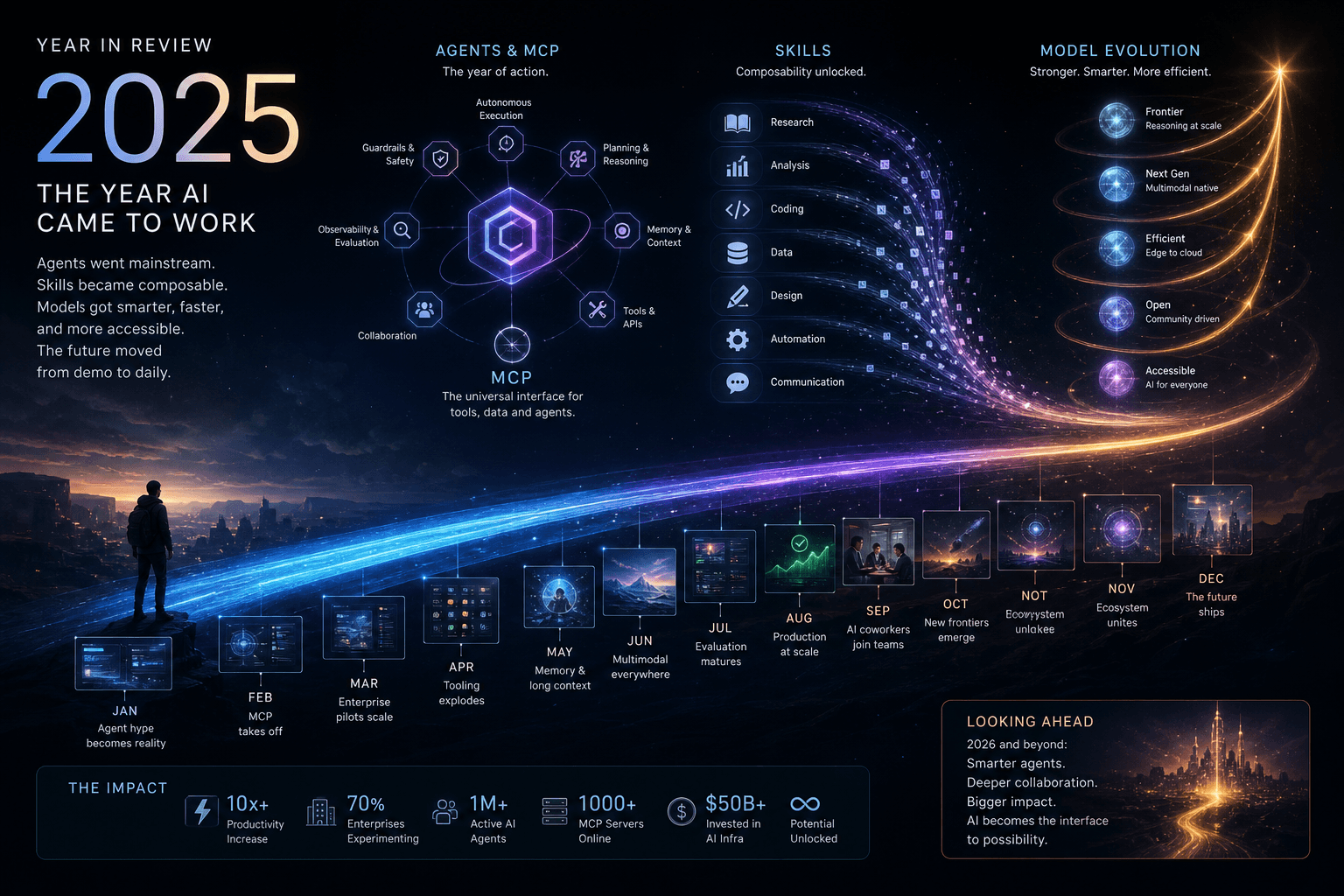
2025 Year in Review: The Year I Prompted Agents, MCP, and Skills

Table of Contents
2025 Year in Review: The Year I Prompted Agents, MCP, and Skills #
As December 2025 draws to a close, I'm sitting here reflecting on what has unquestionably been the most consequential year in artificial intelligence history. Not the most hyped—though there was plenty of that—but the year when the fundamental nature of how I direct and prompt AI systems changed forever.
This was the year I stopped writing API integrations and started prompting agents. The year MCP went from an Anthropic experiment to the universal standard for how I connect AI to external systems. The year models became commoditized while the prompting layer—Skills, terminal agents, and composable capabilities—became where I actually deliver value for clients. And the year when every major tech company placed their bets on what comes after the chatbot era: systems I direct with natural language rather than hand-coded configurations.
Let me walk you through what actually mattered.
January: Operator, Stargate, and the DeepSeek Shockwave #
The year opened with a bang. OpenAI's Operator announcement on January 23 wasn't just another research preview—it was a declaration that the interface paradigm was shifting. An agent that could actually use a computer, click buttons, fill forms, and navigate the web? This wasn't GPT-4 with a better prompt. This was the first system where I could describe a task in natural language and watch it execute through a browser—no API documentation, no authentication handlers, no DOM selectors required.
Simultaneously, the Stargate announcement on January 21—OpenAI's $500B joint venture with Oracle, SoftBank, and MGX—signaled that the infrastructure race was entering a new phase. Half a trillion dollars for AI infrastructure, with $100 billion deploying immediately starting with data centers in Texas. Let that sink in. The announcement, made at a White House meeting with President Trump, was called "the largest AI infrastructure project in history." Technology partners included Arm, Microsoft, NVIDIA, and Oracle.
But the real January story was DeepSeek R1. Released on January 20, this Chinese open-source reasoning model didn't just match o1's performance—it triggered the largest single-day market cap loss in history. On January 27, NVIDIA shed nearly $593 billion in value as the stock dropped 16.9%. The Nasdaq fell 3.1%. The Philadelphia semiconductor index tumbled 9.2%. The narrative that American AI dominance was unassailable? Shattered.
What made DeepSeek R1 so disruptive wasn't just performance—it was efficiency. Developed in just two months at a cost of under $6 million, it proved that efficient architecture and clever training could compete with brute-force scaling. The "bigger is better" orthodoxy had its first serious challenger.
The market reaction exposed a vulnerability in the AI investment thesis: if efficient training techniques could deliver frontier capabilities at commodity prices, the entire hardware-dependent ecosystem faced disruption. NVIDIA would recover, of course—their chips remained essential for training. But the psychology had shifted. Competition was real, global, and accelerating.
February: Claude 3.7 Sonnet and the Rise of Claude Code #
Anthropic's response came fast. Claude 3.7 Sonnet launched on February 24, and it was a hybrid reasoning model—the first of its kind. Unlike previous models where you chose between fast responses and deep thinking, Claude 3.7 could do both. API users could control exactly how many tokens the model used for reasoning, up to 128,000 tokens of extended thinking. Pricing remained unchanged at $3 per million input tokens and $15 per million output tokens, with thinking tokens counted in output pricing.
