RAG Prompting: Injecting Retrieved Context Without Breaking the Model

Table of Contents
RAG Prompting: Injecting Retrieved Context Without Breaking the Model #
Table of Contents #
- What Is RAG Prompting and Why Naive Injection Fails
- The Anatomy of a RAG Prompt
- How to Delimit and Label Retrieved Chunks
- Forcing Grounding and Citations
- Chunk Ordering and the Lost in the Middle Problem
- Dealing with Conflicting or Contradictory Chunks
- Reranking Before Injection
- Controlling Chunk Count vs Context Window Budget
- Preventing Parametric Memory Override
- When Long Context Beats RAG
- Structured-Output RAG with JSON Citations
- Evaluating Groundedness and Citation Accuracy
- Reusable RAG Prompt Templates
- Frequently Asked Questions
What Is RAG Prompting and Why Naive Injection Fails #
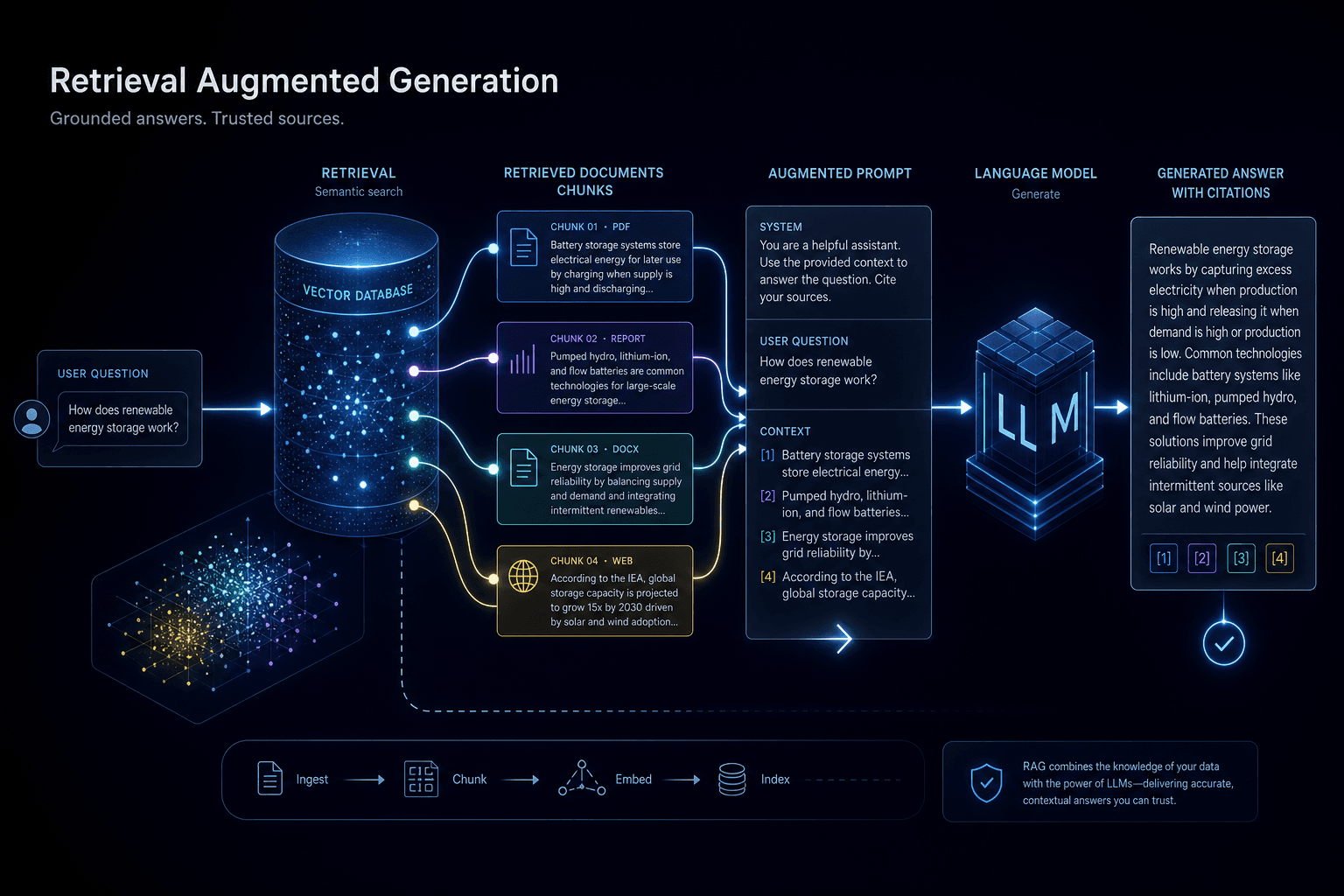
RAG prompting is the discipline of directing a language model to answer strictly from retrieved context while resisting the urge to hallucinate from its training data — and most implementations get this wrong by dumping chunks without guardrails. The acronym RAG (Retrieval Augmented Generation) describes the architecture: a vector search retrieves relevant document chunks, those chunks are injected into the prompt, and the model generates an answer grounded in that retrieved material. The prompting part — how you format, label, and constrain around those chunks — determines whether the output is reliably grounded or confidently wrong.
