all software measurements
Security researchers can verify that the privacy guarantees match Apple's public promises—and they'll be rewarded through the Apple Security Bounty program for findings, especially those undermining privacy claims.
What Runs on PCC #
Private Cloud Compute handles requests that exceed on-device capabilities:
| Request Type | Why It Needs PCC | Latency |
|---|---|---|
| Large document analysis | Exceeds on-device context window | 2–5 seconds |
| Complex Siri queries | Multi-step reasoning beyond local models | 2–4 seconds |
| Advanced image understanding | Sophisticated vision-language tasks | 2–4 seconds |
| Extended conversations | Longer context retention required | 3–5 seconds |
| Complex summarization | Documents too large for local processing | 2–4 seconds |
These requests represent roughly 1% of Apple Intelligence traffic—the exception, not the rule. But for that 1%, PCC provides cloud-scale compute with device-grade privacy.
Comparison to Traditional Cloud AI #
| Aspect | Traditional Cloud AI | Private Cloud Compute |
|---|---|---|
| Hardware | Generic server GPUs/TPUs | Custom Apple silicon |
| Data access | Provider staff may have access | Cryptographically inaccessible |
| Data retention | Often retained; varies by policy | Technically impossible to retain |
| Training use | May be used for model improvement | Explicitly prohibited |
| Transparency | Closed-source infrastructure | Publicly inspectable images |
| Verification | Trust-based (privacy policies) | Cryptographic attestation |
| Admin access | SREs can access during incidents | No privileged runtime access |
PCC represents a new category: cloud-scale AI compute with verifiable privacy. For industries requiring both capability and confidentiality—healthcare, legal, finance, government—this architecture opens possibilities that were previously blocked by cloud privacy concerns.
Tier 3: ChatGPT Integration #
ChatGPT serves as the third tier—an optional, permission-based external integration powered by GPT-4o that Apple Intelligence invokes only for specialized knowledge queries, creative tasks, and complex reasoning beyond local and cloud capabilities.
This week Apple announced a landmark partnership with OpenAI to integrate ChatGPT directly into iOS 18, iPadOS 18, and macOS Sequoia—but with a crucial distinction: unlike competitors who've made external AI their primary engine, Apple treats ChatGPT as an optional specialist, not the foundation.
The integration reflects Apple's strategic positioning: they built their own AI stack for the 99% of daily tasks, and bring in GPT-4o only for the edge cases requiring deep world knowledge, creative expertise, or complex reasoning that even Private Cloud Compute can't handle.
The Partnership Structure #
Apple and OpenAI announced the integration at WWDC 2024 with specific technical and privacy terms:
- Model: GPT-4o, OpenAI's flagship multimodal model (released May 2024)
- Integration points: Siri, system-wide Writing Tools, and across Apple apps
- Privacy terms: Requests are not stored by OpenAI; IP addresses are obscured
- Availability: Later in 2024 (no specific date committed at announcement)
- Cost: Free access without requiring a ChatGPT or OpenAI account
| Access Level | Requirements | Features |
|---|---|---|
| Free tier | No account needed | GPT-4o core capabilities, standard rate limits |
| Subscriber tier | ChatGPT Plus account | Premium features, higher rate limits, conversation history |
The Opt-In Architecture #
The most important aspect of ChatGPT integration is its opt-in design. Unlike systems where external AI operates by default, Apple Intelligence requires explicit user permission for every ChatGPT interaction:
Step 1: Permission Prompt
When Siri or Writing Tools determine that ChatGPT would serve a request better than local or PCC processing, the system displays an explicit permission dialog explaining that ChatGPT will handle the request. This is per-query opt-in, not blanket authorization.
Step 2: Context Sharing (If Permitted)
If you grant permission, the system can share relevant context—photos, documents, selected text—along with your query. This enables rich multimodal interactions impossible with text-only interfaces.
Step 3: Anonymous Processing
Requests sent to ChatGPT from Apple Intelligence have IP addresses obscured and are explicitly not stored by OpenAI or used for model training, according to the partnership terms announced this week.
Step 4: Response Integration
ChatGPT responses appear through native Apple interfaces—Siri's glowing border, Writing Tools panels—with clear attribution that the response came from ChatGPT. Users can continue the conversation or return to Apple Intelligence.
