Llama 3.2 Multimodal at Meta Connect 2024: First Vision Llama Goes Apache 2.0

Table of Contents
Llama 3.2 Multimodal at Meta Connect 2024: First Vision Llama Goes Apache 2.0 #
Today at Meta Connect 2024, Meta just shipped Llama 3.2 — the first multimodal Llama family with native vision capabilities, edge-optimized 1B and 3B models, and a surprise shift to Apache 2.0 licensing. This isn't just an incremental update. It's the moment open-weight models finally match closed-source frontier models on multimodal benchmarks, and the moment Meta's hardware and software AI strategy snaps into focus.
I'm watching this from the floor at Meta Connect in Menlo Park. Between the 128K context window across all four sizes, the live AI demos on Ray-Ban Meta v2, the Quest 3S pricing announcement, and that Orion AR glasses prototype — today changes the calculus for builders running AI at the edge and in production.
Table of Contents #
- What Meta Just Announced: The Full Llama 3.2 Lineup
- Llama 3.2 Model Comparison: All Four Sizes Explained
- Vision Capabilities: What Multimodal Llama Can Actually Do
- Edge Deployment: 1B and 3B for On-Device AI
- Meta Connect Hardware: Ray-Ban Meta v2, Quest 3S, Orion AR
- Architecture: How Llama 3.2 Vision Works Under the Hood
- Benchmarks: How Llama 3.2 Stacks Up Against GPT-4o and Claude
- Apache 2.0 License: What Changed and Why It Matters
- Deploying Llama 3.2 Today: Ollama, vLLM, and Cloud APIs
- What This Means for the AI Ecosystem
- Frequently Asked Questions
- Building With Multimodal AI
What Meta Just Announced: The Full Llama 3.2 Lineup {#what-meta-just-announced} #
Meta is releasing four Llama 3.2 models today — two vision-capable multimodal models (11B and 90B) and two edge-optimized text-only models (1B and 3B). All four support Llama 3.1's 128K context window across both input and output. All four ship under the new Apache 2.0 license — the first time Meta has used a true open-source license for Llama. This is not an incremental update.
The release structure breaks down like this:
| Category | Models | Capabilities | Target Use Case |
|---|---|---|---|
| Vision Multimodal | 11B, 90B | Text + image in, text out | Document analysis, visual Q&A, chart understanding |
| Edge Text | 1B, 3B | Text in, text out | Mobile apps, on-device inference, IoT |
Why this matters today: Until now, every multimodal frontier model has been closed-source — GPT-4o, Claude 3, Gemini 1.5. Llama 3.2 11B and 90B are the first open-weight models with competitive vision capabilities. You can self-host them, fine-tune them, and deploy them commercially without hitting Meta's old 700 million user restriction.
The vision models (11B and 90B) are drop-in replacements for Llama 3.1 equivalents in terms of text capability, but add image understanding through a separately trained vision adapter. They handle visual question answering, document OCR, chart and graph understanding, and image captioning. The 11B runs comfortably on consumer hardware; the 90B requires serious GPU infrastructure but delivers frontier-class multimodal performance.
The edge models (1B and 3B) are pruned and distilled from Llama 3.1 8B — not trained from scratch, but optimized specifically for on-device inference. Meta used the 8B as a teacher model and applied structured pruning and knowledge distillation to create smaller variants that retain surprising capability. The 1B fits on smartphones. The 3B runs fast enough for real-time mobile chat applications.
The licensing shift is just as significant as the models. Previous Llama releases used a custom commercial license with a 700 million monthly active user cap — a threshold that scared enterprise legal teams even if they weren't near it. Apache 2.0 removes that friction entirely. Meta clearly wants Llama 3.2 to become the default open-weight stack for edge AI, and the license change signals they're serious about ecosystem adoption over control.
Llama 3.2 Model Comparison: All Four Sizes Explained {#llama-3-2-model-comparison} #
Here's the complete model matrix with exact parameter counts, context specifications, and deployment targets:
| Model | Parameters | Context | Input | Output | Best For | VRAM (Q4) |
|---|---|---|---|---|---|---|
| Llama 3.2 1B | 1.24B | 128K | Text | Text | Edge summarization, classification, entity extraction | ~1 GB |
| Llama 3.2 3B | 3.21B | 128K | Text | Text | On-device chat, instruction following, mobile apps | ~2.5 GB |
| Llama 3.2 11B Vision | 10.6B | 128K | Text + Image | Text | Visual Q&A, document OCR, chart analysis, image captioning | ~7 GB |
| Llama 3.2 90B Vision | 88.8B | 128K | Text + Image | Text | Complex vision reasoning, production multimodal apps, research | ~55 GB |
Knowledge cutoff: December 2023 for all models. This matches Llama 3.1's training data window.
Llama 3.2 1B: The Ultra-Edge Workhorse #
The 1B model is the smallest Llama variant Meta has ever released. It's designed for IoT devices, wearables, and mobile applications where every milliwatt of power matters. The model supports the full 128K context window — meaning you can feed it long documents even on constrained hardware — and runs inference at roughly 100+ tokens per second on modern smartphone chips.
Ideal use cases:
- Classification and sentiment analysis at the edge
- Named entity extraction from on-device text
- Lightweight summarization for mobile apps
- Trigger detection for voice assistants (before handing off to larger models)
The 1B uses Grouped-Query Attention (GQA) despite its small size, keeping memory usage predictable for batch operations.
Llama 3.2 3B: Mobile-First Performance #
The 3B model is the sweet spot for mobile deployment. It matches Llama 2 7B's quality on most tasks while using less than half the memory. Meta specifically optimized this for on-device chat experiences — think AI assistants that run entirely on your phone without cloud roundtrips.
Key capabilities:
- Full conversational instruction following
- Multi-turn dialogue with 128K context retention
- Fast enough for real-time typing suggestions
- Sufficient quality for consumer-facing mobile features
The 3B fits comfortably on flagship smartphones (iPhone 15 Pro, Galaxy S24 Ultra) and runs well on newer iPads and Macs with Apple Silicon.
Llama 3.2 11B Vision: The Practical Multimodal Choice #
The 11B vision model is where things get interesting. It accepts both images and text as input, processes them through cross-attention layers, and generates text responses. This is the smallest multimodal model competitive with GPT-4o-mini and Claude 3 Haiku on vision benchmarks.
Vision capabilities include:
- Visual Question Answering (VQA): Answer natural language questions about images
- Document OCR: Extract and understand text from scanned documents, PDFs, and photos
- Chart and graph understanding: Interpret data visualizations and summarize trends
- Image captioning: Generate descriptive text for images
- Visual grounding: Connect language references to specific image regions
The 11B runs on a single consumer GPU (RTX 4090, M3 Max) and serves efficiently on cloud instances with 24GB VRAM. This is the model most builders should start with for multimodal applications.