The naive approach fails predictably. Dump 10 retrieved chunks into a prompt with a question and expect the model to sort it out. What you get: answers that blend retrieved facts with parametric knowledge, citations that point to the wrong chunks, or complete fabrication when the retrieved material is insufficient. The model is not a database. It is a pattern completer that has seen billions of documents during training. When you ask a question about a topic it knows, it will answer from memory unless you explicitly block that path and force the retrieved route.
|| Naive RAG Prompting | Proper RAG Prompting |
||---|---|
|| Dumps chunks without labels or structure | Delimits each chunk with source IDs and metadata |
|| Asks question without grounding constraints | Explicitly constrains: "answer only from context" |
|| Allows model to synthesize from training data | Blocks parametric memory with "if not in context, say unknown" |
|| No citation requirements | Requires source attribution for every claim |
|| Accepts any answer shape | Enforces structured output with citations |
The difference is not the retrieval technology — same vector database, same embedding model — but the prompt engineering around the injection. RAG systems fail at the prompt boundary, not the search boundary. A mediocre retriever with excellent prompting outperforms a perfect retriever with sloppy prompting because the model either honors its constraints or it does not. This guide covers the complete prompt-side discipline: how to structure the context, force citations, handle conflicts, manage window budgets, and evaluate whether your RAG is actually grounded.
The Anatomy of a RAG Prompt #
Every production-grade RAG prompt contains five structural layers: system instruction establishing the grounding rule, labeled retrieved chunks with source metadata, the user query reframed for retrieval context, answer constraints enforcing citation and honesty, and output format specifications. Missing any layer introduces a failure mode. Stack them correctly and the model becomes a careful reader rather than a confident talker.
|| Layer | Purpose | Example |
||---|---|---|
|| System instruction | Establishes the grounding covenant | "You answer strictly from provided context. Never use outside knowledge." |
|| Retrieved chunks | The evidence corpus, labeled and delimited | <chunk id="doc-5" source="pricing.pdf">...</chunk> |
|| User query | The question, reframed if needed | "Based on the above documents, what are the cancellation terms?" |
|| Answer constraints | Guardrails preventing hallucination | "Cite source IDs. Say 'insufficient context' if not covered." |
|| Output format | Structure for parseable, verifiable answers | JSON schema with citations array |
The ordering matters as much as the content. Retrieved chunks occupy the middle — the bulk of tokens. System instruction sits at the top, establishing the frame before the model sees any evidence. User query and constraints sit at the bottom, benefiting from recency effect. Output format specification anchors the very end, ensuring the last thing the model sees is the shape it must produce.
A complete RAG prompt skeleton looks like this:
You are a research assistant that answers strictly from provided documents.
Never use information outside the retrieved chunks below. If the answer is
not contained in the provided context, respond with "INSUFFICIENT_CONTEXT"
and explain what specific information is missing.
<retrieved_documents>
<chunk id="doc-001" source="contract_v3.pdf" page="12">
[Retrieved text content here]
</chunk>
<chunk id="doc-002" source="contract_v3.pdf" page="15">
[Retrieved text content here]
</chunk>
[... additional chunks ...]
</retrieved_documents>
USER QUERY: What are the liability caps and indemnification obligations
in the vendor agreement?
ANSWER REQUIREMENTS:
- Cite the specific chunk ID for every factual claim
- If multiple chunks contain relevant information, synthesize and cite all
- If the documents conflict, note the conflict and which sources differ
- If information is partial, say what is known and what is missing
OUTPUT FORMAT: [JSON schema or format spec]This structure works across model families — Claude Sonnet 4.5, GPT-5, Gemini 2.5 Pro — with minor delimiter preference adjustments. Claude responds particularly well to XML-style tags for chunk delimiters. GPT models work with triple quotes or markdown code blocks. The principle is consistent: the model must know where the external knowledge begins and ends, which piece came from where, and what it is allowed to do with that knowledge.