But the bigger news was Claude Code—an agentic coding companion that integrated directly into terminal workflows. Available as a limited research preview, Claude Code enabled me to delegate substantial engineering tasks through natural language prompts rather than explicit commands.
I spent that week refactoring a 50,000-line codebase by prompting Claude Code with high-level architectural goals—not writing scripts, not configuring pipelines, just describing what I wanted and reviewing its execution. This was the moment when "AI-assisted coding" became "prompt-first development." The difference between Copilot's autocomplete and Claude Code's autonomous file manipulation, testing, and debugging—directed entirely through conversational prompts—was generational. The model showed particularly strong improvements in coding and front-end web development, with 45% fewer unnecessary refusals compared to previous versions.
Claude 3.7 Sonnet's hybrid architecture mattered because it eliminated the choice I had been forced to make: speed or quality. For the first time, I could prompt a single model for both rapid iterations and deep reasoning.
OpenAI tried to stay in the conversation with GPT-4.5 Orion, a research preview that showed impressive multimodal capabilities but never quite found its place in the product lineup. It was good—sometimes great—but it didn't define a category the way Claude Code did.
The February takeaway: Anthropic understood that the moat wasn't the model. It was the prompting interface. Claude Code wasn't a chat interface—it was a workflow transformation where my natural language intent became executable infrastructure.
March: Gemini 2.5 Pro and the Studio Ghibli Aesthetic War #
Google entered the chat in force this March with Gemini 2.5 Pro Experimental, announced on March 25—their most intelligent AI model to date. Featuring a 1 million token context window (expandable to 2 million tokens) and topping the LMArena leaderboard by a significant margin, it was positioned as Google's answer to the frontier model competition.
But the cultural moment that defined March wasn't the benchmark scores—it was the Studio Ghibli wave.
Overnight, everyone's social feeds transformed into a Miyazaki-inspired fever dream. Gemini's image generation capabilities, particularly its adherence to artistic style prompts, created the first true viral AI moment of 2025. I watched as prompt engineering for aesthetic consistency became a mainstream skill—users could create Ghibli-style images from text prompts, though limitations remained—Gemini couldn't generate Ghibli-style images from uploaded images, nor derive styles from user-provided images directly.
The debates about copyright, artistic integrity, and the nature of creativity that followed? We'll be having those conversations for years. By March 31, Google had expanded access to make Gemini 2.5 Pro available to all free users, capitalizing on the viral momentum.
More consequentially, OpenAI launched the Responses API and Agents SDK in March, providing me with the first comprehensive toolkit for building autonomous agents through prompt-based orchestration rather than imperative code. This wasn't just an API update—it was OpenAI acknowledging that the future wasn't chat completions. It was goal-directed systems that I could prompt to plan, execute, and iterate.
The March throughline: image generation matured from novelty to cultural force, and the infrastructure for agentic systems—systems I prompt rather than program—started solidifying. Google demonstrated they could capture cultural moments while OpenAI built the prompting infrastructure for the agent era.
April: Google A2A and OpenAI's o3 + Codex CLI #
April brought us competing visions of agent interoperability. On April 9, Google announced the Agent2Agent (A2A) Protocol—an open standard that enables AI agents built by different vendors to communicate and collaborate.
A2A wasn't just a specification—it was a bet on a multi-agent future. Built on HTTP, Server-Sent Events (SSE), and JSON-RPC, A2A uses "Agent Cards" (JSON documents) for agents to advertise their identity, capabilities, and authentication methods. The protocol supports a complete task lifecycle with defined states: submitted, working, input-required, completed, failed, canceled. Over 50 technology partners supported the launch, including Atlassian, Box, Cohere, Intuit, LangChain, MongoDB, PayPal, Salesforce, SAP, ServiceNow, and major service providers like Accenture, BCG, Deloitte, and McKinsey.
The A2A vs MCP debate would rage through the spring, but the reality was more nuanced: A2A was about agent-to-agent communication, MCP was about agent-to-tool access. They weren't competitors so much as complementary layers of the emerging agent stack. Smart developers started building with both.
OpenAI, meanwhile, dropped o3 and o4-mini on April 16—their most capable reasoning models yet. o3 achieved state-of-the-art results on Codeforces and SWE-bench, making 20% fewer major errors than o1 on difficult real-world tasks. o4-mini, the smaller, cost-efficient variant, achieved 99.5% pass@1 on AIME 2025 with Python interpreter access.
The same day, OpenAI launched Codex CLI—an open-source coding agent that runs locally in your terminal. Available via npm or Homebrew, Codex CLI could write and edit code, move files, and take other local actions with multimodal reasoning from the command line. The message was clear: Anthropic wasn't the only one who understood where the developer market was heading.
April's lesson: the agent ecosystem was fragmenting before it had even fully formed. Standards wars, protocol competition, and the race to own the developer relationship were all accelerating simultaneously.
May: The Claude 4-Cursor-I/O Build Week Trinity #
If there was a single week that defined 2025, it was May 22. Anthropic launched Claude 4—not a single model, but two: Claude Opus 4 and Claude Sonnet 4. This wasn't just an upgrade; it was a statement of intent.
Claude Opus 4 became the world's best coding model, leading on SWE-bench with 72.5% performance, featuring sustained performance on complex, long-running tasks and agent workflows. Priced at $15/$75 per million tokens, it targeted the high-value enterprise market where accuracy matters more than cost.
Claude Sonnet 4 delivered 72.7% SWE-bench performance at the same $3/$15 pricing as its predecessor—offering superior coding and reasoning with enhanced instruction-following. Both models introduced extended thinking with tool use (beta), parallel tool use, and improved memory capabilities.
The same week, Cursor released version 0.50 on May 15, introducing unified request-based pricing, Max Mode for all top models, and Background Agent in early preview. Then Cursor 1.0 launched in early June—a five-day I/O Build Week that felt like the Woodstock of AI-assisted development.
I was there, and the energy was unmistakable. Cursor 1.0 brought BugBot (automatic code review that catches bugs in PRs), Background Agent (now generally available), Jupyter support for multi-cell editing, Memories (beta feature letting the agent remember facts per project), and one-click MCP installation with OAuth support. Cursor wasn't just a VS Code fork anymore—it was becoming the definitive IDE for the AI era.
Their compositional agent architecture, where multiple specialized agents could collaborate on complex tasks, pointed toward a future where software engineering becomes orchestration more than implementation. The company had already crossed $300 million ARR by mid-April, doubling approximately every two months.
OpenAI's response came with Codex Agent in late May—their first fully asynchronous coding agent, powered by codex-1 (an optimized o3). You could assign it a task, go to lunch, and return to find a complete implementation with tests, documentation, and deployment configuration. The "vibe coding" era had arrived.
May's significance: this was when the coding landscape irreversibly shifted. The developers who adapted to AI-first workflows started pulling away from those who didn't. The gap wasn't just productivity—it was a fundamentally different relationship with the craft of software engineering.
June: WWDC 2025 and Cursor's $9.9B Valuation #
Apple's WWDC 2025 keynote on June 9 brought Liquid Glass—a radical reimagining of their design language and the company's broadest design update ever. This new translucent digital material combines optical qualities of glass with fluid dynamics, dynamically bending light in real-time to create a lensing effect.