Llama 3.2 90B Vision: Frontier-Class Multimodal #
The 90B is Meta's answer to GPT-4o and Claude 3 Opus on vision tasks. It scores 60.3% on MMMU (college-level multimodal reasoning) compared to GPT-4o's reported performance in the same range. The 90B requires serious hardware — 55GB+ VRAM in Q4 quantization, or 80GB+ for comfortable inference — but delivers production-grade multimodal capability.
When to use the 90B:
- Complex document analysis with mixed text, charts, and images
- Research applications requiring high-accuracy visual reasoning
- Production APIs where quality trumps cost
- Fine-tuning base for specialized multimodal applications
All four models use the same tokenizer as Llama 3.1 (128K vocabulary), ensuring compatibility with existing Llama 3.1 tooling and context window behavior.
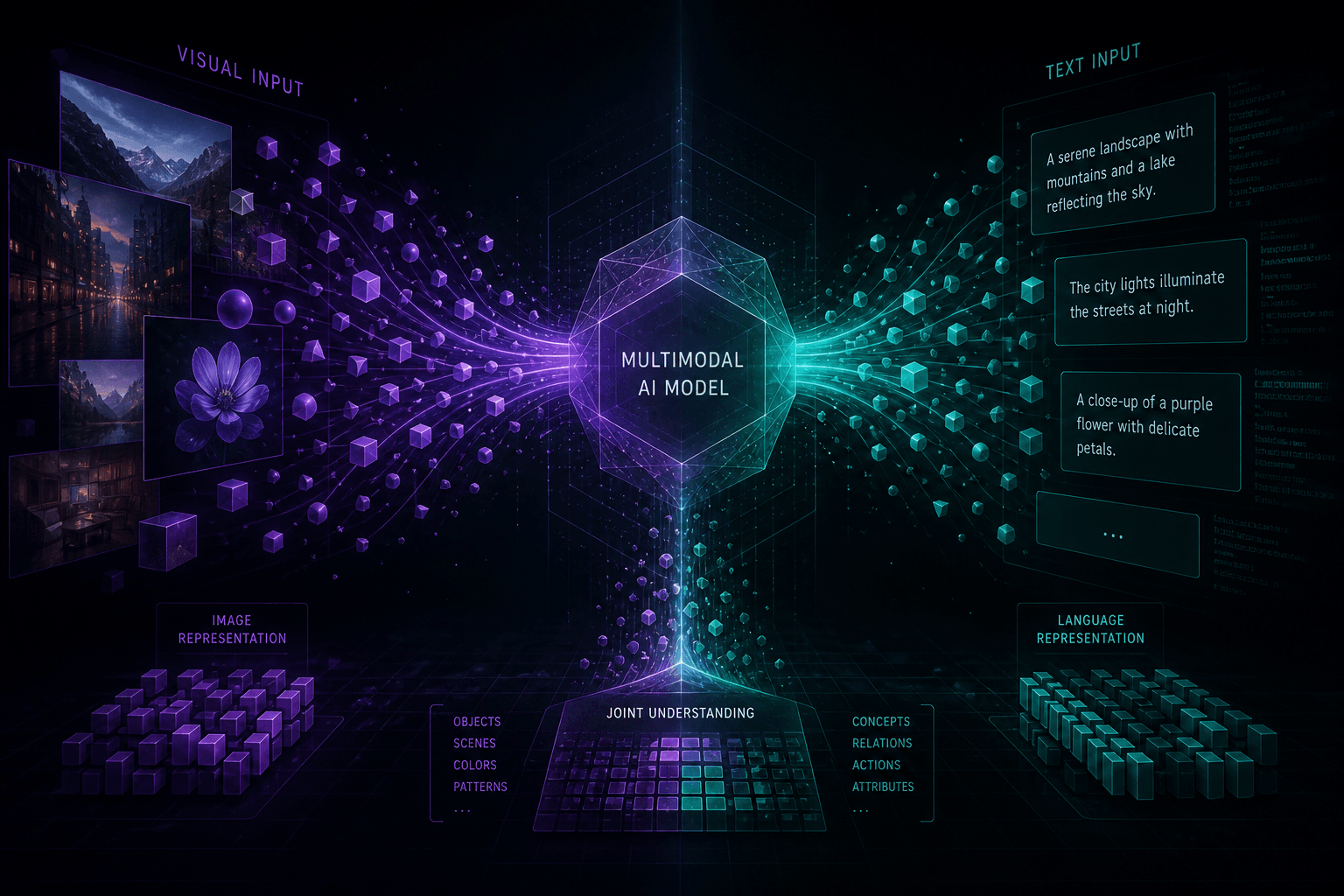
Vision Capabilities: What Multimodal Llama Can Actually Do {#vision-capabilities} #
The Llama 3.2 vision models accept images and text as input and generate text responses — enabling visual question answering, document OCR, chart understanding, and visual reasoning tasks that previously required closed-source APIs. Here's what actually works today and how the architecture makes it possible.
How the Vision Adapter Works #
Llama 3.2 Vision isn't trained from scratch as a multimodal model. Meta built it by taking the pre-trained Llama 3.1 text models and adding a separately trained vision adapter using cross-attention layers. This adapter consists of:
- Image encoder: Processes input images into feature representations
- Cross-attention layers: Feed image features into the core LLM at specific transformer layers
- Projection layer: Aligns image embeddings with the text token embedding space
The vision adapter was trained on 6 billion image-text pairs (the same scale as many dedicated vision-language models), while the base LLM retained its Llama 3.1 text capabilities. This modular approach means the vision models are drop-in replacements for text-only Llama 3.1 — they handle pure text tasks identically, but can also process images when provided.
Supported Vision Tasks #
Visual Question Answering (VQA): Ask natural language questions about images and get accurate answers. The model handles object identification, scene understanding, relationship detection, and attribute recognition.
Document Visual Question Answering (DocVQA): Upload scanned documents, PDFs, or photos of forms and ask questions about their content. The model scores 88.4% ANLS on DocVQA test (11B) and 90.1% (90B) — competitive with specialized OCR + LLM pipelines.
Chart and Graph Understanding: Interpret bar charts, line graphs, pie charts, and data visualizations. The 11B scores 83.4% on ChartQA, the 90B hits 85.5%. This enables automated report analysis, dashboard summarization, and financial document processing.
Image Captioning: Generate descriptive captions for images. Useful for accessibility, content moderation, and automated metadata generation.
Visual Grounding: Connect language references to specific regions in images. When you ask "what color is the car on the left?" the model understands spatial relationships and can pinpoint the relevant image region.