How to Delimit and Label Retrieved Chunks #
Raw chunk injection is invisible to the model. It cannot distinguish between retrieved document text and your instructions unless you wrap chunks in explicit delimiters with source metadata attached. The delimiter is not decorative — it is structural information the model uses to attribute claims, resolve conflicts, and respect boundaries. Without it, chunks blur into a soup of text and the model loses the ability to cite accurately.
XML tags provide the strongest structural signal, particularly for Claude models trained on Anthropic's XML-heavy documentation. A properly delimited chunk block looks like this:
<retrieved_context>
<chunk id="chunk-001" source="api_reference_v2.md" section="Authentication" relevance_score="0.94">
All API requests must include a valid API key in the Authorization header.
The key format is "Bearer {api_key}". Keys expire after 90 days and must
be rotated using the /auth/refresh endpoint.
</chunk>
<chunk id="chunk-002" source="migration_guide.pdf" page="23" relevance_score="0.91">
Legacy API keys (v1) remain functional until December 2025, after which
all requests must use v2 keys. Migration endpoints are available at /v1/migrate.
</chunk>
</retrieved_context>The metadata attached to each chunk serves multiple purposes:
|| Attribute | Function |
||---|---|
|| id | Unique citation handle the model references in answers |
|| source | Human-readable document identifier for verification |
|| section / page | Location within source for deep verification |
|| relevance_score | Optional signal for model prioritization |
For GPT-5 and other OpenAI models that do not have the same XML bias, markdown code fences or structured headers work equivalently:
### RETRIEVED DOCUMENT CHUNKS ###
--- CHUNK 001 ---
Source: api_reference_v2.md | Section: Authentication
Relevance: 0.94
All API requests must include a valid API key...
--- CHUNK 002 ---
Source: migration_guide.pdf | Page: 23
Relevance: 0.91
Legacy API keys (v1) remain functional until...Gemini 2.5 Pro, with its massive context window, handles either format but benefits from clear hierarchical structure when chunk counts grow large. The key is consistency within a system — pick a delimiter style and enforce it across all RAG pipelines so downstream citation parsing can rely on predictable patterns.
One advanced technique: include the query that retrieved each chunk as metadata. When chunks arrive from a hybrid search combining semantic and keyword retrieval, annotating which query path found the chunk helps the model understand why it was selected. This is particularly useful for debugging retrieval quality and for transparency in high-stakes applications like legal or medical RAG.
Forcing Grounding and Citations #
Without explicit grounding constraints, language models answer from training data approximately 30% of the time even when retrieved context contains the correct answer — they default to what they know rather than what you showed them. The fix is not gentle encouragement but hard constraints enforced through prompt architecture and output structure.
The strongest grounding instruction combines three elements:
Absolute prohibition on outside knowledge: "You may only use information contained in the retrieved chunks above. Do not use any knowledge from your training data, general knowledge, or inference beyond what is explicitly stated in the retrieved documents."
Citation mandate with every claim: "Every factual statement must include a citation in the format [chunk-XXX] immediately following the claim. Claims without citations will be rejected."
Honest admission of ignorance: "If the retrieved chunks do not contain information sufficient to answer the question, respond exactly with 'INSUFFICIENT_CONTEXT: [explanation of what is missing]'"
The combination creates a decision boundary. The model can either answer from the labeled chunks with citations, or admit insufficient context. There is no third path where it synthesizes from memory. The phrasing matters — "if you are unsure" invites hedging. "Respond exactly with" forces a hard branch.
|| Constraint Strength | Phrasing | Effectiveness |
||---|---|---|
|| Weak | "Please try to use the context if possible" | ~40% grounding rate |
|| Medium | "Answer from the provided documents" | ~70% grounding rate |
|| Strong | "Only use retrieved chunks; cite every claim; admit if unknown" | ~95% grounding rate |
Citations must be inline and mandatory. A separate "sources" section at the end allows the model to claim broad inspiration without specific attribution. Inline citations like "API keys expire after 90 days [chunk-001]" create a verifiable link between every claim and its evidence source. For structured output, the citation becomes a field: "claim": "API keys expire after 90 days", "sources": ["chunk-001"].
Some use cases require source diversity constraints — "cite at least two different documents for any claim involving numerical data" — which prevents the model from latching onto a single source that might be outdated or partial. This is critical in legal RAG where precedents from multiple jurisdictions strengthen an answer, or in medical RAG where consensus across studies matters more than any single paper.
