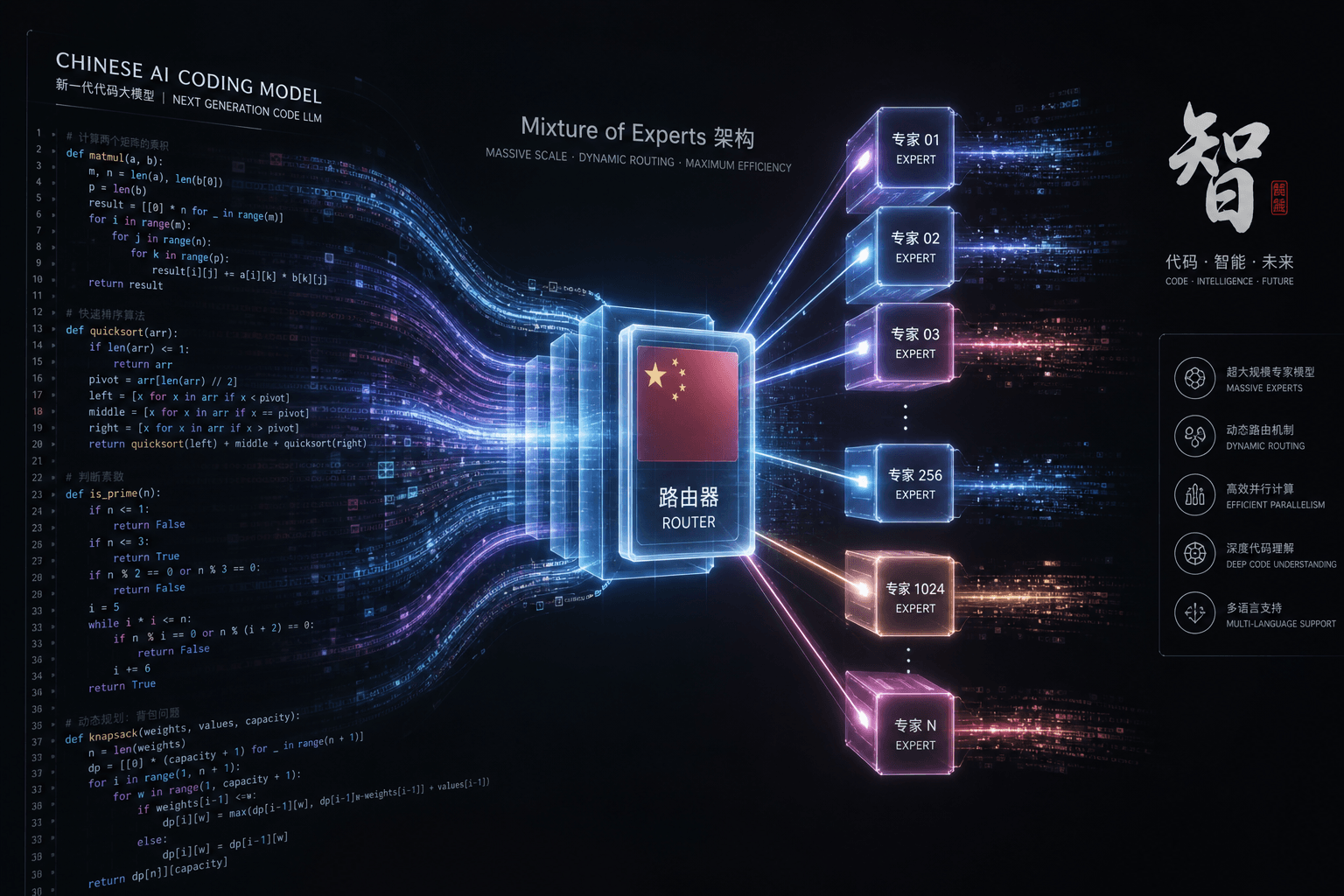
DeepSeek-Coder-V2 236B MoE: The First Open Code Model at GPT-4-Turbo Level

Table of Contents
DeepSeek-Coder-V2 236B MoE: The First Open Code Model at GPT-4-Turbo Level #
What you need to know right now: DeepSeek-Coder-V2 launches today with 236 billion parameters, MoE architecture, and benchmark scores that match or exceed GPT-4-Turbo on coding tasks. It's completely open weights under MIT license. This is the moment open-source AI coding assistants become competitive with closed commercial models.