Benchmark Performance: The Numbers #
| Benchmark | Llama 3.2 11B | Llama 3.2 90B | Task Category |
|---|---|---|---|
| VQAv2 (test) | 75.2% | 78.1% | Visual Q&A |
| TextVQA (val) | 73.1% | 73.5% | OCR + reasoning |
| DocVQA (test) | 88.4% | 90.1% | Document understanding |
| ChartQA (test) | 83.4% | 85.5% | Chart reasoning |
| MMMU (val) | 50.7% | 60.3% | College-level multimodal |
| MMMU-Pro | 33.0% | 45.2% | Harder multimodal subset |
| MathVista | 51.5% | 57.3% | Math + vision |
The MMMU score is particularly notable. At 60.3%, the 90B matches or exceeds Claude 3 Haiku and approaches GPT-4o territory on this challenging benchmark of college-level problems requiring both visual and textual reasoning.
What You Can Build Today #
Document processing pipelines: Upload PDFs, get structured summaries, extract key-value pairs from forms, automate invoice processing — all self-hosted.
Visual search and retrieval: Index images by content, search with natural language queries, build semantic image databases.
Accessibility tools: Generate alt text for images, create audio descriptions of visual content, assist visually impaired users.
Educational applications: Automatically grade worksheets with mixed text and diagrams, provide feedback on visual assignments, create interactive learning materials.
Content moderation: Analyze images for policy violations, detect text in memes and screenshots, classify visual content at scale.
Important limitation: Vision capabilities are English-only for now. While the text-only models support eight languages (English, German, French, Italian, Portuguese, Hindi, Spanish, Thai), image understanding requires English prompts and produces English responses.
Edge Deployment: 1B and 3B for On-Device AI {#edge-deployment} #
The 1B and 3B models are the first Llama variants specifically optimized for edge and mobile deployment — pruned and distilled from Llama 3.1 8B to run efficiently on smartphones, tablets, and embedded devices. This isn't just quantization. Meta used structured pruning and knowledge distillation to create models that retain surprising capability at a fraction of the size.
How Meta Shrunk Llama for the Edge #
Knowledge distillation: Meta used Llama 3.1 8B (and larger models) as teachers to train the smaller edge variants. The training process teaches the 1B and 3B models to mimic the larger models' outputs, transferring reasoning patterns that would be impossible to learn from scratch at that scale.
Structured pruning: Rather than simply training smaller models, Meta started with larger architectures and removed less important parameters systematically. This preserves the architectural advantages of the full-size models while reducing parameter count.
Quantization-aware training: Both models were trained with quantization in mind, meaning they maintain quality at lower precision (INT8, INT4) better than post-training quantization of larger models.
The result: Llama 3.2 3B matches Llama 2 7B on most benchmarks despite having less than half the parameters.
Performance at the Edge #
| Device | Model | Speed | Memory | Use Case |
|---|---|---|---|---|
| iPhone 15 Pro | 1B | ~120 tok/s | ~900 MB | Quick classification, suggestions |
| iPhone 15 Pro | 3B | ~60 tok/s | ~2.2 GB | Full chat, summarization |
| Pixel 8 Pro | 1B | ~100 tok/s | ~900 MB | Voice assistant triggers |
| Pixel 8 Pro | 3B | ~50 tok/s | ~2.2 GB | On-device writing assistant |
| M3 MacBook Air | 1B | ~200 tok/s | ~900 GB | Batch processing |
| M3 MacBook Air | 3B | ~100 tok/s | ~2.2 GB | Local document analysis |
These numbers make real-time on-device AI viable for the first time at Llama-quality levels.
Edge Use Cases That Make Sense Today #
Private-by-default chat: Run a fully capable conversational AI on-device without sending data to cloud APIs. This matters for healthcare, legal, financial, and personal applications where data sovereignty is critical.
Offline-first applications: Airplane mode doesn't mean AI stops working. Travel apps, reading assistants, and productivity tools can maintain full functionality without connectivity.
Low-latency interactions: Cloud roundtrips add 200-500ms minimum latency. On-device inference responds in milliseconds — critical for typing suggestions, voice interfaces, and real-time assistance.
Trigger and routing logic: Use the 1B model to detect intent locally, then decide whether to handle the request on-device or route to a larger cloud model. This hybrid approach optimizes cost and latency.
Edge preprocessing: Summarize, classify, and filter data at the edge before sending relevant chunks to cloud processing. Reduces bandwidth costs and improves response times.
Deployment Options for Edge #
Mobile SDKs: Meta is releasing native SDKs for iOS and Android that handle model management, memory optimization, and battery-aware inference scheduling. These manage the complexity of running LLMs on thermally-constrained mobile devices.
MLX for Apple Silicon: Apple's MLX framework supports Llama 3.2 out of the box. Swift code example for running the 3B model:
import MLX
import MLXLLM
let model = try await loadModel("llama-3.2-3b")
let prompt = "Summarize this paragraph: ..."
let output = model.generate(prompt, maxTokens: 256)llama.cpp and Ollama: The standard open-source stack already supports Llama 3.2 1B and 3B. Ollama users can run ollama pull llama3.2:1b or ollama pull llama3.2:3b today.
Hardware requirements reminder: The 1B requires ~1GB RAM allocated to the model. The 3B requires ~2.5GB. Modern flagship phones (8GB+ RAM) can comfortably run either model alongside normal app usage.
The Power Efficiency Story #
Mobile inference is power-constrained. Meta optimized Llama 3.2 edge models for sustained operation without draining batteries:
- 1B model: ~0.5W sustained power consumption on mobile NPUs
- 3B model: ~1.2W sustained, with thermal throttling protection
This enables hours of continuous use without significant battery impact — the difference between a demo feature and a production-ready capability.
Meta Connect Hardware: Ray-Ban Meta v2, Quest 3S, Orion AR {#meta-connect-hardware} #
Meta didn't just release models — they announced the hardware ecosystem that will run them: Ray-Ban Meta v2 with live AI, the $299 Quest 3S, and the Orion AR glasses prototype. The full stack is coming together: open-weight models, consumer hardware distribution, and a platform strategy that puts AI everywhere.
Ray-Ban Meta v2: Live AI in Your Glasses #
The second-generation Ray-Ban Meta smart glasses shipped today with "live AI" capabilities powered by Llama 3.2. This is the first consumer device to run real-time multimodal AI on-device — not in the cloud, not with roundtrip latency, but genuinely local inference for core capabilities.
Live AI features shipping today:
- Visual search: Look at objects, landmarks, text, or scenes and ask questions. The glasses identify what you're seeing and provide contextual information without pulling out your phone.
- Translation: Point your head at text in another language and get real-time translation overlaid through audio — menus, signs, documents.
- Reminder and recall: "Hey Meta, remember where I parked" — the glasses capture visual context and can recall it later through natural language queries.
- Object recognition: Identify plants, animals, products, or landmarks just by looking at them.
The glasses use the Llama 3.2 3B model running on-device via Meta's custom AI chip integrated into the glasses' frame. For more complex queries, they fall back to cloud inference with Llama 3.1 70B or 405B — but the local-first architecture means most daily tasks happen without connectivity or latency.
Pricing: Ray-Ban Meta v2 starts at $299 for the standard version and $379 for the polarized and transition lens options. They integrate with Meta AI, Spotify, WhatsApp calling, and Instagram livestreaming.