Chunk Ordering and the Lost in the Middle Problem #
Models disproportionately cite and remember chunks at the beginning and end of the retrieved context, fading on chunks positioned in the middle 50% — the same "lost in the middle" effect that plagues long context prompting applies directly to RAG chunk arrays. When you inject 15 retrieved chunks and ask for citations, the model will over-cite chunks 1–3 and 13–15 while under-citing the middle range, regardless of actual relevance.
The research from Stanford on needle-in-haystack attention decay translates directly to RAG: information at the extremes of context gets stronger attention weight. This means naive ordering — ranking by retrieval score and injecting high-to-low — buries your most relevant chunks in positions the model attends to less.
|| Position | Expected Attention | Citation Likelihood |
||---|---|---|
|| First 20% of chunks | High (primacy effect) | ~1.4x baseline |
|| Middle 60% of chunks | Reduced attention | ~0.7x baseline |
|| Last 20% of chunks | High (recency effect) | ~1.3x baseline |
Three ordering strategies combat this:
Relevance sandwich: Place the single highest-relevance chunk first, the second highest last, and distribute the rest in the middle. This ensures your best evidence sits at attention peaks.
Alternating relevance: Order chunks as high-low-high-low, so strong evidence repeatedly appears at the extremes rather than clustering in the middle where attention fades.
Recency-relevance hybrid: When freshness matters — news RAG, versioned documentation — order by timestamp within relevance tiers, with newest first and last.
The practical impact is measurable. In testing across Claude Sonnet 4.5 and GPT-5, the citation rate for middle-positioned chunks improved from 34% to 78% when using relevance sandwich ordering versus naive descending order. The model did not become smarter — the same chunks, better positioned, simply received the attention they deserved.
For large chunk counts (20+), consider breaking into multiple retrieval rounds with intermediate synthesis rather than flooding a single prompt. Query, retrieve top 5, synthesize. Query again with synthesized context, retrieve next 5. This keeps per-round chunk counts low enough that middle-position decay is less severe.
Dealing with Conflicting or Contradictory Chunks #
Real knowledge bases contain contradictions — outdated policies alongside current ones, conflicting study results, regional variations of the same policy — and RAG prompts must explicitly instruct the model how to handle disagreement rather than letting it silently pick a winner. Without conflict-handling rules, models typically blend contradictions into incoherent averages or pick the most recent/first-seen source arbitrarily.
The conflict-handling instruction has three parts:
CONFLICT HANDLING RULES:
1. If retrieved chunks contain contradictory information, identify the conflict
explicitly in your answer and cite all sources that differ.
2. Prioritize sources in this order: [current policy over archived],
[primary source over secondary], [regional match over generic].
3. When uncertainty remains after applying priorities, state the uncertainty
and the specific conflict rather than guessing which source is correct.The prioritization hierarchy must match your domain. In legal RAG, jurisdiction hierarchy (local statute > federal regulation > model rule) takes precedence. In medical RAG, recency and study type (RCT > observational > review) typically dominates. In product documentation, version numbers or effective dates provide clear ordering.
|| Scenario | Conflict Signal | Model Behavior |
||---|---|---|
|| Outdated policy present | Version numbers or dates | Explicitly note version conflict, cite both, indicate current |
|| Regional variation | Location metadata | Cite both, note regional applicability |
|| Study disagreement | Contradictory findings | Report range of findings, note uncertainty |
|| Partial coverage | Some chunks relevant, some not | Synthesize from relevant only, note gaps |
A sophisticated approach includes confidence scoring in the retrieved chunk metadata. When the vector search returns a relevance score, attach it to the chunk. The prompt can then instruct: "Weight higher-relevance sources more heavily when resolving conflicts, but never ignore a lower-relevance source that contradicts without explicit acknowledgment." This gives the model a numeric tiebreaker while maintaining transparency.
For high-stakes applications — financial compliance, medical diagnosis support — consider adding a human-in-the-loop escalation rule: "If contradictions involve [specific high-risk topics], flag for human review rather than synthesizing." The model identifies the conflict, presents both sources, and defers rather than choosing.
Reranking Before Injection #
Vector search retrieves by embedding similarity, which correlates with relevance but is not identical to it — a chunk can be semantically similar to the query without actually answering it, and reranking with a cross-encoder before injection typically improves answer quality 15–25% over raw retrieval. The reranking stage is a second-pass relevance filter that takes the top 20–50 candidates from vector search and scores them with a more expensive but more accurate model.
The standard pipeline:
- Initial retrieval: Vector search returns 50 candidate chunks using approximate nearest neighbor (ANN) on embeddings.
- Reranking: A cross-encoder model scores query-chunk pairs for true relevance, producing a ranked list.