Liquid Glass extends across iOS 26, iPadOS 26, macOS Tahoe, watchOS 26, and tvOS 26, appearing in controls, buttons, switches, sliders, tab bars, sidebars, Lock Screen, Home Screen, notifications, and Control Center. Objects materialize and dematerialize by modulating light bending rather than fading, creating interactions that Apple's VP of Human Interface Design described as "more fun and magical."
Alongside the visual overhaul came the second year of Apple Intelligence features. The Siri improvements were notable, but the bigger story was how deeply integrated AI had become across the entire Apple ecosystem. From Notes summarization to Mail smart replies, Apple was making AI ambient rather than explicit. The strategy was clear: own the interface layer, partner for the models.
Meanwhile, on June 5, Anysphere raised $900 million in Series C funding at a $9.9 billion valuation—led by returning investor Thrive Capital with participation from Andreessen Horowitz, Accel, and DST Global. Cursor had surpassed $500 million in annual recurring revenue, up from $300 million just six weeks prior, with ARR doubling approximately every two months.
Let me emphasize how insane this is: Cursor was founded in 2022. In three years, they went from zero to nearly $10B by building the best AI-native developer experience. Used by over half of the Fortune 500 including NVIDIA, Uber, and Adobe, Cursor became "the fastest-growing startup ever" according to Bloomberg. The VCs weren't betting on the technology—they were betting on a fundamental shift in how software gets built.
Earlier in 2025, OpenAI had approached Anysphere about acquisition. The company declined. OpenAI subsequently acquired competitor Windsurf for a reported $3 billion.
June's theme: AI becoming invisible infrastructure, and the tooling layer capturing disproportionate value.
July: ChatGPT Agent and the Frontier Model War #
The summer heat brought the official ChatGPT Agent launch on July 17—bringing Operator's capabilities to the mainstream ChatGPT interface for Pro, Plus, and Team subscribers. Available by selecting "agent mode" from the tools dropdown, ChatGPT Agent combined Operator's ability to interact with websites, Deep Research's information synthesis, and conversational intelligence. It could navigate websites, fill forms, edit spreadsheets, run code, and connect to third-party apps like Gmail and GitHub.
Suddenly, 200+ million users had access to an agent that could browse, shop, book, and research on their behalf. Pro users received 400 queries per month; Plus and Team users received 40. Enterprise and Edu plans gained access on August 8. The standalone Operator experience at operator.chatgpt.com was deprecated, with core functionality integrated into ChatGPT Agent through its built-in virtual browser.
The adoption curve was steep. Within weeks, we started seeing the first real data on what users actually wanted agents to do. Shopping assistance dominated. Research and summarization followed. Creative writing and coding came next. The "killer app" for agents? It turned out to be a portfolio of use cases, not a single breakthrough.
But July's bigger story was the Grok 4 release on July 9—xAI's claim to the frontier model crown. Drawing 1.5 million concurrent viewers to the livestream announcement, Grok 4 introduced native tool use (code interpreter, web browsing), real-time search integration, and a 256,000-token context window. Available to SuperGrok and Premium+ subscribers ($30/month), with a SuperGrok Heavy tier ($300/month) featuring up to 32 parallel agents for enhanced reasoning.
Grok 4's benchmarks were striking: 26.9% on Humanity's Last Exam without tools, 41% with tools, 50.7% with the Heavy variant. It achieved 100% on AIME 2025 (math) with Heavy, 88.9% on GPQA, and 15.9% on ARC AGI V2—nearly doubling previous high scores. Training on xAI's 200,000 GPU Colossus cluster achieved 6x compute efficiency improvements.
Kimi K2 from Moonshot AI dropped within days, demonstrating that Chinese labs could compete at the absolute frontier. The frontier model war was now genuinely global.
The July takeaway: agents went mainstream, and the model race became a multipolar competition.
August: GPT-5 Arrives and DeepSeek's Counterpunch #
August 2025 will be remembered as the month when the "one model to rule them all" vision was finally realized. GPT-5 launched on August 7—not as multiple models, but as a unified system with intelligent routing. A single interface that could deliver fast, efficient responses for simple queries or extended, deep reasoning for complex problems.
The technical achievement cannot be overstated. GPT-5 combined three components: a fast, efficient model for most questions; a deeper reasoning model for harder problems; and a real-time router that decided which to use based on conversation type, complexity, and user intent. The router continuously improved based on user signals like preference rates and measured correctness.
API users got three sizes: gpt-5, gpt-5-mini, and gpt-5-nano, offering flexibility in trading off performance, cost, and latency. GPT-5 became OpenAI's strongest coding model, scoring 74.9% on SWE-bench Verified and 88% on Aider polyglot benchmarks.
The pricing was equally transformative. The model commoditization thesis I'd been tracking all year hit its inflection point. Models were becoming utilities—cheap, reliable, interchangeable. The race to the bottom was on.
DeepSeek wasn't finished, though. V3.1 dropped on August 21 with hybrid reasoning capabilities—supporting both "Think" and "Non-Think" modes in a single model. With a 128K context window for both API modes, strict function calling (beta), and Anthropic API compatibility, DeepSeek V3.1 enabled direct integration with Claude Code through environment variable configuration. Developers could switch model backends without changing workflows, preserving the full Claude Code experience including REPL, permission sandbox, MCP/tooling, and status line—while cutting costs to roughly 1/11th of Claude Sonnet pricing (~$0.27 per 1M tokens vs. $3).
August's significance: the future became unambiguous. Universal models, not model selection. Agents, not chatbots. Integration, not isolation. And the infrastructure layer becoming the primary value capture point.
September: Claude Sonnet 4.5, Sora 2, and iPhone 17 #
September is always Apple season, but 2025 was different. Claude Sonnet 4.5 launched on September 29—Anthropic's most powerful model to date, excelling at coding, complex agents, and computer use. It immediately became my go-to model for most tasks.
The performance numbers were striking: state-of-the-art on real-world software coding (SWE-bench Verified), 61.4% accuracy on computer use tasks (OSWorld benchmark)—up from Sonnet 4's 42.2% just four months prior. The model could maintain focus for over 30 hours on complex, multi-step tasks. Pricing remained at $3/$15 per million tokens, delivering more capability at the same cost.
The release included upgrades to Claude Code with checkpoints, a native VS Code extension, context editing features, and the Claude Agent SDK for developers. The speed-to-quality ratio was unmatched—faster than GPT-5 for many workflows, with reasoning capabilities that rivaled dedicated reasoning models.
OpenAI countered with Sora 2 on September 30—the second generation of their video generation model. Where Sora 1 was impressive but inconsistent, Sora 2 was production-ready with improved physical accuracy, better adherence to physics (basketballs rebound correctly rather than teleporting), synchronized dialogue and sound effects, enhanced controllability for intricate multi-shot instructions, and the ability to insert real people into generated environments with accurate appearance and voice.
Filmmakers, advertisers, and content creators started integrating it into actual workflows. The "AI-generated video" stigma started fading as the quality crossed the threshold from "obviously fake" to "uncanny, but usable."