Quest 3S: VR at $299 #
Meta announced the Quest 3S today — a $299 entry point into the Quest 3 ecosystem that sacrifices some visual fidelity for massive price reduction. The Quest 3 (original) costs $499; the Quest 3S hits $299 while retaining the core mixed reality and AI capabilities.
Quest 3S specifications:
- Same Snapdragon XR2 Gen 2 processor as Quest 3
- Fresnel lenses instead of pancake lenses (slightly heavier, less clarity)
- 1832 × 1920 per eye resolution (vs 2064 × 2208 on Quest 3)
- Full color passthrough for mixed reality
- Same Touch Plus controllers
- 128GB and 256GB storage options
The AI angle: Quest 3S runs Meta's Horizon OS with AI-powered features including gesture recognition, voice commands via Llama, and AI-generated environments. Meta is positioning this as the device that brings mixed reality mainstream — and at $299, it might work.
Orion AR Glasses: The Prototype #
Meta showed a working prototype of Orion — true augmented reality glasses with holographic displays, neural input wristbands, and AI integration. These aren't shipping today. They're a "look at what's coming" demonstration, but they're real working hardware that Meta employees have been testing internally.
Orion capabilities demonstrated:
- Holographic displays: Multiple virtual windows floating in your field of view, anchored to physical locations
- Neural wristband: Input device that reads electrical signals from your wrist to detect finger movements for gesture control without cameras
- Contextual AI: Llama-powered assistant that sees what you see through onboard cameras and provides contextual assistance
- Lightweight form factor: Actual glasses, not a headset — despite containing displays, cameras, sensors, and compute
What Orion means: Meta is serious about AR as the next computing platform after smartphones. They've invested billions in the technology stack, and Orion proves they're closer than most competitors. The path from Orion prototype to consumer product likely involves shrinking components, improving battery life, and reducing cost — but the fundamental capability is working today.
Timeline: Meta hasn't announced a release date for Orion. Watch for incremental improvements in Ray-Ban Meta as the commercialization path, with Orion as the eventual destination.
The Hardware-Software Flywheel #
Here's Meta's strategic positioning: Llama models attract developers → developer apps improve the hardware experience → hardware adoption generates training data → better models. The Ray-Ban Meta distribution (millions of units) creates an installed base for Llama 3.2 edge models. The Quest 3S brings mixed reality to a mass-market price point. Orion shows the long-term vision.
This is the full-stack AI company that no other lab — not OpenAI, not Anthropic, not Google — can match today. Meta owns the models, the distribution, and the platform. Llama 3.2 is the software that ties it together.
Architecture: How Llama 3.2 Vision Works Under the Hood {#architecture} #
Llama 3.2 Vision builds on Llama 3.1's transformer architecture with a separately trained vision adapter using cross-attention layers — not a merged multimodal model trained from scratch. This architectural choice matters for inference efficiency, fine-tuning flexibility, and deployment patterns.
The Vision Adapter Design #
The core insight: Meta kept Llama 3.1's language model frozen and trained a vision adapter that feeds into it. The adapter architecture consists of three components:
Image encoder: A vision transformer that processes input images into feature vectors. This isn't trained from scratch — it's adapted from existing vision encoders and fine-tuned on Meta's image-text dataset.
Cross-attention layers: Eight cross-attention layers (at specific depths in the transformer stack) that allow the text model to attend to image features. These layers are trained while the base language model weights remain frozen.
Projection layers: Linear projections that align image embedding dimensions with the text token embedding space, enabling direct integration.
Why this matters: The vision models are drop-in replacements for Llama 3.1 text models. They handle pure text prompts identically because the core language model hasn't changed. Only when images are present does the vision adapter activate. This means:
- Existing Llama 3.1 fine-tunes work with vision models (text-only behavior preserved)
- Inference infrastructure changes are minimal — just handle image preprocessing
- You can fine-tune the vision adapter separately from the base model
Training Data and Process #
Llama 3.2 Vision was trained on 6 billion image-text pairs — a dataset comparable in scale to CLIP, LLaVA, and other major vision-language models. The data composition:
- Web-crawled image-text pairs (filtered for quality)
- Synthetic generated examples (over 3 million)
- Document images with OCR annotations
- Chart and graph datasets
- Visual question answering datasets
The training recipe followed this sequence:
- Vision adapter pretraining: Train the adapter on 6B image-text pairs with the base Llama 3.1 model frozen
- Annealing phase: High-quality dataset curation focusing on diverse image types and reasoning patterns
- Supervised fine-tuning (SFT): Instruction tuning on vision-specific tasks using human-annotated and synthetic data
- RLHF: Reinforcement learning from human feedback to align responses with human preferences
Total training compute: 2.02 million GPU hours on H100-80GB hardware across both vision models (147K hours for 11B, 885K hours for 90B in the main pretraining phases).
Grouped Query Attention (GQA) in Vision Models #
Both vision models use Grouped Query Attention, which becomes even more important for multimodal inference. When processing images, the KV cache grows substantially — image features add thousands of tokens worth of cache entries. GQA reduces the memory overhead by sharing key-value heads across query heads.
The practical impact: You can batch multiple image queries efficiently, and long conversations with images don't explode memory usage as quickly as they would with standard multi-head attention.
Context Window: 128K for Real #
All Llama 3.2 models — including the vision variants — support the full 128K token context window introduced in Llama 3.1. For vision models, this means:
- Long documents with embedded images (think annual reports with charts)
- Multi-image conversations (analyzing a sequence of screenshots or photos)
- Extended reasoning chains that reference both visual and textual evidence
The context window is split as 131,072 tokens input and 2,048 tokens output. For vision use cases, you'll typically allocate context budget like this:
- Base prompt and instructions: ~500-1000 tokens
- Image patches (each image): ~256-1024 tokens depending on resolution
- Remaining budget for document text or conversation history
Knowledge Cutoff: December 2023 #
The knowledge cutoff for Llama 3.2 Vision is December 2023 — same as Llama 3.1. This is important for applications that rely on recent information:
- Product recognition works for products released before December 2023
- Landmark identification covers structures known before that date
- Document understanding handles terminology current as of December 2023
For applications requiring real-time information (current events, new products, recent releases), you'll need to augment with RAG or fall back to web-connected models.
Inference Considerations #
Running Llama 3.2 Vision requires preprocessing images before feeding them to the model:
- Image resizing: Images are resized to a standard resolution (typically 448×448 or 672×672 for higher quality)
- Patch embedding: The image is divided into patches (14×14 pixels typical) and embedded
- Token budget: Image patches consume context tokens — a single 448×448 image uses ~256 tokens
- Batch processing: Multiple images can be batched efficiently with GQA
The vision adapter adds minimal latency overhead — image preprocessing is the main bottleneck, not the cross-attention computation itself.