When ChatGPT Gets Invoked #
| Task Category | Primary Handler | When ChatGPT Gets Invoked |
|---|---|---|
| Personal context (contacts, calendars, photos) | Apple Intelligence (on-device) | Never—private data stays local |
| Text rewriting, proofreading | Apple Intelligence (on-device) | Only for specialized creative writing |
| Siri commands and basic queries | Apple Intelligence (on-device/PCC) | For complex knowledge questions |
| Image generation (Genmoji, Playground) | Apple Intelligence (on-device) | Not applicable—Apple handles natively |
| Notification summaries | Apple Intelligence (on-device) | Never |
| Recipe suggestions | ChatGPT (with permission) | When user asks Siri for recipes |
| Creative writing assistance | ChatGPT (with permission) | When user requests creative help |
| Deep domain expertise | ChatGPT (with permission) | When query requires broad knowledge |
| Complex reasoning | ChatGPT (with permission) | Multi-step analysis beyond local/PCC |
Privacy Protections #
Even when using ChatGPT, Apple negotiated privacy terms that exceed standard OpenAI API usage:
- No request storage — OpenAI does not store requests from Apple Intelligence users
- No training use — Requests are not used to train or improve OpenAI's models
- IP obfuscation — Source IP addresses are hidden from OpenAI
- Explicit consent — Every interaction requires user permission
However, ChatGPT integration operates under OpenAI's privacy terms, not Apple's. This is a clear boundary: Tier 1 and Tier 2 offer Apple's privacy guarantees; Tier 3 offers negotiated third-party terms with explicit user awareness.
Why This Architecture Matters #
Apple's positioning of ChatGPT as an optional external component rather than the core AI engine represents a strategic bet on differentiation. While competitors have deepened reliance on cloud AI providers, Apple maintains that most daily AI tasks should happen privately on-device.
For users, this means:
- Default privacy: Most AI interactions never leave your device
- No lock-in: You're not forced into OpenAI's ecosystem
- Flexibility: Access GPT-4o when appropriate without installing separate apps
- Clarity: Clear attribution of which system handles each request
For OpenAI, this means:
- Massive distribution to Apple's user base (hundreds of millions of devices)
- Integration at the OS level rather than app level
- A pathway to convert free users to ChatGPT Plus subscribers
The partnership is notable for what it isn't: Apple didn't buy exclusive access, acquire OpenAI equity, or attempt to build their own GPT-4 class model. Instead, they built an architecture where they control the foundation and rent the specialist capability—a pragmatic approach that gets them to market faster while preserving their privacy-first positioning.
How Apple Decides Which Tier to Use #
Apple Intelligence uses an intelligent routing layer that automatically determines which tier handles each request based on complexity, privacy requirements, and capability needs—users never manually select the processing tier.
The magic of Apple's three-tier architecture isn't just that the tiers exist—it's that the system intelligently routes requests without burdening users with architectural decisions. When you interact with Apple Intelligence, you don't choose "use on-device" or "use cloud." The system makes that determination based on a decision framework Apple detailed this week.