Then came iPhone 17 on September 9—announced alongside new Apple Watches. The hardware improvements were substantial: a larger 6.3-inch Super Retina XDR OLED display with 120Hz ProMotion (up from 60Hz), reaching 3,000 nits peak brightness—the highest for any iPhone. Ceramic Shield 2 provided 3x better scratch resistance. The new 48MP "Dual Fusion" camera system included a 48MP main camera doubling as a 2x telephoto, plus a 48MP ultrawide camera. The 18MP Center Stage front camera enabled landscape selfies without rotating the phone.
Powered by the A19 chip, iPhone 17 started at $799 for 256GB—double the previous starting storage. Notably, Apple downplayed Apple Intelligence as the star of the show, with some AI features missing from the launch. The strategy remained: own the hardware and interface, partner for the intelligence.
September's theme: AI crossing the threshold from impressive demo to reliable, production-ready tool.
October: OpenAI DevDay and Anthropic's Skills Launch #
October brought the two ecosystem-defining announcements of the year. OpenAI DevDay 2025 on October 6 introduced AgentKit—a comprehensive toolkit for building, deploying, and optimizing production-grade agents. DevDay felt different from 2023's event. Less demo, more infrastructure.
AgentKit included: Agent Builder (a visual canvas for composing multi-agent workflows with drag-and-drop nodes), ChatKit (embeddable chat-based agent experiences), Connector Registry (centralized admin panel for managing data sources including Dropbox, Google Drive, SharePoint), and evaluation capabilities with datasets, trace grading, automated prompt optimization, and third-party model support.
Built on OpenAI's Responses API and adopted by hundreds of thousands of developers, AgentKit enabled companies like Ramp and LY Corporation to build agents in hours rather than weeks. OpenAI also released the Apps SDK in preview—built on Anthropic's Model Context Protocol—allowing developers to build apps that run directly inside ChatGPT. Initial apps included Booking.com, Canva, Coursera, Expedia, Figma, Spotify, and Zillow.
OpenAI was acknowledging that their platform play required giving developers the tools to build things OpenAI would never build themselves. The features—memory management, tool orchestration, state persistence—addressed the pain points developers had been hacking around for months.
Not to be outdone, Anthropic launched Skills on October 16—their vision for composable agent capabilities. Skills weren't just tools; they were standardized, shareable, composable units of agent behavior—folders containing instructions, scripts, and resources that Claude loads dynamically when needed.
Available to Pro, Max, Team, and Enterprise users, Skills function like "custom onboarding materials that let you package expertise," transforming Claude into a specialist for specific tasks. Companies like Box, Rakuten, and Canva were already using them. The Skills Marketplace—launched alongside the framework—created the first real economy around agent capabilities. Developers started building Skills for niche use cases, and businesses started buying them.
October's insight: the battleground shifted from model capability to ecosystem lock-in. Whoever owned the agent tooling layer was going to capture the value. OpenAI and Anthropic were both betting that the platform, not the model, was the long-term moat.
November: Cursor's $29B Series D and Gemini 3 Pro #
The late-year funding environment was supposed to be cautious. Interest rates were steady, IPO markets were quiet, and the "AI bubble" narrative was building.
Then on November 13, Cursor announced their Series D—raising $2.3 billion at a $29.3 billion post-money valuation. Led by new investor Coatue with continued participation from Accel, Thrive Capital, Andreessen Horowitz, and DST Global, plus new investors NVIDIA and Google. The valuation represented a nearly threefold increase from June's $9.9 billion—in just five months.
The numbers were staggering: Cursor crossed $1 billion in annualized revenue, with enterprise revenue growing 100x year-to-date. Serving millions of developers and many Fortune 500 companies, the company expanded to over 300 employees across San Francisco and New York offices.
I wrote at the time that this wasn't just a bet on Cursor—it was a bet on the entire category of AI-assisted software engineering becoming the default within 24 months. That bet looks prescient now. The funding will support technical research, product development, frontier model training (including their recently launched Composer agentic coding model), and team expansion.
Google responded with Gemini 3 Pro on November 18—their most capable model ever. Scoring 72.1% on SimpleQA Verified and 76.2% on SWE-bench Verified, it outperformed previous versions in reasoning, multimodal understanding, and agentic workflows. Available in preview through Google AI Studio and Vertex AI at $2/million input and $12/million output tokens for prompts under 200K tokens.
Two days later, Google unveiled Antigravity on November 20—an agent-first development platform designed to work alongside Gemini 3 Pro. Combining a familiar AI-powered IDE with a manager surface for orchestrating multiple agents asynchronously, Antigravity introduced Artifacts—tangible deliverables like task lists, screenshots, and browser recordings that verify agent work without reviewing raw tool calls.
Available in public preview for free on macOS, Windows, and Linux, Antigravity supports Gemini 3 Pro, Claude Sonnet 4.5, and OpenAI's GPT-OSS. Google had finally entered the AI-native IDE race in force.
November's significance: the market structure became clear. A handful of model providers would compete on capability and price. A handful of tooling platforms would compete on developer experience. And everyone else would build on top of those layers. Cursor's $29B valuation proved that the tooling layer was where the value was accumulating.
December: GPT-5.2 and Shipmas 2.0 #
As I write this on December 22, we're in the middle of OpenAI's Shipmas 2.0—twelve days of announcements that have included GPT-5.2—announced December 11 as their most advanced frontier model for professional work.
GPT-5.2 comes in three variants: Instant (faster for writing and information seeking), Thinking (better at structured work like coding and planning), and Pro (most accurate for difficult questions). The improvements are substantial: better at creating spreadsheets, building presentations, writing code, perceiving images, understanding long contexts, and handling complex multi-step projects.
The performance metrics tell the story: GPT-5.2 Thinking beats or ties top industry professionals on 70.9% of well-specified knowledge work tasks across 44 occupations on the GDPval benchmark—the first model to perform at or above human expert level. It achieves 92.4% on GPQA Diamond (graduate-level science questions) and 40.3% on FrontierMath Tier 1-3 expert-level mathematics. In software engineering: 55.6% on SWE-Bench Pro and 80.0% on SWE-Bench Verified. The Thinking variant shows about 30% fewer factual errors than previous versions.
GPT-5.2 began rolling out December 11 in ChatGPT for paid plans and became immediately available via API to all developers.
Shipmas has also brought Advanced Voice Mode improvements, Canvas updates for collaborative document editing, and hints about what's coming in 2026—including the long-rumored OpenAI hardware partnership with Jony Ive.
December's reflection point: after a year of relentless advancement, the industry is catching its breath and building the infrastructure for whatever comes next. The models are good enough. The tooling is mature enough. The question for 2026 isn't what's technically possible—it's what we'll build with the capabilities we now have.
The MCP Revolution: From Experiment to Universal Standard #
If I had to pick one technical development that defined 2025, it wouldn't be any single model. It would be MCP—the Model Context Protocol.