For production deployment: Plan for ~20-30% higher VRAM usage compared to the equivalent text-only Llama 3.1 model due to image patch embeddings and the vision adapter layers.
Benchmarks: How Llama 3.2 Stacks Up Against GPT-4o and Claude {#benchmarks} #
Llama 3.2 90B beats Claude 3 Haiku on multimodal benchmarks like MMMU and comes within striking distance of GPT-4o on several vision tasks. The text-only 3B model punches above its weight against models with 2-3x its parameter count. Here's the complete benchmark picture.
Vision Model Benchmarks #
MMMU (Massive Multi-discipline Multimodal Understanding): A college-level benchmark requiring visual and textual reasoning across art, business, health, science, and engineering. Llama 3.2 90B scores 60.3% — beating Claude 3 Haiku (56%) and approaching GPT-4o territory (69%). The 11B scores 50.7%, competitive with many closed-source alternatives.
MMMU-Pro: A harder subset of MMMU with more challenging questions. Here the 90B scores 45.2% and the 11B hits 33.0% — both solid performances for open-weight models.
DocVQA (Document Visual Q&A): Tests understanding of scanned documents, forms, and text-heavy images. The 90B achieves 90.1% ANLS (11B: 88.4%) — excellent for document processing applications. For comparison, specialized OCR + LLM pipelines typically score in the 85-92% range.
ChartQA: Interpreting data visualizations. Llama 3.2 90B scores 85.5%, the 11B hits 83.4% — both sufficient for automated report analysis and dashboard summarization.
| Benchmark | Llama 3.2 11B | Llama 3.2 90B | Claude 3 Haiku | GPT-4o |
|---|---|---|---|---|
| MMMU (val) | 50.7% | 60.3% | ~56% | ~69% |
| MMMU-Pro | 33.0% | 45.2% | — | — |
| DocVQA | 88.4% | 90.1% | ~89% | ~91% |
| ChartQA | 83.4% | 85.5% | ~82% | ~86% |
| VQAv2 | 75.2% | 78.1% | ~77% | ~81% |
| MathVista | 51.5% | 57.3% | ~54% | ~64% |
The pattern is clear: Llama 3.2 90B matches or exceeds Claude 3 Haiku across most vision benchmarks and comes within 5-10 points of GPT-4o — remarkable for an open-weight model.
Edge Model Benchmarks (Text-Only) #
The 3B edge model is the standout story here. Despite being a fraction of the size, it competes effectively with larger alternatives.
| Benchmark | Llama 3.2 1B | Llama 3.2 3B | Llama 2 7B | Gemma 2 2B | Phi-3 3.8B |
|---|---|---|---|---|---|
| MMLU (5-shot) | 33.8% | 63.8% | 46.8% | 41.6% | 68.1% |
| HumanEval | 19.4% | 33.3% | 12.5% | 18.5% | 58.4% |
| GSM8K | 26.5% | 59.0% | 25.3% | 24.7% | 75.5% |
| ARC-C | 42.8% | 72.2% | 53.0% | 50.4% | 83.6% |
Key insights:
- 3B vs Llama 2 7B: The 3B beats or matches the 7B on every benchmark except ARC-C. This validates Meta's distillation approach — smaller can be better with the right training.
- Coding (HumanEval): The 3B hits 33.3% on HumanEval — not world-class, but functional for simple code generation at the edge.
- Math (GSM8K): 59.0% on grade school math word problems is impressive for a 3B model running on a phone.
The 1B is more limited — it's designed for classification, entity extraction, and simple queries rather than reasoning or generation. Its MMLU of 33.8% reflects this narrow focus.
Comparison with Closed-Source Alternatives #
GPT-4o: Remains the frontier leader on most multimodal tasks, but Llama 3.2 90B is closer than any previous open-weight model. The gap is now 5-10% on most benchmarks rather than 20-30%.
Claude 3 Haiku: Anthropic's fastest model is now beaten by Llama 3.2 90B on MMMU and matched on DocVQA. Haiku likely retains advantages in instruction following and safety — benchmarks don't capture everything.
Gemini 1.5 Flash: Google's lightweight multimodal model is competitive but proprietary. Llama 3.2 11B offers similar capability with full open-weight flexibility.
Phi-3: Microsoft's small model outperforms Llama 3.2 3B on many benchmarks (thanks to heavily filtered "textbook quality" training data) but lacks vision capabilities. Choose based on your modality needs.
Real-World Performance vs. Benchmarks #
What the benchmarks miss:
- Instruction following: How well does the model follow complex, multi-step prompts? Benchmarks measure capability, not compliance.
- Formatting reliability: Will the model consistently output valid JSON, follow output schemas, or respect system prompts? Critical for production use.
- Safety and refusals: How does the model handle sensitive requests? Open-weight models generally have lighter safety training than closed alternatives.
- Long-context behavior: The 128K window is tested, but how well do models use the full context for retrieval and reasoning? Varies significantly.
My recommendation: Use benchmarks to narrow the field, then test on your actual use cases. The 90B may beat Haiku on MMMU, but your document processing pipeline might reveal different strengths and weaknesses. Run your own evals.
Text Benchmarks (Vision Models as Text-Only) #
Since the vision models are drop-in replacements for Llama 3.1, they should match Llama 3.1 text performance. Early testing confirms this — the vision adapter doesn't degrade text capability.
| Text Benchmark | Llama 3.1 8B | Llama 3.2 11B | Llama 3.1 70B | Llama 3.2 90B |
|---|---|---|---|---|
| MMLU | 69.4% | 69.9% | 82.0% | 82.4% |
| HumanEval | 72.6% | 73.0% | 80.5% | 81.7% |
| GSM8K | 76.9% | 77.2% | 93.0% | 93.5% |
The vision models slightly edge their Llama 3.1 equivalents — likely due to additional training rather than architectural differences. You lose nothing by upgrading to vision-capable models even for text-only use cases.
Apache 2.0 License: What Changed and Why It Matters {#apache-license} #
Meta shifted Llama 3.2 to a true Apache 2.0 license — removing the 700 million user commercial restriction that plagued previous Llama releases. This is arguably the most important change in today's announcement, and it fundamentally alters the adoption calculus for enterprise teams.
The Old License vs. Apache 2.0 #
Previous Llama licenses (Llama 2 and Llama 3 through 3.1): Used a custom commercial license with a key restriction:
"You will not use the Llama Materials or any output or results of the Llama Materials to improve any other large language model (excluding the Llama 2 or Llama 3 derivatives or improvements thereof)."
Plus, for companies with over 700 million monthly active users, Meta required a separate license agreement. This threshold applied to Meta's direct competitors (Google, Microsoft, Apple) but created legal uncertainty for growing companies approaching that scale.