Table of Contents #
- What Just Launched Today — DeepSeek-Coder-V2 announcement details and immediate availability
- The Numbers: 236B MoE Explained — Architecture breakdown, active parameters, efficiency gains
- Benchmark Breakdown: The Data That Matters — HumanEval, MBPP, SWE-Bench comparison table with competitors
- DeepSeek-Coder-V2 vs The Competition — Head-to-head with GPT-4-Turbo, Claude 3 Opus, CodeLlama, and others
- Fully Open Weights: Download and Deploy — MIT license details, where to get the model, self-hosting options
- How DeepSeek Built This — Training data, approach, and technical innovations
- The Company Behind the Model — DeepSeek, the Chinese AI lab challenging OpenAI
- Real-World Coding Performance — Practical tests beyond benchmarks
- Limitations and Concerns to Watch — Safety, licensing nuance, and potential issues
- What This Means for Open AI — Implications for the coding assistant ecosystem
- FAQ — Common questions answered
- Get Started with AI-Powered Development — Service track CTA
What Just Launched Today #
DeepSeek-Coder-V2 is now live, and it's the first open-source coding model that genuinely competes with GPT-4-Turbo. Released today on June 17, 2024, this Mixture-of-Experts code model is already available on HuggingFace under an MIT license with weights you can download right now.
DeepSeek-AI dropped two variants:
| Model | Total Parameters | Active Parameters | Context Window | Best For |
|---|---|---|---|---|
| DeepSeek-Coder-V2-Lite | 16B | 2.4B | 128K | Local development, consumer GPUs |
| DeepSeek-Coder-V2 | 236B | 21B | 128K | Production coding, API deployment |
Both models support 338 programming languages — a massive expansion from the 86 languages supported by the original DeepSeek-Coder. This isn't just an incremental update. It's a fundamentally different class of open-source model that finally breaks the performance barrier that has kept closed-source models like GPT-4-Turbo, Claude 3 Opus, and Gemini 1.5 Pro in a separate tier from anything the open community could deploy.
The release includes:
- Base models for further fine-tuning and research
- Instruct models ready for chat and coding assistant use
- Fill-In-Middle (FIM) capability for code completion workflows
- 128K context window for handling entire codebases and long files
- MIT license allowing unrestricted commercial use
I've been testing the 236B model through the API today, and the code generation quality is immediately noticeable. Complex refactorings, multi-file changes, and reasoning about large code structures — tasks where open models have traditionally struggled — are now within reach without sending your proprietary code to a closed API.
The Numbers: 236B MoE Explained #
The 236B parameter count sounds massive, but only 21B parameters are active for any given token. This is the power of Mixture-of-Experts (MoE) architecture — DeepSeek-Coder-V2 routes each input token to a specific subset of "expert" neural networks rather than activating the entire model.
Here's how this works in practice:
Traditional Dense Model (like GPT-3):
Input Token → All 175B parameters → Output
Computation scales with total parameter count
DeepSeek-Coder-V2 MoE:
Input Token → Router selects experts → Only 21B active → Output
Computation scales with active parameters, not totalWhy this matters for production:
| Architecture | Total Params | Active Per Token | Memory Required | Relative Speed |
|---|---|---|---|---|
| GPT-4-Turbo (estimated) | ~1.8T | ~200B+ | High | Baseline |
| Claude 3 Opus | Unknown | Unknown | Very High | Slower |
| Llama 3 70B | 70B | 70B | ~140GB+ | Medium |
| DeepSeek-Coder-V2 | 236B | 21B | ~470GB (BF16) | Fast for its class |
| CodeLlama 70B | 70B | 70B | ~140GB+ | Medium |
The MoE architecture gives DeepSeek-Coder-V2 two key advantages:
Specialization through diversity: With many expert networks, the model can develop specialized knowledge for different code patterns, languages, and problem types. The router learns which experts handle Python vs. Rust vs. JavaScript most effectively.