The Decision Flowchart #
┌─────────────────────────────────────────────────────────────────────────┐
│ Apple Intelligence Routing Logic │
├─────────────────────────────────────────────────────────────────────────┤
│ │
│ USER REQUEST │
│ │ │
│ ▼ │
│ ┌─────────────────────┐ │
│ │ Can this be handled │ │
│ │ on-device? │ │
│ │ • Within context │ │
│ │ limits │ │
│ │ • Task type in │ │
│ │ local model scope │ │
│ │ • Device has │ │
│ │ capacity │ │
│ └─────────────────────┘ │
│ │ │
│ YES │ NO │
│ ▼ ▼ │
│ ┌─────────────┐ ┌─────────────────────────┐ │
│ │ TIER 1 │ │ Does this involve │ │
│ │ ON-DEVICE │ │ sensitive personal │ │
│ │ PROCESSING │ │ context that should │ │
│ │ │ │ stay local? │ │
│ │ Instant │ └─────────────────────────┘ │
│ │ response │ │ │
│ │ Zero data │ YES │ │
│ │ transmission│ ▼ │
│ └─────────────┐ ┌─────────────────────────┐ │
│ │ │ Can complex analysis │ │
│ │ │ be done on-device? │ │
│ │ │ • Document size │ │
│ │ │ • Reasoning depth │ │
│ │ │ • Task complexity │ │
│ │ └─────────────────────────┘ │
│ │ │ │
│ │ YES │ NO │
│ │ │ │ │
│ │ ▼ ▼ │
│ │ ┌────────────┐ ┌──────────────┐ │
│ │ │ Attempt │ │ TIER 2 │ │
│ │ │ on-device │ │ PRIVATE │ │
│ │ │ with │ │ CLOUD │ │
│ │ │ graceful │ │ COMPUTE │ │
│ │ │ fallback │ │ │ │
│ │ │ to Tier 2 │ │ Encrypted │ │
│ │ │ if needed │ │ transmission │ │
│ │ └────────────┘ │ Cryptographic│ │
│ │ │ privacy │ │
│ │ └──────────────┘ │
│ │ │ │
│ │ ▼ │
│ │ ┌──────────────┐ │
│ │ │ Still beyond │ │
│ │ │ capabilities │ │
│ │ │ OR requires │ │
│ │ │ deep world │ │
│ │ │ knowledge? │ │
│ │ └──────────────┘ │
│ │ │ │
│ │ YES │ │
│ │ ▼ │
│ │ ┌──────────────┐ │
│ │ │ Request user │ │
│ │ │ permission │ │
│ │ │ for ChatGPT │ │
│ │ └──────────────┘ │
│ │ │ │
│ │ GRANTED│REFUSED│
│ │ │ │ │
│ │ ▼ ▼ │
│ │ ┌──────────────┐ │
│ └──────────────────────────────────────────►│ TIER 3 │ │
│ │ CHATGPT │ │
│ │ (GPT-4o) │ │
│ │ │ │
│ │ External │ │
│ │ processing │ │
│ │ Opt-in only │ │
│ └──────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────────────┘Routing Criteria #
Apple Intelligence evaluates several factors when routing requests:
1. Task Type Classification
The system categorizes requests based on what type of processing they require:
| Category | Typical Tier | Routing Logic |
|---|---|---|
| Text transformation | On-device | Rewriting, proofing, summarizing handled locally |
| Short context Q&A | On-device | Personal queries about your data stay local |
| Image generation | On-device | Genmoji, Image Playground run on Neural Engine |
| Long document analysis | Private Cloud | Context exceeds on-device limits |
| Complex reasoning | Private Cloud | Multi-step logic beyond local models |
| Creative writing | ChatGPT | Domain expertise requiring GPT-4o |
| Broad knowledge | ChatGPT | World facts, explanations, expertise |
2. Privacy Requirements
Some requests are hardcoded to stay on-device regardless of complexity:
- Requests involving personal photos, messages, or contacts
- Queries about calendar events, emails, or location history
- Tasks requiring on-screen content awareness
- Anything involving biometric or health data
These privacy-sensitive categories attempt on-device processing first, then may gracefully degrade (offer partial results) rather than automatically escalate to cloud.
3. Context Window Analysis
Each tier has different context limits:
| Tier | Approximate Context | Implication |
|---|---|---|
| On-device | Thousands of tokens | Short documents, single messages |
| Private Cloud | Larger context | Long documents, extended conversations |
| ChatGPT | Full GPT-4o context | Very long documents, complex multi-turn |
The system estimates token count and routes accordingly.
4. Network Availability
The routing layer considers connectivity:
- No network — Only on-device features available; cloud-dependent requests queue or offer local alternatives
- Limited network — Prefers on-device; may show degraded experience rather than slow cloud calls
- Full connectivity — Full three-tier stack available
User Experience of Routing #
The routing happens transparently. Users experience it as:
- Instant responses (Tier 1) — Writing Tools suggestions appear immediately; no loading indicators
- Brief processing (Tier 2) — Complex Siri queries show the glowing border animation for 2–4 seconds
- Permission request (Tier 3) — Dialog appears: "Siri can use ChatGPT to answer this. Your information won't be stored. Allow?"
Apple's goal is that most interactions feel instantaneous—evidence of Tier 1 handling the load—while users are explicitly aware when data leaves their device for external processing.