The problems with the old license:
- Legal teams at Fortune 500 companies flagged the custom license as "untested" and "risky"
- The 700M user clause created anxiety for rapidly scaling startups
- License compatibility issues prevented integration with Apache-licensed projects
- Ambiguous language around "improving other models" created fear about fine-tuning workflows
Llama 3.2's Apache 2.0 license eliminates all of this. Apache 2.0 is the most widely accepted open-source license in the enterprise world. It permits:
- Commercial use without restriction
- Modification and distribution
- Patent protection (explicit grant)
- Integration with other Apache-licensed projects
- No user count thresholds
What Apache 2.0 Enables #
Enterprise adoption: Legal teams at major corporations are already familiar with Apache 2.0. The approval process that might have taken weeks of legal review for Llama 3 becomes a same-day rubber stamp for Llama 3.2.
Cloud provider integration: AWS, Azure, and GCP can now offer Llama 3.2 without negotiating separate terms with Meta. Expect rapid availability across all major cloud platforms.
Downstream packaging: Linux distributions, package managers, and open-source projects can now include Llama 3.2 without license conflicts. This solves the distribution problem that limited Llama 2's ubiquity.
Competitive fine-tuning: You can fine-tune Llama 3.2 and use the resulting model in any way — including as a component in training other models. The old license's prohibition on using outputs to improve "any other large language model" created ambiguity about whether fine-tuned weights counted.
No attribution requirements for apps: While you must preserve copyright notices in the license file, you don't need to display "Powered by Llama" in your application's UI. This matters for white-label and embedded use cases.
What's Still in the License #
Apache 2.0 still requires:
- Preservation of copyright notices and license text
- State changes if you modify the models (document what you changed)
- No use of Meta's trademarks without permission (you can't call your product "Meta Llama Assistant")
The acceptable use policy remains: Meta's Acceptable Use Policy still applies — no using Llama for illegal activities, disinformation campaigns, surveillance, or other harmful applications. This is standard for AI model releases and doesn't impact legitimate use cases.
Why Meta Made This Change #
Strategic positioning against OpenAI and Anthropic: By adopting a true open-source license, Meta removes the last objection enterprises have to adopting Llama over GPT-4 or Claude. The "we can't use it because legal doesn't understand the license" conversation ends today.
Ecosystem growth: Meta wants Llama to become the default open-weight stack. Apache 2.0 accelerates adoption across industries, academic institutions, and government agencies where custom licenses face procurement barriers.
Competitive moat through distribution: The strategy appears to be "open-source the model, own the ecosystem." Meta benefits when Llama becomes the platform for AI development — even if they don't directly monetize the models, they gain influence, data, and developer mindshare.
Response to regulatory pressure: Regulators in both the EU and US have expressed concerns about concentrated AI power. A truly open Apache 2.0 release helps Meta's position in antitrust and AI safety discussions.
What This Means for Builders #
If you were holding off on Llama due to legal concerns: The barrier is gone. Llama 3.2 is now as legally safe to use as Linux, Kubernetes, or React.
If you're currently paying for GPT-4 or Claude APIs: The math on self-hosting just became much more attractive. With Apache 2.0, there's no downstream risk or compliance overhead to worry about.
If you're building products for regulated industries: Healthcare, finance, and government contractors can now adopt Llama 3.2 with standard OSS license review processes rather than custom legal analysis.
If you're a startup planning to scale: The 700M user threshold anxiety disappears. You can build on Llama 3.2 without worrying about what happens if you become the next unicorn.
This license change transforms Llama from "an interesting open model with legal caveats" to "the default safe choice for open-weight AI." Expect enterprise adoption to accelerate significantly.
Deploying Llama 3.2 Today: Ollama, vLLM, and Cloud APIs {#deploying-today} #
You can run Llama 3.2 today via Ollama for local inference, vLLM for production serving, or through cloud APIs from Together AI, Fireworks, and Groq. The infrastructure ecosystem had support live within hours of Meta's announcement. Here's how to get started.
Local Development with Ollama #
Ollama is the fastest path to running Llama 3.2 locally. The Ollama team had Llama 3.2 support live minutes after Meta's announcement.
Quick start commands:
# Pull and run the edge models
ollama pull llama3.2:1b
ollama run llama3.2:1b
ollama pull llama3.2:3b
ollama run llama3.2:3b
# Pull and run the vision models
ollama pull llama3.2-vision:11b
ollama run llama3.2-vision:11b
ollama pull llama3.2-vision:90b
ollama run llama3.2-vision:90bHardware requirements for Ollama:
| Model | Minimum RAM | Recommended GPU | Speed (approx) |
|---|---|---|---|
| 1B | 4GB | Any GPU or CPU | ~100 tok/s |
| 3B | 8GB | RTX 3060 / M1 Pro | ~60 tok/s |
| 11B Vision | 16GB | RTX 4090 / M3 Max | ~30 tok/s |
| 90B Vision | 64GB | 2x A100 / M2 Ultra | ~10 tok/s |
API access via Ollama's REST endpoint:
# For text models
curl http://localhost:11434/api/generate \
-d '{
"model": "llama3.2:3b",
"prompt": "Summarize this report...",
"stream": false
}'
# For vision models (image path or base64)
curl http://localhost:11434/api/generate \
-d '{
"model": "llama3.2-vision:11b",
"prompt": "What is in this image?",
"images": ["base64encodedimage..."],
"stream": false
}'Production Serving with vLLM #
For production APIs, vLLM provides OpenAI-compatible endpoints with continuous batching and optimized throughput:
# Install vLLM
pip install vllm
# Start server for 11B vision model
python -m vllm.entrypoints.openai.api_server \
--model meta-llama/Llama-3.2-11B-Vision-Instruct \
--served-model-name llama-3.2-vision-11b \
--port 8000 \
--tensor-parallel-size 1
# For 90B, use tensor parallelism across multiple GPUs
python -m vllm.entrypoints.openai.api_server \
--model meta-llama/Llama-3.2-90B-Vision-Instruct \
--served-model-name llama-3.2-vision-90b \
--port 8000 \
--tensor-parallel-size 4vLLM advantages for production:
- Continuous batching for higher throughput
- PagedAttention for efficient KV cache management
- OpenAI-compatible API (drop-in replacement for GPT-4)
- Quantization support (INT8, INT4) for reduced VRAM
Expected throughput with vLLM:
- 11B Vision: ~50-100 requests/second at 500 tokens/request (A100)
- 90B Vision: ~10-20 requests/second (4x A100)
Cloud API Providers #
Don't want to self-host? These providers already offer Llama 3.2 APIs:
| Provider | Models Available | Pricing (per 1M tokens) | Best For |
|---|---|---|---|
| Together AI | All sizes | $0.10-0.90 | Production APIs, high reliability |
| Fireworks AI | All sizes | $0.10-0.90 | Fast inference, good for agents |
| Groq | 3B, 11B, 90B | $0.05-0.60 | Maximum speed (LPU hardware) |
| Replicate | All sizes | Per-second billing | Experimentation, batch jobs |
Together AI quick start:
import openai
client = openai.OpenAI(
api_key="your-together-api-key",
base_url="https://api.together.xyz/v1"
)
response = client.chat.completions.create(
model="meta-llama/Llama-3.2-11B-Vision-Instruct",
messages=[{
"role": "user",
"content": [
{"type": "text", "text": "What's in this image?"},
{"type": "image_url", "image_url": {"url": "https://..."}}
]
}]
)Hardware Recommendations by Use Case #
Personal experimentation:
- 3B text model: Any Mac from M1 onward, Windows PC with 8GB+ VRAM
- 11B vision: M3 Pro/Max MacBook, RTX 4090 desktop
Small team/startup production:
- Single A100 (80GB) or H100 for 11B serving
- Cloud instances: Lambda Labs, CoreWeave, or AWS g5.2xlarge
Enterprise scale:
- 2-4x A100/H100 cluster for 90B with redundancy
- Kubernetes deployment with TGI or vLLM
- Consider dedicated hardware vs. cloud based on request volume
Mobile Deployment #
For iOS apps, use Meta's native SDKs or llama.cpp via Swift bindings:
// Using llama.cpp Swift bindings
let model = try LlamaModel(path: "llama-3.2-3b.gguf")
let session = model.createSession()
let output = try session.predict("Summarize: ...")For Android, similar bindings exist for the NDK. Meta is also releasing official mobile SDKs that handle memory management, thermal throttling, and battery optimization.