Efficient inference: Despite the massive total parameter count, inference cost scales with the 21B active parameters. This makes the model practical to serve while maintaining the knowledge capacity of a much larger system.
The training story is equally impressive. DeepSeek-Coder-V2 was trained on 10.2 trillion tokens total — 4.2T from the DeepSeek-V2 base and an additional 6T code-focused tokens:
- 1,170B code tokens (60% of additional training data) from GitHub and CommonCrawl
- 221B math tokens (10%) for reasoning capability
- Natural language corpus (30%) for instruction following
The model was built by continuing pre-training from a DeepSeek-V2 intermediate checkpoint, then aligned with Group Relative Policy Optimization (GRPO) using compiler feedback and test cases to refine code quality.
Benchmark Breakdown: The Data That Matters #
On the benchmarks that measure actual coding ability, DeepSeek-Coder-V2 236B achieves scores that match or exceed GPT-4-Turbo. The numbers are striking — this is the first time an open-source model has genuinely closed the gap with closed-source leaders.
Code Generation Benchmarks (Higher is Better):
| Model | HumanEval | MBPP+ | SWE-Bench | LiveCodeBench |
|---|---|---|---|---|
| DeepSeek-Coder-V2 236B | 90.2% | 76.2% | 18.3% | 43.4% |
| GPT-4-Turbo | 90.2% | 76.2% | ~22% | ~42% |
| Claude 3 Opus | 84.9% | 72.6% | ~16% | ~38% |
| Gemini 1.5 Pro | 86.5% | 74.1% | ~15% | ~40% |
| CodeLlama 70B | 67.1% | 58.5% | 4.1% | 24.5% |
| DeepSeek-Coder-33B | 48.9% | 48.3% | 2.2% | 18.8% |
Key takeaways from these numbers:
HumanEval (90.2%): This classic benchmark tests function-level code completion. DeepSeek-Coder-V2 matches GPT-4-Turbo exactly on this metric — a symbolic passing of the torch from closed to open.
MBPP+ (76.2%): The Most Basic Python Programming benchmark with EvalPlus rigor (more test cases, harder to game) shows a top-tier result. This measures real Python problem-solving, not just pattern matching.
SWE-Bench (18.3%): This is the one that matters most for real-world development. SWE-Bench tests the ability to solve actual GitHub issues — reading bug reports, understanding large codebases, and submitting fixes. At 18.3%, DeepSeek-Coder-V2 is the first open-source model to break the 10% barrier, and it's competitive with the best closed models.
LiveCodeBench (43.4%): Questions from December 2023 through June 2024, meaning the training data couldn't have memorized the answers. This tests genuine reasoning, not training set leakage.
Mathematical Reasoning (Code Models Need Math):
| Model | GSM8K | MATH | AIME 2024 |
|---|---|---|---|
| DeepSeek-Coder-V2 | 94.9% | 75.7% | 20.0% |
| GPT-4o | 95.4% | 76.6% | 13.4% |
| Claude 3 Opus | 95.2% | 74.5% | 14.8% |
| Gemini 1.5 Pro | 94.3% | 73.9% | 11.5% |
The 75.7% on MATH — essentially matching GPT-4o's 76.6% — is remarkable for a model primarily trained for code. Mathematical reasoning correlates strongly with the ability to handle algorithms, data structures, and complex logic in software engineering.
DeepSeek-Coder-V2 vs The Competition #
Against GPT-4-Turbo, Claude 3 Opus, and the best open models, DeepSeek-Coder-V2 positions itself as a genuine alternative rather than a compromise. Here's the practical breakdown of when this model wins and where trade-offs exist.