When Anthropic launched MCP in November 2024, it was a promising experiment. By December 2025, it's the universal standard for how I prompt agents to interact with external systems. Every major provider supports it. Every serious AI Solutions Architect knows it. And it's reshaping how I think about AI architecture—replacing hand-coded API integrations with declarative, prompt-compatible tool definitions.
The genius of MCP is its simplicity. Instead of me implementing bespoke Python/TypeScript integrations with databases, APIs, file systems, and tools, MCP provides a standard JSON-RPC interface I can prompt any model to use. A model that speaks MCP can use any MCP-compatible tool. A tool that implements MCP can be invoked by any MCP-compatible model through natural language prompts.
The ecosystem exploded this year. MCP servers now exist for:
- Data sources: PostgreSQL, MongoDB, Snowflake, BigQuery, Redis, SQLite
- Development tools: GitHub, GitLab, Jira, Linear, Sentry, Vercel
- Productivity suites: Slack, Notion, Google Workspace, Microsoft 365, Discord
- Infrastructure: AWS, GCP, Azure, Kubernetes, Docker, Terraform
- Specialized domains: Figma, Stripe, Salesforce, HubSpot, Shopify, Twilio
- Search and knowledge: Brave Search, Exa, Hacker News, Fetch
What started as an Anthropic initiative has become an open standard, governed by the community, with implementations across the ecosystem. The MCP Spec 1.0 release in October codified what had been a living document into a stable foundation.
The elegance of MCP is in its protocol design. Instead of writing connection handlers, I now prompt with references to standardized tool definitions. Here's the JSON-RPC schema that defines how I prompt agents to interact with PostgreSQL:
{
"name": "postgresql-server",
"version": "1.0.0",
"tools": [
{
"name": "query",
"description": "Execute a SQL query",
"parameters": {
"type": "object",
"properties": {
"sql": { "type": "string" },
"limit": { "type": "number", "default": 100 }
},
"required": ["sql"]
}
},
{
"name": "schema",
"description": "Get database schema information",
"parameters": {
"type": "object",
"properties": {
"table": { "type": "string" }
}
}
}
]
}The model doesn't need to know PostgreSQL's wire protocol. I don't write connection strings or authentication logic. I simply prompt the agent with access to this MCP server, and it understands it can invoke the "query" tool with SQL parameters. MCP handles the rest—connection pooling, error handling, result formatting, and security.
This abstraction layer is why MCP won. It turned every database, API, and service into a prompt-accessible capability that any model could invoke. The implementation complexity moved to the server side; the prompting interface became standardized.
For my clients, MCP has been transformative. AI automation projects that previously took weeks of hand-coding integration work now take days of prompt engineering. The ability to connect Claude, GPT, or Gemini to existing infrastructure through MCP tool definitions—rather than custom development—has reduced costs and accelerated timelines dramatically.
The Rise of AI Coding Assistants: Cursor, Claude Code, and the Antigravity Wave #
2025 was the year my relationship with software engineering changed forever. Not incrementally—fundamentally.
I've been building software for over a decade, and I've never seen a shift this rapid. The AI Solutions Architects who embraced prompting-based development this year aren't just more productive—they're working differently. They're prompt orchestrators more than implementers. They're capability architects more than craftsmen.
Cursor emerged as the clear leader, but the category itself became crowded and competitive:
| Platform | Strength | Best For |
|---|---|---|
| Cursor | Compositional agents, deep IDE integration | Professional developers, complex codebases |
| Claude Code | Terminal-native, exceptional reasoning | Backend developers, DevOps, data engineering |
| GitHub Copilot | Ubiquity, GitHub integration | Enterprise teams, existing Microsoft shops |
| OpenAI Codex | Asynchronous execution, broad capability | Full-stack projects, rapid prototyping |
| Google Antigravity | Gemini integration, search-native workflows | Research, content-heavy applications |
| Zed AI | Performance, Rust-native speed | Systems programming, performance-critical code |
The debate about whether AI would "replace developers" missed the point entirely. What happened instead was a stratification. The practitioners who mastered prompting workflows—describing intent in natural language and reviewing AI-generated implementation—pulled ahead dramatically. The gap between prompt-native and traditional hand-coding approaches became a chasm.
I track this in my own work. Projects that took 40 hours of me writing code in 2024 now take 15 hours of me prompting agents in 2025. The reduction isn't uniform—some tasks got 10x faster, others barely changed. The pattern is clear: boilerplate, refactoring, and test generation respond nearly instantly to well-crafted prompts. Architecture, complex debugging, and novel algorithm design still require deep thought—but now I prompt exploration rather than writing exploratory code.
The AI Solutions Architect skill stack is reorganizing. In 2023, I valued syntax knowledge, library familiarity, and debugging intuition. In 2025, I value prompt specification clarity, context window management, and review judgment. The craft hasn't disappeared—it's migrated from implementation to intent articulation.
Here's how the tooling evolved through the year:
| Quarter | Cursor Milestone | Claude Code Feature | OpenAI Release |
|---|---|---|---|
| Q1 | Tab completions, inline chat | Research preview launch | Codex CLI |
| Q2 | 0.50 unified pricing, Background Agent preview | Claude 4 integration | Codex Agent (async) |
| Q3 | 1.0 release, BugBot, MCP install | VS Code extension, Agent SDK | - |
| Q4 | Composer model, $29B valuation | Skills framework integration | - |
For my agency clients, this has created both opportunity and challenge. The opportunity: I can deliver projects in weeks that previously took months by prompting agent swarms rather than hand-coding. The challenge: client expectations have reset. "Why would this take six weeks when you can just prompt AI?" is a question I hear weekly.
The answer, of course, is that prompting agents generates implementation but doesn't ship products. Architecture, user experience, quality assurance, deployment, maintenance—these still require human judgment and expertise. But the ratio has shifted. Where a team of four might have been needed to write code, a team of two with strong prompting skills can often deliver equivalent or superior results.
The practitioners at risk aren't the ones prompting AI—they're the ones still hand-coding everything. Junior developers who would have grown through writing thousands of lines of boilerplate now need different growth paths centered on prompt engineering and review. Senior developers who resist prompting find themselves outpaced by prompt-native juniors who can specify, review, and iterate faster than traditional developers can write.
Model Commoditization: The Pricing Collapse That Reshaped Everything #
If you'd told me in January 2025 that by December, top-tier model inference would cost 90% less while delivering 10x better performance, I'd have called you optimistic. But that's exactly what happened.
The GPT-5 pricing announcement in August was the inflection point: $0.50/$1.50 per million tokens for a model that outperformed everything else on the market. The race to the bottom was on.
Here's how pricing evolved for equivalent-quality models this year:
| Period | Input Price (per 1M tokens) | Output Price (per 1M tokens) | Notes |
|---|---|---|---|
| January 2025 | $15-30 | $45-90 | GPT-4 Turbo, Claude 3 Opus era |
| April 2025 | $5-10 | $15-30 | Gemini 1.5 Pro, Claude 3.5 Sonnet |
| August 2025 | $0.50-2.00 | $1.50-6.00 | GPT-5 launch resets market |
| December 2025 | $0.10-1.00 | $0.30-3.00 | DeepSeek, Llama, Qwen drive open-source pressure |
This pricing collapse had profound implications:
First, AI features became economically viable for every application I design. When inference cost $30 per million tokens, I had to be selective about where I deployed AI. At $0.50, I can prompt agents for virtually every interaction. Every button can be smart. Every form can understand context. Every notification can be personalized.