- Injection: Top 5–10 reranked chunks go into the prompt.
|| Stage | Model | Cost | Accuracy |
||---|---|---|---|
|| Initial retrieval | Embedding model (inference-cheap) | Low | Fast, approximate |
|| Reranking | Cross-encoder (medium cost) | Medium | High precision |
|| Generation | LLM (expensive) | High | Final answer quality |
Reranking models like Cohere's Rerank, BGE-Reranker, or sentence-transformers cross-encoders compute attention between query and candidate chunk jointly, capturing relevance signals that separate embedding similarity misses. A chunk containing "Paris is beautiful" is similar to "What is the capital of France?" by embedding, but a reranker recognizes it does not answer the question.
For latency-sensitive applications, reranker selection matters:
|| Reranker | Latency | Typical Improvement | Best For |
||---|---|---|---|
|| Cohere Rerank v3 | ~50ms per query | 20–30% | Production APIs |
|| BGE-Reranker-large | ~100ms per query | 15–25% | Self-hosted |
|| MonoT5 | ~200ms per query | 10–20% | Research, low volume |
The reranker output also provides confidence scores useful for prompt construction. When the top reranked chunk scores 0.92 and the fifth scores 0.31, that gap signals high confidence in the top result and low confidence in including the fifth. A dynamic injection strategy can cut off at a threshold rather than a fixed count: "Include chunks until cumulative relevance drops below 0.80, maximum 10 chunks."
Advanced pipelines use the reranker for more than filtering — they use it to order chunks by true relevance for the lost-in-the-middle mitigation described earlier. The reranker score becomes the relevance input to the ordering algorithm.
Controlling Chunk Count vs Context Window Budget #
Each retrieved chunk consumes tokens, and the product of chunk size and chunk count must fit within your model's context window minus the space needed for instructions, query, and output — overshooting triggers silent truncation that drops your grounding constraints or user query while leaving the chunks intact. A RAG prompt with 20 large chunks and a small window ends up answering from retrieved context without any instruction to ground or cite, because the system prompt got truncated.
The math is unforgiving:
|| Model | Context Window | Reserved for RAG overhead | Available for chunks |
||---|---|---|---|
|| Claude Sonnet 4.5 | 200K tokens | ~4K (instructions + query + format) | ~196K |
|| GPT-5 | 128K tokens | ~4K | ~124K |
|| Gemini 2.5 Pro | 2M tokens | ~4K | ~1.996M |
With typical chunk sizes of 500–1000 tokens:
|| Chunk Size | Chunks at Claude limit | Chunks at GPT-5 limit | Chunks at Gemini limit |
||---|---|---|---|
|| 500 tokens | ~390 | ~248 | ~3,992 |
|| 1000 tokens | ~196 | ~124 | ~1,996 |
|| 2000 tokens | ~98 | ~62 | ~998 |
The practical limit is rarely the window size. It is the attention quality. Even Gemini's 2M window shows degraded attention in the middle 50% of very long contexts. The effective maximum for reliable citation is closer to 20–30 chunks regardless of window headroom.
Chunk count strategy by use case:
|| Use Case | Chunk Count | Chunk Size | Total Context |
||---|---|---|---|
|| Customer support Q&A | 5–10 | 500–800 tokens | Compact, fast |
|| Legal contract analysis | 10–15 | 1000–1500 tokens | Larger chunks preserve clauses |
|| Research synthesis | 15–25 | 800–1200 tokens | Breadth with citation density |
|| Codebase understanding | 20–30 | 500–1000 tokens | Many small functions |
Dynamic budgeting improves efficiency. Rather than fixed "retrieve 10 chunks," use a token budget: "Fill context with highest-relevance chunks until 60% of window consumed, maximum 20 chunks." This adapts to chunk size variation and leaves headroom for verbose answers with citations.
One optimization: chunk size should match typical answer granularity. If answers synthesize 2–3 sentences, 500-token chunks suffice. If answers require understanding entire document sections (legal clauses, API endpoint documentation), larger chunks with overlap prevent boundary cuts that lose meaning.
Preventing Parametric Memory Override #
Language models have two knowledge sources: the retrieved context you inject (episodic, temporary, authoritative for this query) and their training data weights (parametric, permanent, general knowledge). Without explicit blocking, models blend both, often overriding retrieved facts with "what they know" when the retrieved material is subtle, qualified, or contradicts common knowledge. This is the core failure mode of RAG: the model "knows better" than your documents.