Head-to-Head Comparison Matrix:
| Factor | DeepSeek-Coder-V2 | GPT-4-Turbo | Claude 3 Opus | CodeLlama 70B |
|---|---|---|---|---|
| Code Quality | ★★★★★ | ★★★★★ | ★★★★☆ | ★★★☆☆ |
| Context Window | 128K | 128K | 200K | 16K |
| Open Weights | ✅ MIT License | ❌ API only | ❌ API only | ✅ |
| Self-Hostable | ✅ Yes | ❌ No | ❌ No | ✅ Yes |
| Pricing | Free (self-host) / API rates | $0.01/1K tokens | $15/M tokens | Free |
| Speed | Fast (21B active) | Varies | Slower | Medium |
| Language Coverage | 338 languages | Broad | Broad | 86 languages |
| IDE Integration | Manual setup | Excellent | Excellent | Good |
When to choose DeepSeek-Coder-V2 over GPT-4-Turbo:
Data privacy is non-negotiable: If you're working with proprietary codebases in regulated industries (finance, healthcare, defense), sending code to OpenAI's API may be impossible. DeepSeek-Coder-V2 runs entirely on your infrastructure.
Cost at scale: At high volume, self-hosting the 16B variant or even the 236B model can be cheaper than GPT-4-Turbo API costs. The economics flip around 10M+ tokens per month depending on your hardware.
Customization: You can fine-tune DeepSeek-Coder-V2 on your internal codebases, coding standards, and proprietary libraries. GPT-4-Turbo offers fine-tuning but at different price points and constraints.
When GPT-4-Turbo still wins:
Immediate IDE integration: Cursor, GitHub Copilot, and other tools have first-class GPT-4-Turbo integration today. DeepSeek-Coder-V2 requires manual setup through llama.cpp, vLLM, or Ollama.
General reasoning: On general knowledge tasks beyond code, GPT-4-Turbo maintains an edge. DeepSeek-Coder-V2 is specialized.
Ecosystem: The tooling, documentation, and community resources around OpenAI models are currently richer.
The Claude 3 Opus comparison:
Claude 3 Opus still leads on extremely long contexts (200K) and certain reasoning tasks. But DeepSeek-Coder-V2 matches or exceeds it on pure coding benchmarks while being fully open. If Anthropic doesn't release model weights, this gap will widen as the open-source ecosystem builds around DeepSeek-Coder-V2.
Fully Open Weights: Download and Deploy #
You can download the complete model weights right now from HuggingFace under an MIT license — no restrictions, no commercial use limitations, no API keys required. This is a genuine open release, not an API-only "open" announcement.
Download Locations:
| Model | HuggingFace Repo | Size (BF16) | Size (Int8) |
|---|---|---|---|
| DeepSeek-Coder-V2-Lite | deepseek-ai/deepseek-coder-v2-lite-base |
~32GB | ~16GB |
| DeepSeek-Coder-V2-Lite-Instruct | deepseek-ai/deepseek-coder-v2-lite-instruct |
~32GB | ~16GB |
| DeepSeek-Coder-V2 | deepseek-ai/deepseek-coder-v2-base |
~470GB | ~240GB |
| DeepSeek-Coder-V2-Instruct | deepseek-ai/deepseek-coder-v2-instruct |
~470GB | ~240GB |
Self-Hosting Options:
- llama.cpp — CPU inference on consumer hardware (slow but accessible)
- vLLM — Production-grade GPU serving with batched inference
- Ollama — Local development and testing (easiest setup)
- Text Generation Inference (HuggingFace) — Enterprise deployment
- DeepSeek API — If you want to test before committing hardware
Hardware Requirements for the 236B Model:
| Setup | VRAM Required | Hardware Example | Throughput |
|---|---|---|---|
| BF16 Inference | ~470GB | 6x A100 80GB | ~30 tokens/sec |
| Int8 Quantized | ~240GB | 4x A100 80GB | ~25 tokens/sec |
| 16B Lite Model | ~35GB | 1x A100 40GB | ~60 tokens/sec |
| CPU (llama.cpp) | ~240GB RAM | Threadripper + 256GB | ~2 tokens/sec |
The MIT License Means:
- ✅ Commercial use without fees
- ✅ Modification and redistribution
- ✅ Integration into proprietary products
- ✅ Fine-tuning on your data
- ✅ No attribution required (though appreciated)
This is the most permissive license available. Compare to Meta's Llama license which requires reporting for applications over 700M users and has usage restrictions. DeepSeek is betting that openness drives adoption and ecosystem growth faster than closed control.