What This Means for Consistency #
Because the same request might route differently depending on device capability, network status, and content size, Apple Intelligence is designed with graceful degradation:
- Features work (at some level) across all tiers
- On-device results may be simpler but still useful
- The system can offer alternatives: "I can answer this with on-device processing, or use ChatGPT for a more detailed response. Which would you prefer?"
This flexibility ensures Apple Intelligence features are available to the maximum extent possible given current conditions, rather than failing hard when the preferred tier is unavailable.
Privacy at Every Layer #
Privacy is architected into every tier: on-device processing keeps data local, Private Cloud Compute uses cryptographic attestation to ensure ephemeral processing, and ChatGPT integration requires explicit opt-in per request with anonymized data handling.
Privacy isn't an afterthought in Apple Intelligence—it's the organizing principle that determined the three-tier architecture. Apple built this system to answer a specific question: "How do we deliver capable AI while keeping the privacy guarantees our users expect from our devices?" The answer is tiered processing, with privacy guarantees escalating alongside capability needs.
The Privacy Spectrum #
┌─────────────────────────────────────────────────────────────────────────┐
│ Apple Intelligence Privacy Spectrum │
├─────────────────────────────────────────────────────────────────────────┤
│ │
│ MAXIMUM PRIVACY VERIFIABLE PRIVACY MANAGED │
│ (Cryptographic) PRIVACY │
│ │
│ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ │
│ │
│ TIER 1 TIER 2 TIER 3 │
│ On-Device Private Cloud ChatGPT │
│ │
│ • Data never leaves device • Cryptographic • Opt-in │
│ • No network transmission attestation per use │
│ • Impossible to intercept • No data storage • OpenAI │
│ • No logging possible • No Apple access terms │
│ • Ephemeral apply │
│ processing • IP │
│ • Publicly obscured │
│ inspectable • No │
│ storage │
│ │
│ Coverage: ~99% of requests Coverage: ~1% Rare use │
│ │
└─────────────────────────────────────────────────────────────────────────┘Tier 1 Privacy: Architectural Impossibility of Exfiltration #
On-device processing offers the strongest privacy guarantee: architectural impossibility of data transmission. Your prompts, context, and generated outputs never leave your device's memory. There's nothing to intercept, no server to compromise, no database to leak.
This isn't a policy promise—it's enforced by physics. The Neural Engine processes data in the same secure enclave that handles Face ID and Touch ID authentication. There's no network interface involved, no API keys to expose, no third-party infrastructure.
Privacy guarantees at Tier 1:
| Aspect | Guarantee |
|---|---|
| Data transmission | None—processing happens entirely locally |
| Data storage | Temporary; cleared after task completion |
| Apple access | Impossible; Apple has no interface to device memory |
| Third-party access | None; no external services involved |
| Offline capability | Full functionality without network |
Tier 2 Privacy: Cryptographic Verifiability #
Private Cloud Compute introduces a new privacy model: verifiable trust through cryptography. Rather than asking users to trust Apple's privacy policy, PCC provides technical guarantees that can be independently verified.
The cryptographic attestation flow ensures:
- Targeted encryption — Your device encrypts requests only to verified PCC nodes, not to Apple broadly
- Attestation verification — Your device confirms the server runs publicly listed software before transmitting
- Ephemeral processing — Data exists in decrypted form only during processing, then is cryptographically erased
- No privileged access — Even Apple SREs cannot access your data; the system has no admin interfaces
Privacy guarantees at Tier 2:
| Aspect | Guarantee |
|---|---|
| Data transmission | End-to-end encrypted to verified nodes only |
| Data storage | Explicitly prohibited by architecture |
| Apple access | Cryptographically impossible |
| Third-party access | PCC infrastructure is Apple-only; no external providers |
| Verifiability | Publicly inspectable software images and transparency log |
Apple's transparency commitment for PCC is unprecedented: every production software image published for security research, measurements logged publicly, and a virtual research environment for independent verification. This is designed to be the most auditable cloud AI infrastructure ever deployed.