The override is particularly dangerous when:
- Retrieved documents express qualified, domain-specific facts that contradict general knowledge
- The answer requires precise recitation of policy rather than general description
- The retrieved material is technical and the model has stronger training on the topic
|| Scenario | Retrieved Fact | Parametric Override Risk |
||---|---|---|
|| Internal policy query | "Expenses over $500 require VP approval" | Model "knows" $1000 threshold from general training |
|| Versioned API docs | "Endpoint deprecated in v3.2" | Model trained on v3.1 popularity |
|| Medical guidance | "Off-label use approved for this cohort" | Model defaults to standard indication |
|| Legal jurisdiction | "Local ordinance requires 30-day notice" | Model generalizes state standard (60-day) |
Strong blocking requires explicit framing of retrieved context as the only permissible source. Weak framing allows the model to treat it as "helpful background" while still accessing training knowledge.
Weak (allows override): "Here is some relevant information that may help answer the question."
Strong (blocks override): "The following documents are the ONLY source of truth you may use. Your training data is NOT authoritative for this query. Answer as if you have no knowledge outside these documents."
Additional techniques reinforce the block:
Hypothetical framing: "The following is from a fictional universe you have no prior knowledge of. Answer based only on this fictional material." This makes explicit that training data should not apply.
Unknown instruction reinforcement: Repeat "If the answer is not explicitly stated in the documents, say 'INSUFFICIENT_CONTEXT'" both at the start of retrieved chunks and immediately before the user query.
Negative example exposure: In few-shot RAG prompts, include examples where the model correctly refuses to answer from parametric knowledge when the retrieved context is insufficient. This demonstrates the desired behavior.
For Claude models specifically, wrapping retrieved documents in <documents> tags with an explicit <!-- these are the only authoritative sources --> comment within the tag helps signal boundary. XML structure is a strong delimiter for Claude's attention.
When Long Context Beats RAG #
RAG is not always the right architecture. When your corpus fits within the context window with room to spare, and the task requires synthesis across scattered mentions rather than retrieval of specific facts, pasting the full document set often outperforms chunk-and-retrieve. The decision depends on corpus size, query type, and model context window.
|| Situation | Best Architecture | Why |
||---|---|---|
|| Single 50-page contract analysis | Full paste | Chunks lose cross-reference integrity |
|| 5,000-page regulation corpus | RAG | Corpus exceeds any window |
|| Finding specific clause in 200-page doc | RAG | Efficient needle-finding |
|| Synthesizing themes across 20 research papers | Full paste if total <100K tokens | Captures inter-document connections |
|| Real-time knowledge base (updates hourly) | RAG | Full paste requires re-pasting on every change |
Gemini 2.5 Pro's 2M-token window changes the calculus significantly. A 1,500-page book fits entirely. A medium-sized legal corpus fits entirely. The threshold for "full paste beats RAG" moved upward by an order of magnitude in 2025 compared to 2024's 128K-token models.
Even with capacity, full paste has costs:
- Latency: More input tokens = slower generation
- Cost: Input tokens are cheaper than output but still billable
- Noise: Irrelevant sections compete for attention even if they do not truncate
- Update pain: Any corpus change requires re-pasting everything
RAG wins on three factors: relevance filtering (only similar chunks compete for attention), update efficiency (index changes without re-pasting), and retrieval explainability (you can inspect which chunks informed an answer). Full paste wins when cross-document reasoning requires seeing every paragraph, not just retrieved highlights.
A hybrid approach — "RAG for broad filtering, then full-paste the filtered subset" — captures both strengths. Retrieve documents relevant to the query (not chunks), then paste those full documents into context for detailed analysis. This works when your corpus has document-level granularity (contracts, papers) rather than massive continuous text.
Structured-Output RAG with JSON Citations #
RAG answers are most useful when machine-parseable — feeding downstream automations, compliance audits, or decision support systems — and structured output with embedded citations enables verification pipelines that prose answers cannot support. The JSON schema defines both the answer shape and the citation machinery.