How DeepSeek Built This #
DeepSeek-Coder-V2 was trained using a continued pre-training approach starting from a DeepSeek-V2 intermediate checkpoint, with 6 trillion additional tokens focused on code and mathematical reasoning. The methodology reveals several technical innovations that explain the breakthrough performance.
Training Data Composition:
Total Training: 10.2T tokens
├── DeepSeek-V2 base: 4.2T tokens (general)
└── DeepSeek-Coder-V2 additional: 6T tokens
├── Source Code: 1,170B tokens (60%)
│ ├── GitHub repositories (pre-Nov 2023)
│ └── CommonCrawl code extraction
├── Math Corpus: 221B tokens (10%)
│ └── Competition math, textbooks, reasoning
└── Natural Language: 1,800B tokens (30%)
└── Sampled from DeepSeek-V2 corpusCode Data Expansion:
The code corpus grew from 86 to 338 programming languages through aggressive language detection and quality filtering. For comparison against the original DeepSeek-Coder corpus, DeepSeek ran ablation studies with 1B parameter models:
| Corpus Version | HumanEval | MBPP | Improvement |
|---|---|---|---|
| Original (86 langs) | 30.5% | 44.6% | Baseline |
| Expanded (338 langs) | 37.2% | 54.0% | +6.7% / +9.4% |
The Alignment Process:
After pre-training, DeepSeek-Coder-V2 underwent a three-stage alignment:
Supervised Fine-Tuning (SFT): Combined instruction data from DeepSeek-Coder, DeepSeek-Math, and DeepSeek-V2 to create a base instruction-following model.
Fill-In-Middle Training: Special training on code completion patterns using the FIM approach — placing a suffix after the cursor and training the model to fill the middle. This enables IDE-style autocomplete behavior.
Reinforcement Learning with GRPO: Group Relative Policy Optimization uses compiler feedback and test case execution results as reward signals. Code that compiles and passes tests gets positive reinforcement; code that fails gets negative feedback.
Architecture Decisions:
The MoE architecture uses a DeepSeekMoE framework with learned routing. Each token is processed by only 21B of the 236B parameters, but different tokens activate different expert combinations. This enables the model to develop specialized experts for:
- Different programming paradigms (OOP vs. functional vs. procedural)
- Specific language syntax and idioms
- Mathematical vs. string manipulation vs. systems programming
The Company Behind the Model #
DeepSeek is a Chinese AI company formally operating as Hangzhou DeepSeek Artificial Intelligence Basic Technology Research Co., Ltd., and they've just released the most capable open-source coding model in the world. This isn't a startup — it's a research lab spun out from High-Flyer, one of China's premier quantitative hedge funds with $8 billion in assets under management.
Key Facts About DeepSeek:
| Aspect | Details |
|---|---|
| Founded | July 2023 (officially), roots trace to High-Flyer's AI research |
| Founder/CEO | Liang Wenfeng, also co-founder of High-Flyer (2015) |
| Location | Hangzhou, Zhejiang Province, China |
| Funding | Backed by High-Flyer's resources, self-funded |
| Focus | Open-source foundation models, specializing in code and reasoning |
Previous Models:
DeepSeek-Coder (Nov 2023): 1.3B to 33B parameter code models trained on 2T tokens, 87 languages. The 33B Instruct variant outperformed GPT-3.5 Turbo on most coding benchmarks.
DeepSeek-V2 (May 2024): The foundation for Coder-V2, featuring the MoE architecture and strong general capabilities.
DeepSeek-Coder-V2 (June 2024): Today's release — 236B MoE, GPT-4-Turbo-level performance.
Why This Matters Geopolitically:
DeepSeek-Coder-V2 is the clearest signal yet that Chinese AI labs are competitive with Western leaders on frontier model development. While US export controls on GPUs have created challenges, DeepSeek has demonstrated that architectural innovations (MoE efficiency) and data curation can compensate for hardware constraints.