Second, the business models shifted. The margin in AI moved from model providers to application builders who can effectively prompt and orchestrate. When everyone has access to cheap, capable models, differentiation comes from prompt engineering sophistication, integration depth, and user experience—not from having a slightly better LLM.
Third, the open-source ecosystem exploded. DeepSeek, Llama 3.3, Qwen 2.5, and dozens of other open models reached parity with proprietary alternatives. Why pay OpenAI when I can prompt Llama 3.3 405B on my own infrastructure for pennies?
Here's the detailed pricing evolution for top-tier models through 2025:
| Model | Release Date | Input (per 1M) | Output (per 1M) | Context |
|---|---|---|---|---|
| GPT-4 Turbo | Jan 2025 | $10.00 | $30.00 | 128K |
| Claude 3 Opus | Jan 2025 | $15.00 | $75.00 | 200K |
| Gemini 1.5 Pro | Apr 2025 | $3.50 | $10.50 | 1M |
| Claude 3.5 Sonnet | Apr 2025 | $3.00 | $15.00 | 200K |
| GPT-4o | Apr 2025 | $5.00 | $15.00 | 128K |
| GPT-5 | Aug 2025 | $0.50 | $1.50 | 128K |
| Claude Sonnet 4.5 | Sep 2025 | $3.00 | $15.00 | 200K |
| Gemini 3 Pro | Nov 2025 | $2.00 | $12.00 | 2M+ |
| GPT-5.2 | Dec 2025 | $0.50 | $1.50 | 128K |
| DeepSeek V3.1 | Aug 2025 | $0.27 | $1.10 | 128K |
The 90% price reduction from January to December isn't just a discount—it's a category transformation. At $30 per million tokens, AI was a feature you added selectively. At $0.50, it's infrastructure you build on by default.
For my automation practice, this has been transformative. Projects that were borderline uneconomical in January became no-brainers by June. The constraint stopped being "can we afford the AI?" and became "can we integrate it effectively?"
A real example: A client project in January required careful token budgeting—$800/month for inference costs. The same project rebuilt in October using GPT-5 costs $45/month with better results. The difference isn't just savings; it's permission to be more ambitious. We added features that would have been economically irresponsible in January.
The Agent Era: From Chatbots to Autonomous Systems #
The fundamental shift of 2025 wasn't a model release. It was a structural transformation in how I direct AI: from chatbots I query with questions, to agents I prompt with goals that act on my behalf.
Look at the evolution:
2023-2024: I ask a chatbot a question. It responds. The interaction is conversational and stateless. Each query is independent. I'm the one doing the work; AI assists.
2025: I prompt an agent with a goal. It plans, executes, iterates, and delivers. The interaction is transactional and stateful. The agent remembers, adapts, and persists. AI does the work; I direct.
This shift required three technical breakthroughs that all matured this year:
Long-context windows: Claude 3.7's 200K token context, Gemini 3 Pro's millions of tokens, GPT-5's adaptive routing—these made it possible for agents to maintain coherent state across complex, multi-step tasks I describe in natural language.
Tool use and MCP: The standardized Model Context Protocol gave agents the ability to invoke external tools reliably through JSON-RPC, with proper error handling and result interpretation, turning models from conversational engines into action-capable systems I can prompt to interact with the world.
Reasoning capabilities: o3, DeepSeek R1, and the reasoning modes in GPT-5 and Claude 4 gave agents the ability to plan, debug, and course-correct without me hand-coding the logic.
The result? Agents I can prompt to:
- Research: Synthesize information from dozens of sources, identify gaps, and fill them
- Code: Build full applications from my specifications, including tests and documentation
- Operate: Navigate web interfaces, fill forms, make purchases, schedule appointments
- Analyze: Process datasets, generate insights, create visualizations, and write reports
- Create: Generate content across modalities—text, code, images, video, audio
For my clients, this changes the calculus of automation. Previous automation required me to write structured data handlers, predefined workflows, and extensive configuration. Agentic automation is flexible, adaptive, and handles edge cases through prompting that would have broken traditional RPA systems I had to hand-code.
Open Source Surge: DeepSeek, Llama, and the Democratization of Frontier AI #
2025 was the year open-source AI stopped playing catch-up and started setting the pace.
DeepSeek was the story of the year. Their R1 model in January proved that Chinese labs could compete at the frontier. Their V3 and V3.1 releases throughout the year kept them in the conversation with models that matched or exceeded proprietary alternatives on many benchmarks.
But DeepSeek wasn't alone. Meta's Llama 3.3 series—including the massive 405B parameter model released in July—gave the open-source community a GPT-4-class foundation model. Alibaba's Qwen 2.5 models, particularly the 72B and 110B variants, became favorites for fine-tuning and specialized applications.
The impact on my practice was profound:
Self-hosting became viable: For the first time, I could run frontier-class models on my own infrastructure without massive quality trade-offs. Privacy-sensitive clients—healthcare, finance, legal—could finally adopt AI without sending data to third-party APIs. The compliance benefits alone justified the operational complexity for many enterprises I work with.
Fine-tuning flourished: Open models can be fine-tuned. Proprietary models generally can't. This created an entire economy around specialized, domain-specific models that outperformed general-purpose alternatives on narrow tasks. A legal client fine-tuning Llama 3.3 on case law outperformed GPT-4 on legal reasoning tasks—at 1/50th the inference cost.
Competition accelerated: The existence of capable open models put pressure on proprietary providers to improve faster and price more aggressively. Everyone benefited. OpenAI's aggressive GPT-5 pricing was partly a defensive move against the open-source threat.
Regional diversity: Open models enabled regional AI ecosystems. Chinese, European, and Middle Eastern companies built on open foundations rather than depending entirely on American providers. DeepSeek's success proved that frontier capabilities weren't the exclusive domain of Silicon Valley.
Here's how the open-source models tracked against proprietary alternatives in 2025:
| Model | Release | Parameters | Key Feature | SWE-bench |
|---|---|---|---|---|
| DeepSeek R1 | Jan 2025 | ~680B | Reasoning, MoE | 49.2% |
| Llama 3.1 405B | Jul 2025 | 405B | Dense, general-purpose | 54.8% |
| Qwen 2.5 72B | Aug 2025 | 72B | Multilingual, coding | 48.2% |
| DeepSeek V3.1 | Aug 2025 | ~680B | Hybrid reasoning | 55.2% |
| Llama 3.3 70B | Nov 2025 | 70B | Efficiency, agents | 51.4% |
| Qwen 2.5 110B | Nov 2025 | 110B | Vision, long-context | 52.1% |
For my clients, the open-source surge has created options. I can prompt GPT-5 for general tasks, Claude 4 for reasoning-heavy work, and self-hosted Llama or Qwen for sensitive data or specialized domains. The "one model for everything" approach is increasingly obsolete.