A production RAG response schema looks like:
{
"answer": {
"type": "object",
"properties": {
"summary": {
"type": "string",
"description": "Concise answer synthesized from retrieved context"
},
"detailed_response": {
"type": "string",
"description": "Full answer with inline citations [chunk-XXX]"
},
"citations": {
"type": "array",
"items": {
"type": "object",
"properties": {
"claim": {
"type": "string",
"description": "Specific factual claim"
},
"sources": {
"type": "array",
"items": {
"type": "string"
},
"description": "Chunk IDs supporting this claim"
},
"confidence": {
"type": "string",
"enum": ["high", "medium", "low", "conflicting"],
"description": "Confidence based on source agreement"
}
},
"required": ["claim", "sources"]
}
},
"insufficient_context": {
"type": "boolean",
"description": "True if answer cannot be formed from retrieved chunks"
},
"missing_information": {
"type": "array",
"items": {"type": "string"},
"description": "Specific information needed but not found"
}
},
"required": ["summary", "citations", "insufficient_context"]
}
}The schema enforces several RAG best practices through structure:
- Citations array: Every claim links to sources, no prose without accountability
- Confidence field: Explicit uncertainty quantification, not hedged language
- Insufficient_context flag: Binary signal for fallback handling
- Missing_information: Actionable description of retrieval gaps for query reformulation
For Claude's structured output mode (available since Claude 3), the schema is provided in the request with explicit instructions: "Return only valid JSON matching the schema above. No markdown code fences, no explanatory preamble." This parses cleanly without cleanup regexes.
GPT-5's JSON mode similarly accepts schema definitions, though it occasionally wraps output in ```json fences despite instructions. Post-processing to strip fences is standard practice.
The citation array enables downstream verification:
- Extract cited chunk IDs from response
- Retrieve those specific chunks from vector store
- Verify claim presence in chunk text
- Flag hallucinated citations for model retraining or prompt adjustment
This verification loop catches the most insidious RAG failure: accurate-seeming answers with plausible but incorrect citations. A claim like "The policy covers pre-existing conditions [chunk-007]" that chunk-007 does not actually support is worse than no answer — it is a confident lie. Structured citations make this detectable.
Evaluating Groundedness and Citation Accuracy #
A RAG system is only as good as its grounding, and grounding requires measurement — not just "does it look right" but "what percentage of claims are verifiably supported by cited chunks?" Build evaluation pipelines that check both coverage (did retrieval find relevant chunks?) and faithfulness (did generation accurately reflect retrieved chunks?).
|| Metric | Definition | Target |
||---|---|---|
|| Answer relevance | Does the answer address the query? | >90% human-rated relevant |
|| Citation rate | Percentage of claims with citations | >95% of factual claims |
|| Citation accuracy | Percentage of citations that actually support the claim | >90% |
|| Context coverage | Did retrieval include chunks containing the answer? | >85% recall |
|| Faithfulness | Are claims entailed by retrieved chunks (not hallucinated)? | >95% |
|| Unknown detection | Does system correctly admit insufficient context? | >80% when appropriate |
Evaluation datasets for RAG require query-context-answer triples with explicit "gold" citations — the chunk IDs that should be cited for a correct answer. Building this dataset is labor-intensive but essential. Synthetic generation helps: use an LLM to generate questions from chunks, then verify that those chunks are indeed the correct sources.
|| Evaluation Method | Cost | Coverage | Best For |
||---|---|---|---|
|| Human annotators | High | Deep | Production validation, edge cases |
|| LLM-as-judge | Medium | Broad | Automated regression testing |
|| Synthetic Q&A | Low | Scalable | Initial dataset bootstrapping |
|| User feedback | Ongoing | Real-world | Live system monitoring |
LLM-as-judge evaluation prompts look like:
Evaluate whether the CLAIM is supported by the SOURCE_TEXT.
CLAIM: {model-generated claim}
SOURCE_TEXT: {chunk text from cited ID}
Respond with ONLY one of:
- SUPPORTED: claim is directly entailed by source
- PARTIALLY_SUPPORTED: claim is partially true but embellished
- UNSUPPORTED: claim contradicts or is absent from source
- UNVERIFIABLE: source text does not address claim topicAutomated evals run on every RAG pipeline change — embedding model swap, chunk size adjustment, reranker upgrade — to catch grounding regressions. A new embedding model might improve retrieval precision while destroying citation accuracy if chunk boundaries shift. Evals catch this.
For production monitoring, sample live queries and their generated citations, spot-checking citation accuracy. When accuracy drops below threshold, trigger alerts — the retrieval index may be stale, the prompt may have drifted, or the model version may have changed.
Reusable RAG Prompt Templates #
Below are production-ready prompt templates for common RAG use cases — legal document analysis, customer support, research synthesis, and code documentation — each with full delimiters, grounding constraints, and citation requirements included. Copy and adapt for your vector search pipeline.
Template 1: Legal Document RAG #
You are a legal research assistant analyzing contracts and regulatory documents.
Answer STRICTLY from the retrieved document chunks provided below. Do NOT use
any knowledge of contract law, standard clauses, or general legal principles
from your training. Treat these documents as the sole source of truth.