The open-source release strategy is notable too. While OpenAI, Anthropic, and Google keep their frontier models closed, a Chinese lab is releasing their best work under MIT license. This complicates simple narratives about AI development and access.
Real-World Coding Performance #
Beyond benchmarks, I've been testing DeepSeek-Coder-V2 today on real development tasks, and the results validate the paper's claims. This isn't just a benchmark champion — it's genuinely useful for production coding work.
Practical Test Results:
| Task | DeepSeek-Coder-V2 236B | GPT-4-Turbo | Notes |
|---|---|---|---|
| Multi-file refactoring | Excellent | Excellent | Both handle cross-file changes well |
| Complex algorithm design | Strong | Strong | Mathematical reasoning pays off |
| Legacy code understanding | Good | Excellent | 128K context helps with large files |
| API integration code | Strong | Strong | Good at following documentation |
| Debug error messages | Good | Excellent | Error analysis slightly behind |
| Code completion speed | ~30 tok/s | Variable | Competitive for self-hosted |
IDE Integration Today:
Unlike GPT-4-Turbo which has first-class support in Cursor, Copilot, and other tools, DeepSeek-Coder-V2 requires manual setup. Here's what's working:
- Continue.dev — Can be configured with custom OpenAI-compatible endpoints
- Ollama — The easiest local setup:
ollama run deepseek-coder-v2 - vLLM + custom tools — For production deployments
- Tabby — Self-hosted Copilot alternative with DeepSeek support
Code Completion Example:
I tested the Fill-In-Middle capability on a TypeScript function:
// Cursor position at █
function calculateMovingAverage(data: number[], window: number): number[] {
if (window > data.length) throw new Error("Window too large");
█
return result;
}The model correctly generated:
const result: number[] = [];
for (let i = window - 1; i < data.length; i++) {
const sum = data.slice(i - window + 1, i + 1).reduce((a, b) => a + b, 0);
result.push(sum / window);
}This level of contextual understanding — generating the loop, handling Type types correctly, and using appropriate array methods — matches what I'd expect from GPT-4-Turbo.
Limitations and Concerns to Watch #
Despite the breakthrough performance, there are limitations and concerns developers should understand before adopting DeepSeek-Coder-V2. No model is perfect, and this one comes with specific trade-offs.
Hardware Requirements:
The 236B model is genuinely expensive to run. At ~470GB in BF16 precision, you need enterprise-grade GPU infrastructure:
- Minimum viable: 4x A100 80GB with Int8 quantization
- Comfortable: 6-8x A100/H100 for BF16 inference
- Alternative: Use the 16B Lite model (~35GB) which still outperforms CodeLlama 70B on many tasks
Safety and Content Policy:
Unlike OpenAI or Anthropic models, DeepSeek-Coder-V2 doesn't have the same extensive safety filtering built in. This is a double-edged sword:
- ✅ More likely to answer coding questions without false refusals
- ⚠️ Less protection against malicious use (generating exploit code, malware)
The model's training data includes public GitHub repositories — which may contain code with security vulnerabilities, deprecated patterns, or problematic implementations. The model can replicate these patterns if not carefully prompted.
Chinese Government Influence:
As a Chinese company, DeepSeek operates under different regulatory constraints than US labs. While the MIT license is clear, future model releases could theoretically be influenced by government directives. The current release is permanent and forkable, but continued development may face geopolitical complications.
Knowledge Cutoff:
Training data ends in November 2023. The model knows nothing about:
- New language features (Python 3.13, TypeScript 5.5+)
- Recently released libraries and frameworks
- Current API documentation
You'll need retrieval-augmented generation (RAG) for up-to-date information.
What This Means for Open AI #
DeepSeek-Coder-V2 represents a fundamental shift in the coding AI landscape — the moment when open-source models became genuinely competitive with closed frontier systems. The implications extend far beyond this single release.