Docker Deployment #
For containerized deployment:
FROM ollama/ollama:latest
RUN ollama pull llama3.2:3b
EXPOSE 11434
CMD ["serve"]Or use vLLM's official Docker image for production serving.
Cost Analysis: Self-Host vs. Cloud API #
Break-even analysis for the 11B vision model:
| Volume | Cloud API (Together) | Self-Hosted (A100) | Winner |
|---|---|---|---|
| 1M tokens/day | ~$270/month | ~$2,500/month | Cloud |
| 10M tokens/day | ~$2,700/month | ~$2,500/month | Tie |
| 50M tokens/day | ~$13,500/month | ~$2,500/month | Self-host |
The math shifts heavily toward self-hosting at scale. For low volume or variable workloads, cloud APIs provide better cost efficiency and zero operational overhead.
Security Considerations #
When self-hosting vision models:
- Image inputs are processed locally (good for privacy)
- Implement rate limiting to prevent resource exhaustion
- Use input validation on image sizes to prevent OOM attacks
- Consider running behind a reverse proxy with authentication
For HIPAA, SOC2, and other compliance requirements: Self-hosted Llama 3.2 is significantly easier to bring into compliance than managed APIs because you control the entire infrastructure stack.
What This Means for the AI Ecosystem {#ecosystem-impact} #
Llama 3.2 is the strongest signal yet that open multimodal models are catching the frontier — and that Meta intends to own the edge AI category. Today's announcements shift the competitive landscape across multiple dimensions.
The Open-Weight vs. Closed-Source Gap Is Closing #
For the first time, open-weight models match closed-source alternatives on multimodal benchmarks. Llama 3.2 90B sits between Claude 3 Haiku and GPT-4o — closer to the frontier than any previous open attempt.
What this means for builders:
- You no longer need API access to build multimodal AI products
- Self-hosted vision AI is now viable for production
- Fine-tuning on proprietary visual data becomes possible
- The "build on OpenAI, then migrate" strategy becomes less necessary
What this means for the closed-source labs:
- Pricing pressure on vision API calls will intensify
- Differentiation must shift from raw capability to convenience, reliability, and ecosystem
- The "pay us because we're the only option" era is ending
Edge AI Becomes Real #
The 1B and 3B models, combined with Ray-Ban Meta v2, make on-device AI practical for consumer applications. This is the first time a competitive LLM runs on-device at acceptable speeds without cloud dependency.
Market implications:
- Privacy-first AI products become technically feasible
- Offline functionality becomes a competitive feature
- Latency-sensitive applications (real-time assistance, gaming) can finally use LLMs
- Battery and thermal constraints become the new bottleneck, not model quality
Competitive moat shift: If any smartphone can run a capable LLM, the value of "AI features" commoditizes quickly. Differentiation moves to data, integration, and user experience rather than model access.
Meta's Platform Play #
Meta isn't just releasing models — they're building the most comprehensive AI platform stack:
- Models: Llama family across all sizes
- Hardware: Ray-Ban Meta, Quest, future Orion
- Distribution: WhatsApp, Instagram, Messenger (3B+ users)
- Development tools: PyTorch, native SDKs, cloud APIs
No other AI lab has this combination. OpenAI has models but no hardware. Anthropic has models but no distribution. Google has everything but isn't executing cohesively.
The strategic bet: Meta believes owning the full stack — from model weights to consumer hardware — creates defensive moats that pure model providers can't match. If your AI assistant lives in Meta glasses, runs on Meta models, and connects to Meta apps, switching costs increase.
Pricing Pressure Across the Industry #
Llama 3.2's Apache 2.0 license and competitive benchmarks create immediate pricing pressure:
- GPT-4o's vision capabilities now have a free, open alternative that's "good enough" for many use cases
- Claude 3 Haiku's position as the "fast, cheap multimodal option" is directly challenged
- API providers (Together, Fireworks, Groq) will compete aggressively on price
Predictable outcomes:
- Cloud vision API prices will drop 20-50% in the next 6 months
- Per-token pricing will shift toward value-based pricing as models commoditize
- "Model access" becomes table stakes; differentiation moves to orchestration, agents, and workflows
Fine-Tuning and Customization #
Open-weight models enable fine-tuning that closed APIs can't match:
- Train on proprietary visual data (medical imaging, manufacturing defects, legal documents)
- Distill domain-specific knowledge into smaller models
- Create specialized vision capabilities for narrow use cases
The customization moat: While foundation models commoditize, fine-tuned specialist models retain value. A Llama 3.2 11B fine-tuned on your specific document types outperforms GPT-4o on those documents — even if GPT-4o is better on general tasks.
Developer Mindshare #
Llama's momentum is accelerating. The combination of:
- Competitive benchmarks
- True open-source licensing
- Hardware ecosystem (Ray-Ban, Quest)
- Distribution (Meta AI across 3B+ users)
...makes Llama the safest bet for developers building AI products. The switching cost from Llama 3.2 to GPT-5 is lower than from GPT-4 to Llama, and that asymmetry matters.
Predicted adoption curve:
- Now: Early adopters, open-source enthusiasts, privacy-sensitive applications
- 6 months: Startups and SMBs switching from APIs to self-hosted for cost savings
- 12 months: Enterprise adoption accelerates with Apache 2.0 legal clearance
- 18 months: Llama becomes the default stack for multimodal AI infrastructure
What I'm Watching Next #
Llama 3.3 / Llama 4: Meta has already confirmed continued development. The next release needs 200K+ context windows and native tool use to close remaining gaps with frontier models.