Tier 3 Privacy: Negotiated Terms with Explicit Consent #
ChatGPT integration operates under a different model: managed privacy with explicit opt-in. When you choose to send a request to ChatGPT, you're making an informed decision to operate under OpenAI's privacy terms—with specific protections negotiated by Apple:
| Aspect | Guarantee |
|---|---|
| Data transmission | Only after explicit user permission |
| Data storage | OpenAI does not store Apple Intelligence requests |
| Training use | Prohibited; requests not used for model improvement |
| Apple access | Not applicable (data goes to OpenAI) |
| Third-party access | OpenAI receives request data but not user identity |
| IP address | Obscured through relay infrastructure |
The key distinction: Tier 3 is always opt-in. Your device won't send data to ChatGPT without showing a permission dialog. This isn't a preference setting you enable once—it's per-request consent that keeps users aware of when external processing occurs.
Comparing Privacy Models #
| Provider | Primary Model | Data Retention | Training Use | Verifiability |
|---|---|---|---|---|
| Apple Intelligence (Tier 1) | On-device | None | Never | Hardware-enforced |
| Apple Intelligence (Tier 2) | Purpose-built cloud | Cryptographically prevented | Never | Cryptographic attestation + public inspection |
| Apple Intelligence (Tier 3) | External (ChatGPT) | Not stored (per agreement) | Never (per agreement) | Contractual + opt-in consent |
| Standard OpenAI API | Cloud | Varies by API tier | Possible | Terms of service |
| Google Gemini | Cloud | Per Google privacy policy | Possible | Terms of service |
| Standard cloud AI | Cloud | Provider-dependent | Provider-dependent | Trust-based |
Privacy for Sensitive Use Cases #
The three-tier architecture enables AI capabilities for domains previously blocked by privacy concerns:
Healthcare — Doctors can use Writing Tools to refine patient notes on-device, knowing no PHI leaves the device. Complex medical research queries might escalate to PCC (with cryptographic privacy) but never to ChatGPT without explicit consent.
Legal — Attorneys can summarize confidential documents on-device. Discovery materials stay local. Only general legal research queries go to external sources—and only when explicitly permitted.
Finance — Traders can draft sensitive communications using on-device processing. Account numbers, positions, and strategies never touch cloud infrastructure.
Government/Enterprise — Organizations with strict data handling requirements can configure Apple Intelligence to operate in Tier 1 and Tier 2 only, with Tier 3 disabled via MDM policies.
The Privacy Transparency Dashboard #
Apple Intelligence includes a privacy dashboard showing users:
- Which tier processed recent requests
- How many requests stayed on-device vs. went to cloud
- When ChatGPT was invoked and with what permissions
- Options to disable specific tiers or require approval for escalations
This transparency is designed to build trust through visibility—users see exactly how their data flows through the system.
Why This Privacy Architecture Matters #
Apple's three-tier privacy model represents a strategic bet: users will choose privacy-default AI over capability-first AI when the privacy option is good enough for daily use. By making on-device processing capable of handling 99% of requests, Apple ensures most AI interactions have maximum privacy. By making cloud privacy verifiable rather than trust-based, they address the enterprise and sensitive-use markets. By making external AI opt-in, they maintain user agency over data sharing.
This is the first mainstream AI system architected privacy-first rather than privacy-as-an-afterthought—and it's a model competitors will be pressured to match.
Device Requirements #
Apple Intelligence's three-tier architecture requires specific hardware: iPhone 15 Pro and Pro Max with the A17 Pro chip deliver 35 TOPS Neural Engine performance for on-device inference, while iPad and Mac need M1 or newer processors.
The three-tier architecture isn't just a software innovation—it depends on specific hardware capabilities that only recent Apple devices provide. Apple announced aggressive hardware requirements this week: Apple Intelligence will only run on devices with the Neural Engine performance and memory architecture to handle foundation models locally.
iPhone Requirements #
Apple Intelligence on iPhone is limited to just two models announced last fall:
| Device | Chip | Neural Engine | Apple Intelligence |
|---|---|---|---|
| iPhone 15 Pro | A17 Pro | 16-core, 35 TOPS | ✅ Full support |
| iPhone 15 Pro Max | A17 Pro | 16-core, 35 TOPS | ✅ Full support |
| iPhone 15 | A16 Bionic | 16-core, 17 TOPS | ❌ Not supported |
| iPhone 15 Plus | A16 Bionic | 16-core, 17 TOPS | ❌ Not supported |
| iPhone 14 series | A16/A15 | 16-core, 15-17 TOPS | ❌ Not supported |
| iPhone 13 series | A15 Bionic | 16-core, 15.8 TOPS | ❌ Not supported |
| iPhone SE (3rd gen) | A15 Bionic | 16-core, 15.8 TOPS | ❌ Not supported |
| All earlier iPhones | Various | Various | ❌ Not supported |
The cutoff is sharp and hardware-driven. iPhone 15 and 15 Plus, released alongside the Pro models in 2023, are excluded—not because of a software gate, but because the A16 Bionic's 17 TOPS Neural Engine cannot deliver usable performance for on-device foundation models.