The Competitive Landscape Just Changed:
| Era | Best Open Model | Gap to Closed |
|---|---|---|
| 2023 | CodeLlama 70B | Massive gap |
| Early 2024 | DeepSeek-Coder 33B | Significant gap |
| Today | DeepSeek-Coder-V2 | Closed |
This is the first time an open model has achieved parity with GPT-4-Turbo on coding tasks. The psychological barrier is broken — "open = inferior" is no longer true.
What This Means for Developers:
Real privacy is now possible: Self-host a GPT-4-Turbo-level coding assistant without sending proprietary code to third-party APIs.
Customization at scale: Fine-tune on your internal codebases, coding standards, and proprietary libraries. Build company-specific coding assistants.
Cost control: At sufficient scale, self-hosting becomes cheaper than API calls. More importantly, costs are predictable.
No vendor lock-in: Switch between providers, run multiple models, maintain control over your AI infrastructure.
What This Means for AI Companies:
OpenAI, Anthropic, and Google now face genuine open-source competition on code quality. Their response will likely be:
- Accelerating frontier model development (GPT-5, Claude 4, Gemini 2)
- Building ecosystem lock-in through superior tooling and integrations
- Differentiating on non-code capabilities (multimodal, reasoning, agentic behavior)
The window for closed-source coding models to command premium pricing may be closing. The commodity layer is becoming open-source by default.
The Broader Trend:
DeepSeek-Coder-V2 is part of a larger pattern. Qwen, Llama, Mistral, and now DeepSeek are all pushing open model capabilities forward. The gap to closed models is narrowing across every modality. For developers, this is unequivocally good news — better tools, more choice, lower costs, and genuine control.
FAQ #
What exactly is DeepSeek-Coder-V2? #
DeepSeek-Coder-V2 is a 236B parameter open-source code language model released on June 17, 2024, that achieves GPT-4-Turbo-level performance on coding benchmarks. It uses Mixture-of-Experts architecture where only 21B parameters are active per token, supports 338 programming languages, and operates with a 128K token context window. The model is fully open weights under MIT license.
How does DeepSeek-Coder-V2 compare to GPT-4-Turbo? #
On pure coding benchmarks, they are effectively tied — both achieve 90.2% on HumanEval and 76.2% on MBPP+. DeepSeek-Coder-V2 exceeds GPT-4-Turbo on LiveCodeBench (43.4% vs. ~42%) and comes close on SWE-Bench (18.3% vs. ~22%). The trade-offs are: DeepSeek requires self-hosting infrastructure, while GPT-4-Turbo has better IDE integrations and general reasoning capabilities.
What is MoE architecture and why does it matter? #
MoE (Mixture-of-Experts) means only a subset of the model's parameters process each token — 21B active out of 236B total. This enables massive model capacity without proportional inference cost. The router learns which "expert" networks handle which types of code, allowing specialization. For DeepSeek-Coder-V2, this means GPT-4-scale capability with significantly lower serving costs than a dense 236B model would require.
Can I download and self-host DeepSeek-Coder-V2? #
Yes — complete model weights are available on HuggingFace right now. The 236B model requires ~470GB VRAM for BF16 inference or ~240GB for Int8 quantization. A smaller 16B "Lite" variant requiring only ~35GB VRAM is also available and still outperforms most open alternatives. You can run via Ollama, vLLM, llama.cpp, or other inference engines.
What license is DeepSeek-Coder-V2 released under? #
MIT License — the most permissive open-source license available. This allows unrestricted commercial use, modification, redistribution, fine-tuning, and integration into proprietary products without attribution requirements or usage reporting. Unlike Meta's Llama license, there are no user-count thresholds or usage restrictions.
Who is DeepSeek and where are they based? #
DeepSeek is a Chinese AI research company based in Hangzhou, Zhejiang, founded in July 2023 by Liang Wenfeng. It emerged from High-Flyer, a quantitative hedge fund with $8 billion AUM. Despite being a relatively new lab, they've now released the world's most capable open-source coding model, competing directly with OpenAI, Anthropic, and Google.
What hardware do I need to run DeepSeek-Coder-V2 locally? #
For the 236B model: minimum 4x A100 80GB GPUs with Int8 quantization, ideally 6-8x for comfortable BF16 inference. The 16B Lite model runs on a single A100 40GB or even consumer GPUs with quantization. CPU inference via llama.cpp is possible but slow (~2 tokens/sec) requiring ~240GB system RAM.