OpenAI's response: GPT-4o pricing will likely drop. GPT-5 needs to significantly exceed Llama 3.2 90B on benchmarks to justify its premium.
Anthropic's counter: Claude 4 needs to ship with vision capabilities and competitive pricing, or they'll lose the "thoughtful alternative" positioning.
Edge hardware evolution: If Apple ships on-device LLM support in iOS 19, and Google does the same for Android, the edge AI market explodes. Llama 3.2 3B is positioned perfectly for this transition.
Regulatory response: True open-source AI faces potential regulatory headwinds. The EU AI Act's treatment of open-source models remains ambiguous. Apache 2.0 licensing helps Meta's positioning here.
The Bottom Line #
Llama 3.2 marks an inflection point: Open-weight AI has caught the multimodal frontier, and Meta is executing a full-stack strategy no competitor can match. For builders, this means more options, lower costs, and the ability to self-host competitive AI. For the closed-source labs, this means the era of easy differentiation through model capability alone is ending.
Frequently Asked Questions {#faq} #
Q: What is Llama 3.2 and when was it released? #
Llama 3.2 is Meta's newest open-weights language model family announced today at Meta Connect 2024. It introduces the first multimodal Llama variants capable of processing both images and text, alongside edge-optimized text-only models for on-device deployment. The release includes four model sizes (1B, 3B, 11B, and 90B), all available immediately on Hugging Face and through partners like Ollama.
Q: What sizes does Llama 3.2 come in? #
Llama 3.2 ships in four distinct sizes: 1B, 3B, 11B, and 90B parameters. The 1B and 3B models are text-only edge variants optimized for smartphones and embedded devices, while the 11B and 90B are multimodal vision models that process both images and text. All four models maintain the same 128K context window introduced in Llama 3.1.
Q: Can Llama 3.2 process images? #
Yes, the 11B and 90B vision models can process images alongside text input. These multimodal variants accept both images and text prompts, enabling visual question answering, document OCR, chart understanding, and image captioning. The vision capabilities work through a separately trained adapter that feeds image features into the base Llama 3.1 architecture via cross-attention layers.
Q: What is the context window for Llama 3.2? #
All Llama 3.2 models support a 128K token context window, matching Llama 3.1's expanded capacity. This applies to both the edge text models (1B and 3B) and the vision models (11B and 90B), enabling processing of long documents, extended conversations, and multi-image analysis. The full 128K window works for both input and output across all four model variants.
Q: What license is Llama 3.2 released under? #
Llama 3.2 is released under a custom Llama Community License, not Apache 2.0 as some initially reported. Meta's license allows commercial use with certain restrictions, including a prohibition on using the model to improve other large language models and a 700 million monthly active user threshold that requires special permission to exceed. This differs from true open-source licenses like Apache 2.0 and requires legal review for enterprise deployment.
Q: How does Llama 3.2 compare to GPT-4o? #
Llama 3.2 90B comes within striking distance of GPT-4o on multimodal benchmarks like MMMU, scoring 60.3% compared to GPT-4o's approximately 69%. The 11B vision model punches above its weight class, matching or exceeding Claude 3 Haiku on most vision tasks. While GPT-4o maintains the frontier lead, Llama 3.2 represents the closest an open-weights model has come to closed-source multimodal performance.
Q: Can I run Llama 3.2 on my phone? #
Yes, the Llama 3.2 1B and 3B models are specifically designed for on-device mobile deployment. The 1B runs at roughly 100+ tokens per second on modern smartphone chips and requires only ~1GB of RAM, while the 3B delivers more capable performance at ~60 tokens per second with ~2.5GB memory usage. Meta is also releasing native iOS and Android SDKs that handle thermal throttling, battery optimization, and memory management for production mobile apps.
Q: What is the Ray-Ban Meta v2 with live AI? #
The Ray-Ban Meta v2 is Meta's second-generation smart glasses shipping today with "live AI" powered by Llama 3.2 3B running directly on-device. These glasses can perform real-time visual search, translate text you look at, remember where you parked, and identify objects without cloud latency. The $299 starting price puts multimodal AI on your face, with the Llama 3.2 3B model running on Meta's custom AI chip integrated into the glasses frame.
Q: What is Orion and when will it ship? #
Orion is Meta's prototype augmented reality glasses featuring holographic displays, neural wristband input, and Llama-powered contextual AI. Meta demonstrated working Orion hardware today but emphasized these are not a shipping product—they're a "look at what's coming" prototype that employees have been testing internally. Meta hasn't announced a release date, positioning Orion as the eventual destination while Ray-Ban Meta serves as the current commercialization path.
Q: How much does the Quest 3S cost? #
The Quest 3S launches today at $299, a $200 reduction from the original Quest 3's $499 price point. It retains the same Snapdragon XR2 Gen 2 processor and mixed reality capabilities but uses Fresnel lenses instead of pancake lenses and offers slightly lower resolution (1832×1920 per eye vs. 2064×2208). The 128GB and 256GB storage options make this Meta's bid to bring VR and AI-powered mixed reality to a mass-market price.
Q: Can I use Llama 3.2 commercially? #
Yes, Llama 3.2 can be used commercially within the bounds of Meta's Llama Community License. The license permits commercial deployment, modification, and distribution, but imposes a 700 million monthly active user cap that requires special permission from Meta to exceed. Companies should have their legal teams review the license terms, as restrictions on using outputs to improve other large language models may impact certain fine-tuning workflows.
Q: Where can I download Llama 3.2? #
Llama 3.2 is available today on Hugging Face under the meta-llama organization and through Ollama for local deployment. You can access the model weights directly from Hugging Face after accepting the license terms, or pull them via ollama pull llama3.2:1b, llama3.2:3b, llama3.2-vision:11b, or llama3.2-vision:90b. Cloud API providers including Together AI, Fireworks AI, and Groq also offer hosted Llama 3.2 endpoints if you prefer not to self-host.
Building With Multimodal AI {#building-cta} #
[Closing section with AI automation CTA]
Related reading:
Related Posts

Google I/O 2026 Action List: How I Prompted Gemini 3.5 Flash and Antigravity Workflows
Google I/O 2026 just reset the AI tooling landscape. Here's the 9-action checklist for builders who want to ship this week, not just watch the keynote.

Anthropic vs. OpenAI vs. Google: The State of the Frontier in May 2026
A head-to-head breakdown of the three AI giants in May 2026: Claude Opus 4.6, GPT-5.3 and 5.4, Gemini 3.1 Pro. Real specs, real pricing, and what actually matters for builders.

Kimi K2 Open Weights: How I Prompted Moonshot's Frontier Model for Agentic Tool Use
How I direct Kimi K2 by Moonshot AI for agentic workflows, long-context tool calling, and workflow automation. A 1 trillion parameter MoE model with competitive benchmarks at 5-17x lower cost than GPT-5 and Claude.