John Giannandrea, Apple's Senior Vice President of Machine Learning and AI Strategy, explained this week: "While older chips could theoretically run Apple Intelligence models, it would be so slow it would not be useful. The A17 Pro delivers the performance threshold where AI features feel instant rather than frustrating."
iPad Requirements #
iPad compatibility follows a similar pattern, requiring M-series processors:
Supported iPads:
- iPad Pro 12.9-inch (M1, M2, M4)
- iPad Pro 11-inch (M1, M2, M4)
- iPad Air (M1, M2)
Not Supported:
- iPad mini (A-series chips only)
- Standard iPad (10th generation and earlier with A-series)
The M-series chips provide the unified memory architecture and Neural Engine performance necessary for foundation model inference. A-series iPad chips, even the powerful ones in iPad mini, lack the sustained performance characteristics that Apple Intelligence requires.
Mac Requirements #
All Apple silicon Macs support Apple Intelligence—a broader compatibility base than iPhone because the Mac transition to Apple silicon started earlier and has deeper penetration:
Supported Macs:
- MacBook Air (M1, M2, M3)
- MacBook Pro (M1, M2, M3, M3 Pro, M3 Max)
- Mac mini (M1, M2, M2 Pro)
- iMac (M1, M3)
- Mac Studio (M1 Max, M1 Ultra, M2 Ultra)
- Mac Pro (M2 Ultra)
Not Supported:
- All Intel-based Macs (even high-end configurations with discrete GPUs)
The Neural Engine in Apple silicon is essential for on-device AI processing. Intel Macs, regardless of CPU performance or GPU configuration, cannot run Apple Intelligence because they lack the dedicated neural processing hardware.
Why the Requirements Are Strict #
Running foundation models locally demands three resources in abundance:
1. Neural Engine TOPS (Tera Operations Per Second)
Foundation model inference is essentially massive matrix multiplication. The A17 Pro's 35 TOPS provides the throughput for instant responses. Older chips at 15-17 TOPS would deliver responses in seconds rather than milliseconds—unusable for real-time features like Smart Reply or notification summaries.
Neural Engine Performance Comparison:
A17 Pro ████████████████████████████████████ 35 TOPS ✅
A16 Bionic █████████████████ 17 TOPS ❌
M1/M2 ██████████████████ 11-18 TOPS ✅
M3 ████████████████████ 18 TOPS ✅2. Memory Bandwidth
Foundation models require moving massive amounts of data between memory and processing units rapidly. Apple silicon's unified memory architecture provides memory bandwidth measured in hundreds of gigabytes per second—far exceeding traditional CPU/GPU separated memory pools.
| Chip | Memory Bandwidth | Impact on AI |
|---|---|---|
| A17 Pro | ~51 GB/s | Sustained inference without bottleneck |
| A16 Bionic | ~34 GB/s | Insufficient for smooth LLM inference |
| M3 | ~100 GB/s | Excellent for large model inference |
| M3 Pro | ~150 GB/s | Professional AI workloads |
| M3 Max | ~400 GB/s | Maximum AI performance |
3. RAM Capacity
All Apple Intelligence-compatible devices have at least 8GB of RAM. Loading foundation models, even compressed and quantized versions, requires several gigabytes of memory. With iOS/macOS consuming several GB for system operations, 8GB is the minimum to load models while leaving room for apps.