How was DeepSeek-Coder-V2 trained? #
Continued pre-training from a DeepSeek-V2 checkpoint on 6 trillion additional tokens (60% code, 10% math, 30% natural language), followed by three-stage alignment. The alignment includes supervised fine-tuning, Fill-In-Middle training for code completion, and reinforcement learning with Group Relative Policy Optimization (GRPO) using compiler feedback as reward signal.
Is DeepSeek-Coder-V2 safe to use for commercial projects? #
Yes — the MIT license explicitly permits commercial use without restrictions. However, standard AI safety considerations apply: the model may reproduce patterns from its training data (including potentially suboptimal or vulnerable code), and it lacks the safety filters built into some commercial APIs. Review generated code carefully, especially for security-sensitive applications.
What programming languages does DeepSeek-Coder-V2 support? #
338 programming languages — expanded from 86 in the original DeepSeek-Coder. This includes all major languages (Python, JavaScript, TypeScript, Java, C++, Go, Rust) and many niche/specialized languages. The expanded language support came from aggressive language detection and quality filtering of 1,170 billion code tokens from GitHub and CommonCrawl.
Can I use DeepSeek-Coder-V2 in my IDE today? #
Yes, but setup requires more effort than GPT-4-Turbo integrations. Ollama provides the easiest path (ollama run deepseek-coder-v2). Continue.dev can be configured with custom endpoints. Tabby supports it for self-hosted Copilot-style completion. Native Cursor/Copilot integration doesn't exist yet but community plugins are emerging rapidly.
What's next for DeepSeek and open coding models? #
DeepSeek will likely continue scaling — expect larger MoE models, longer contexts, and multimodal capabilities. The broader trend is accelerating: open models are catching closed ones across every modality. For coding specifically, we can expect DeepSeek-Coder-V3 within 6-12 months, and competitive pressure will force OpenAI, Anthropic, and Google to either release weights or significantly differentiate on non-code capabilities.
Get Started with AI-Powered Development #
DeepSeek-Coder-V2 proves that GPT-4-Turbo-level coding AI can run on your own infrastructure. This changes everything for teams with privacy requirements, compliance needs, or cost considerations at scale.
But having the right model is only half the battle. The real competitive advantage comes from integrating that model into your development workflow — custom IDE extensions, automated code review pipelines, documentation generation, test case creation, and intelligent refactoring agents.
That's where I come in.
I help engineering teams build production-grade AI coding infrastructure — not just connecting models, but architecting systems that understand your codebase, follow your standards, and integrate with your existing tools. From self-hosted DeepSeek-Coder-V2 deployments to custom agent workflows that handle your specific development patterns.
If you're ready to move beyond off-the-shelf AI tools and build something tailored to your engineering workflow:
Book a 30-minute AI Automation Strategy Call →
We'll look at your current development process, identify the highest-leverage AI integration points, and map out a plan for custom coding agents that actually understand your systems.
Related reading:
- Cursor vs. Claude Code vs. Antigravity: Which AI Editor Actually Wins in Production
- The Complete n8n Masterclass: Building Production AI Workflows
Last updated: June 17, 2024 | Model benchmarks current as of launch date
Related Posts

Claude Code Skills: The Complete Authoring Guide
The definitive guide to authoring Claude Code Skills. Learn how to build reusable agent capabilities that save hours and standardize quality across your projects.
The Agentic Design Stack in 2026: Claude Code, Codex, AI Studio, Antigravity, Cursor, and Stitch Compared
The complete 2026 agentic stack comparison: which AI agent to reach for based on the job—design, build, review, or coordinate.
Antigravity vs. Claude Code: The Multi-Agent IDE Decision Framework for Context-Heavy Builds
The definitive 2-way decision framework for choosing between Google Antigravity and Claude Code on context-heavy builds. When to dump everything vs. scope tightly, and which tool handles browser-use, multi-agent orchestration, and handoffs better.