The real power in my practice comes from model selection based on task characteristics:
- General knowledge, customer-facing: GPT-5 for reliability and brand safety
- Complex reasoning, coding: Claude 4 for accuracy and extended thinking
- Privacy-sensitive, compliance: Self-hosted Llama 3.3 for data control
- Specialized domains: Fine-tuned Qwen for domain-specific knowledge
- Cost-sensitive at scale: DeepSeek for high-volume, low-complexity tasks
This polyglot model strategy—prompting the right model for each task—has become standard practice in my work by December 2025.
Skills, Tools, and the Standardization of Agent Primitives #
One of the quieter but most important developments of 2025 was the standardization of how I build agent capabilities through prompting rather than programming.
The landscape in January was fragmented. Every agent framework had its own tool definition format. Every model provider had its own function-calling syntax. Integrating a new capability meant bespoke development for each platform.
By December, I've converged on shared primitives that let me prompt agents using standardized definitions:
MCP for tool definition: The Model Context Protocol provides a standard JSON-RPC way to describe what tools do, what parameters they take, and what they return—letting me prompt any MCP-compatible agent to use any MCP-compatible tool.
Skills for capability composition: Anthropic's Skills framework and similar approaches from OpenAI and Google let me define reusable, composable units of agent behavior that I can invoke through natural language prompts rather than API calls.
Agent descriptors: Emerging standards for describing agent capabilities, limitations, and requirements—making it possible for agents I prompt to discover and delegate to other agents.
This standardization matters because it enables an ecosystem where I can prompt rather than program. When everyone agrees on how to define a tool, I can prompt any agent to use it. When everyone agrees on how to define a skill, I can compose capabilities through prompts. When everyone agrees on how to define an agent, the agents I prompt can collaborate.
The ecosystem effects are already visible. The MCP Server Registry has thousands of community-contributed integrations I can prompt agents to use. The Claude Skills Marketplace has hundreds of vetted, prompt-invokable capabilities. And I'm starting to see the first "agent networks"—collections of specialized agents that I can prompt to hand off tasks to each other based on capability matching.
What Mattered and What Didn't: A Critical Assessment #
After a year of relentless AI news, it's worth distinguishing signal from noise. Here's my take on what actually mattered in 2025:
What Mattered #
MCP standardization: This will be remembered as the moment AI infrastructure grew up. The protocol that lets any model use any tool is the foundation everything else builds on.
Agentic coding tools: Cursor, Claude Code, and their competitors haven't just made developers more productive—they've changed what it means to be a developer. The impact on software velocity and quality will compound for years.
Model commoditization: The pricing collapse and open-source surge democratized access to frontier AI. The constraint is no longer access—it's imagination and integration capability.
Reasoning capabilities: o3, R1, and the reasoning modes in GPT-5 and Claude 4 made AI reliable enough for high-stakes applications. The jump from "sometimes right" to "usually right, and knows when it's not" is transformative.
Context window expansion: Claude 3.7's 200K tokens and Gemini 3 Pro's millions changed what's possible. You can now hand an AI your entire codebase, your entire document archive, your entire knowledge base.
What Didn't Matter (As Much As We Thought) #
AGI announcements: Every major lab made noise about progress toward AGI this year. None of it changed what we can actually do today. The research is important, but the rhetoric is mostly marketing.
Benchmark supremacy: "State-of-the-art on MMLU" became meaningless as every model reached the ceiling. Real-world performance and reliability matter more than benchmark points.
The "AI Bubble" narrative: Pundits spent the year predicting a crash. Instead, we got sustainable infrastructure building. The bubble talk missed that AI is being adopted, not just invested in.
Multimodal demos: Video generation, image creation, and audio synthesis got dramatically better. But most business value this year still came from text and code. The multimodal revolution is coming, but it's not here yet.
The State of Play: December 2025 Market Map #
As the year closes, here's how I see the competitive landscape:
Model Providers (Commoditized Infrastructure) #
| Provider | Position | 2026 Watch |
|---|---|---|
| OpenAI | Market leader with GPT-5, strong developer platform | Can they maintain premium pricing? |
| Anthropic | Quality leader, best-in-class agentic tools | Claude 5 and enterprise expansion |
| Scale leader, Gemini 3 Pro is formidable | Integration with Google Workspace | |
| DeepSeek | Open-source champion, efficient training | International expansion, V4 |
| Meta | Open model foundation with Llama | Business model for Llama sustainability |
| xAI | Fast follower, Grok has loyal following | Differentiation beyond "less filtered" |
Tooling Platforms (Where the Value Is) #
| Platform | Position | 2026 Watch |
|---|---|---|
| Cursor | Clear leader in AI-native IDE | Can they expand beyond developers? |
| Claude Code | Best terminal/agentic experience | Integration with broader Anthropic ecosystem |
| OpenAI Platform | Most comprehensive API/tools | Closing the gap with specialized tools |
| Google AI Studio | Strong Gemini integration, improving rapidly | Enterprise sales execution |
| Vercel AI SDK | Standard for web AI integration | Can they expand beyond React/Next.js? |
Infrastructure Standards #
- MCP: Universal winner for tool integration
- A2A: Useful for agent-to-agent, but narrower than hoped
- Skills: Fragmented between vendors, consolidation likely in 2026
What 2026 Might Bring: Forward-Looking Reflections #
I'm not in the prediction business—there's too much uncertainty and too many variables. But as I look toward 2026, a few trends seem inevitable:
Agent ecosystems will mature: What we've built in 2025 are individual agents. In 2026, we'll see true multi-agent systems—swarms of specialized agents collaborating on complex tasks, with emergent capabilities that exceed any individual agent.
Physical AI will arrive: We've focused on digital agents. The next frontier is agents that interact with the physical world—robotics, IoT, autonomous systems. The models are ready; the integration is coming.
Regulation will reshape the landscape: The EU AI Act is in force. American regulation is coming. The wild west phase of AI development is ending, and structured frameworks will advantage incumbents with compliance resources.
The tooling wars will intensify: Cursor's dominance isn't guaranteed. Claude Code is excellent. OpenAI has resources. Google has distribution. 2026 will be a fight for the developer relationship that makes the model competition look tame.
Open source will pressuring proprietary margins: As open models get better and cheaper to run, the premium for proprietary models shrinks. The business model for frontier model development is still uncertain.
Frequently Asked Questions #
What was the most important AI release of 2025? #
GPT-5 in August. While MCP was more consequential for infrastructure and Cursor changed how developers work, GPT-5 was the release that made AI universally capable and affordable. It reset pricing expectations, delivered on the "one model" promise, and made high-quality AI accessible to applications that couldn't justify previous costs.
Did AI actually get better, or just cheaper? #
Both, dramatically. The best models of December 2025 outperform January's best by margins that would have seemed impossible a year ago. Reasoning, reliability, instruction following, and context understanding all improved substantially. And yes, they got 90%+ cheaper. We're getting more and paying less—a genuine technological revolution.