Implications for Users #
If you want Apple Intelligence on iPhone:
- You need an iPhone 15 Pro or Pro Max
- Standard iPhone 15 or any earlier iPhone won't work
- This represents a significant upgrade incentive
If you want Apple Intelligence on iPad:
- You need an M-series iPad Pro or iPad Air
- Standard iPad or iPad mini won't work
- The cheapest compatible iPad is the iPad Air M1 (~$600)
If you want Apple Intelligence on Mac:
- Any Apple silicon Mac works
- Intel Macs are excluded, regardless of specs
- The cheapest compatible Mac is the M1 Mac mini (~$600) or M1 MacBook Air (discontinued but available refurbished)
The Installed Base Reality #
The hardware requirements mean Apple Intelligence will have limited reach initially:
- iPhone: Only the ~15-20% of users with Pro models from the past year
- iPad: M-series iPads represent a smaller percentage of the installed base
- Mac: Apple silicon Macs are now the majority of active Macs
This is a calculated trade-off. Apple prioritized user experience—ensuring Apple Intelligence feels fast and responsive—over market reach. As users upgrade devices over the next 2-3 years, the addressable market expands.
Developer Implications #
Developers building Apple Intelligence features must account for hardware fragmentation:
import AppleIntelligence
// Check if Apple Intelligence is available on this device
if AppleIntelligence.isAvailable {
// Enable AI-powered features
enableWritingTools()
enableSmartReply()
} else {
// Graceful degradation: disable or provide alternative
showStandardInterface()
}Apps must gracefully degrade on unsupported devices. Apple Intelligence APIs report availability, allowing developers to conditionally enable features or provide fallback experiences.
This fragmentation is temporary but real. For the next 12-18 months, most iOS users won't have Apple Intelligence. Developers need to decide whether to build Apple Intelligence as a premium enhancement or maintain feature parity across all devices using alternative approaches.
Comparison: Apple vs Google vs Samsung #
Apple's three-tier approach differs fundamentally from competitors: Google routes most AI through Gemini in the cloud, Samsung relies on a mix of on-device and Google Cloud processing, while Apple's architecture prioritizes on-device processing with verifiable cloud privacy.
What This Means for Developers #
Developers building for Apple Intelligence gain access to on-device AI through the App Intents framework, Image Playground API, and Writing Tools—enabling privacy-first AI features without cloud API dependencies or ongoing inference costs.
The Long Game: Why This Architecture Matters #
Apple's three-tier architecture represents a strategic bet that the future of AI is distributed rather than centralized—with most computation happening locally and cloud resources reserved for exceptional cases, fundamentally shifting the economics and privacy model of intelligent systems.
FAQ: Apple Three-Tier AI Architecture #
What is Apple's three-tier AI architecture? #
How does on-device AI processing work in Apple Intelligence? #
What is Private Cloud Compute and how is it different from regular cloud AI? #
When does Apple Intelligence use ChatGPT instead of local processing? #
How does Apple decide which tier processes my request? #
Is Apple Intelligence completely private? #
What devices support Apple Intelligence's three-tier architecture? #
Can Apple Intelligence work without an internet connection? #
How does Apple's AI architecture compare to Google's? #
Will developers be able to use Private Cloud Compute directly? #
What happens to my data in Private Cloud Compute? #
Is ChatGPT integration required for Apple Intelligence? #
The Bottom Line #
[CTA for "both" service track to be added in final assembly]
Related Reading #
- Apple Intelligence Unveiled at WWDC 2024: Everything You Need to Know
- Apple Intelligence Rumors: What We Expected Before WWDC 2024
- The MCP Architecture Guide: How Model Context Protocol Actually Works
— William Spurlock, June 14, 2024
Related Posts

Google I/O 2026 Action List: How I Prompted Gemini 3.5 Flash and Antigravity Workflows
Google I/O 2026 just reset the AI tooling landscape. Here's the 9-action checklist for builders who want to ship this week, not just watch the keynote.

Anthropic vs. OpenAI vs. Google: The State of the Frontier in May 2026
A head-to-head breakdown of the three AI giants in May 2026: Claude Opus 4.6, GPT-5.3 and 5.4, Gemini 3.1 Pro. Real specs, real pricing, and what actually matters for builders.

Kimi K2 Open Weights: How I Prompted Moonshot's Frontier Model for Agentic Tool Use
How I direct Kimi K2 by Moonshot AI for agentic workflows, long-context tool calling, and workflow automation. A 1 trillion parameter MoE model with competitive benchmarks at 5-17x lower cost than GPT-5 and Claude.