Is MCP really the universal standard now? #
Yes, functionally. Every major model provider supports MCP or has announced support. Thousands of tools have MCP implementations. The ecosystem has reached the tipping point where new tools launch with MCP support by default. It's not officially "the standard" in a standards-body sense, but it's the de facto standard in practice.
Should developers use Cursor, Claude Code, or something else? #
It depends on your workflow. Cursor is the best integrated IDE experience for most developers. Claude Code is exceptional for terminal-native workflows and complex reasoning tasks. GitHub Copilot has the best enterprise integration. Many developers (including me) use multiple tools for different contexts. The "right" answer is the one that fits how you work.
What's the difference between an AI agent and an AI assistant? #
Goal-directed autonomy. An assistant responds to your queries. An agent pursues goals you set. Assistants are conversational and stateless; agents are transactional and stateful. When you ask ChatGPT a question, that's an assistant. When you tell an agent "book me a flight to Tokyo next Tuesday, business class, direct if possible," and it searches, compares, selects, and purchases—that's an agent.
Are open-source models actually competitive with GPT-5 and Claude 4? #
For many use cases, yes. Llama 3.3 405B, DeepSeek V3.1, and Qwen 2.5 110B are competitive with proprietary models on most tasks. Where they lag is in reasoning (o3 and Claude 4 still lead) and multimodal capabilities. For privacy-sensitive applications or specialized fine-tuning, open models are often superior choices.
What happened to the "AI bubble" everyone was predicting? #
We got infrastructure instead. The investment continued, but it shifted from speculative bets to infrastructure building. Cursor's $29B valuation isn't bubble pricing—it's recognition that they've built a transformative platform with real revenue and genuine competitive advantage. The companies that survive this phase will be the ones that deliver value, not just demos.
Will AI replace software developers? #
No, but it will stratify them. Developers who master AI-assisted workflows are already dramatically more productive than those who don't. The gap will widen. "Software engineer" will increasingly mean "AI orchestrator"—someone who designs systems, specifies requirements, reviews output, and handles edge cases that AI can't. Implementation becomes less central; architecture becomes more so.
What's the biggest risk in the current AI landscape? #
Concentration and dependency. We're building critical infrastructure on platforms controlled by a handful of companies. If OpenAI, Anthropic, or Cursor makes a change, thousands of businesses are affected instantly. The MCP standard helps by enabling portability, but the underlying models and platforms are still concentrated. Diversification—using multiple providers, maintaining open-source options, building abstraction layers—is prudent risk management.
What should businesses prioritize for AI in 2026? #
Integration over innovation. The models are good enough. The tooling is mature enough. The opportunity is in connecting AI to your actual workflows, data, and systems—not in chasing the latest model release. Focus on: (1) MCP-based tool integration, (2) agentic workflow design, (3) team AI literacy, and (4) robust evaluation frameworks to measure actual impact.
What about AI safety? Did we solve it? #
No, but we're managing it better. 2025 brought real progress in alignment research, red-teaming practices, and responsible deployment. The major labs have safety teams with actual veto power over releases. But the fundamental challenges—evaluating systems more capable than their evaluators, ensuring robustness across edge cases, managing societal impacts—remain unsolved. Safety isn't a destination; it's a continuous process.
Is it too late to get into AI development? #
Absolutely not. The tooling is more accessible than ever. The learning resources are abundant. And most importantly, the applications are still being invented. We're in the infrastructure-building phase; the application explosion comes next. If anything, it's the perfect time—enough maturity to build on, enough greenfield to innovate in.
Final Reflections on a Transformative Year #
As I close this review on December 22, 2025, I'm struck by how much changed in twelve months. Not incrementally—transformatively.
In January, I was still explaining to clients why AI mattered and how it might help their business. By December, those conversations are about prompting strategies, agent orchestration patterns, and governance frameworks. AI isn't hypothetical anymore. It's the infrastructure I prompt to deliver client outcomes.
The shift from chatbots to agents I direct with natural language, the emergence of MCP as a universal standard for tool prompting, the commoditization of frontier models, the rise of prompt-native development tools—each of these would have been the story of the year in any previous year. That they all happened in 2025 speaks to the velocity of this moment.
What I'm watching most closely as I enter 2026:
The multi-agent wave: Individual agents I prompt were 2025's story. Agent collectives that I orchestrate with higher-level prompts will be 2026's.
Physical AI integration: Digital agents are mature. Agents that I prompt to interact with the physical world—robotics, IoT, autonomous systems—are next.
The regulatory reshaping: Compliance will become a competitive advantage for well-resourced incumbents. I'm preparing my clients now.
Open-source pressure on business models: As open models get better, the economics of proprietary model development get challenged. I stay model-agnostic to serve client interests.
The human adaptation: The hardest part isn't the technology—it's the organizational and cultural change required to use prompting effectively. I'm building training for this.
2025 was the year AI grew up. Not in the hype-cycle sense, but in the maturity sense. We moved from experiments to infrastructure, from demos to deployments, from potential to practice—and I moved from writing APIs to prompting agents.
The next phase starts now.
Transform Your Business with AI #
If 2025 proved anything, it's that AI isn't coming—it's here. The businesses that thrive in 2026 will be the ones that move from experimentation to implementation, from isolated pilots to prompt-orchestrated agent systems.
That's where I come in.
For AI Automation + Growth: I design and deploy AI-powered automation systems that actually deliver ROI. From MCP-based agent architectures that I prompt to integrate with your existing stack, to custom workflow automation orchestrated through natural language, I help businesses turn AI potential into operational reality. If you're looking to automate intelligently, scale efficiently, and capture the competitive advantage that AI offers, book an AI Automation Strategy Call. I'll assess your current operations, identify high-impact automation opportunities, and build a roadmap to get you there.
For Custom Websites + Digital Experiences: I build the kind of AI-integrated, high-performance web experiences that define categories. If you need a website that doesn't just look exceptional but works intelligently—integrating AI agents you can prompt, dynamic personalization, and modern architecture—book a Custom Website Discovery Call. We'll explore what's possible when exceptional design meets prompt-directed intelligence.
Either way, the future isn't waiting. Let's build it—one prompt at a time.
Written by William Spurlock on December 22, 2025, reflecting on the most consequential year in AI history. Follow my ongoing analysis at williamspurlock.com.
Related Posts

Google I/O 2026 Action List: How I Prompted Gemini 3.5 Flash and Antigravity Workflows
Google I/O 2026 just reset the AI tooling landscape. Here's the 9-action checklist for builders who want to ship this week, not just watch the keynote.

Anthropic vs. OpenAI vs. Google: The State of the Frontier in May 2026
A head-to-head breakdown of the three AI giants in May 2026: Claude Opus 4.6, GPT-5.3 and 5.4, Gemini 3.1 Pro. Real specs, real pricing, and what actually matters for builders.

Kimi K2 Open Weights: How I Prompted Moonshot's Frontier Model for Agentic Tool Use
How I direct Kimi K2 by Moonshot AI for agentic workflows, long-context tool calling, and workflow automation. A 1 trillion parameter MoE model with competitive benchmarks at 5-17x lower cost than GPT-5 and Claude.