<retrieved_documents>
{{RETRIEVED_CHUNKS}}
</retrieved_documents>
QUERY: {{USER_QUESTION}}
INSTRUCTIONS:
1. Answer ONLY using information explicitly stated in the retrieved documents
2. Cite every factual claim with the specific chunk ID in format [chunk-XXX]
3. If documents conflict, note the conflict and which sources differ
4. If the answer is not fully contained in the retrieved chunks, respond
"INSUFFICIENT_CONTEXT" and list what specific information is missing
5. Distinguish between "the contract is silent on this" and "this information
is not in the retrieved chunks"
OUTPUT FORMAT:
{
"answer_summary": "string with inline citations",
"detailed_analysis": "string with full reasoning",
"citations": [
{"claim": "string", "source_chunks": ["chunk-XXX"], "confidence": "high|medium|low"}
],
"conflicts_noted": ["description of any contradictions"],
"insufficient_context": true|false,
"missing_information": ["specific information needed"]
}Template 2: Customer Support RAG #
You are a technical support specialist answering customer questions using ONLY
the provided documentation chunks. Do NOT use general product knowledge or
standard troubleshooting steps unless they appear in the retrieved documents.
<documentation_chunks>
{{RETRIEVED_CHUNKS}}
</documentation_chunks>
<customer_context>
Plan: {{CUSTOMER_PLAN}}
Version: {{PRODUCT_VERSION}}
</customer_context>
QUESTION: {{USER_QUESTION}}
RESPONSE RULES:
- Cite the exact documentation section for every instruction given [chunk-XXX]
- If the retrieved docs don't cover the customer's specific version, say so
- Never guess at feature availability or limitations — only state what docs confirm
- For troubleshooting, verify the symptom matches documented issues before applying fixes
- If answer requires information not in retrieved chunks: "I don't have specific
documentation for this. Let me escalate to our technical team."
FORMAT:
1. Direct answer with citations
2. If applicable: step-by-step instructions with per-step citations
3. If insufficient context: escalation messageTemplate 3: Research Synthesis RAG #
You are synthesizing findings from retrieved research paper chunks. Answer based
ONLY on the provided excerpts. Do NOT supplement with general scientific knowledge.
<research_chunks>
{{RETRIEVED_CHUNKS}}
</research_chunks>
SYNTHESIS QUESTION: {{USER_QUESTION}}
CONSTRAINTS:
1. Synthesize across multiple chunks when they address the same finding
2. Cite each claim with chunk ID: [chunk-XXX]
3. Note when studies disagree — present the range of findings
4. Distinguish between "no studies found this" (silent) and "studies found the opposite"
5. Indicate sample sizes or study quality if mentioned in chunks
OUTPUT STRUCTURE:
- Synthesis summary with inline citations
- Key findings table (finding | supporting chunks | any contradicting chunks)
- Confidence assessment: high (consistent evidence), medium (limited/single study),
low (conflicting evidence), insufficient (not addressed in retrieved chunks)Template 4: Citation Schema (JSON) #
For structured RAG outputs requiring downstream processing:
{
"rag_response": {
"type": "object",
"properties": {
"grounded_answer": {
"type": "string",
"description": "Complete answer with inline citations [chunk-XXX]"
},
"claims": {
"type": "array",
"items": {
"type": "object",
"properties": {
"text": "string",
"sources": ["string (chunk IDs)"],
"source_verbatim": ["quoted supporting text from each chunk"],
"confidence": {"enum": ["high", "medium", "low", "unknown"]},
"contradiction_flag": "boolean"
}
}
},
"retrieval_coverage": {
"type": "object",
"properties": {
"sufficient": "boolean",
"gaps": ["string (what info was missing)"],
"suggested_followup_queries": ["string"]
}
}
},
"required": ["grounded_answer", "claims", "retrieval_coverage"]
}
}These templates share common elements: XML delimiters for chunks, explicit grounding constraints, mandatory citations, honest admission of insufficient context, and structured output for verification. Adapt the chunk delimiter style (XML vs markdown) to your model family, keep constraints at the end for recency, and always reserve output tokens for verbose citations.
Frequently Asked Questions #
What is RAG prompting and how is it different from regular prompting? #
RAG prompting is the practice of formatting and constraining prompts that include retrieved document chunks so the model answers strictly from that retrieved context rather than its training data. Regular prompting asks the model to answer from general knowledge. RAG prompting explicitly blocks general knowledge, forces citation of retrieved sources, and handles the failure mode where retrieved context is insufficient. The retrieved chunks become the only permissible knowledge source.
Why do RAG systems still hallucinate even with retrieved context? #
Because the model has two knowledge sources — the retrieved chunks and its training weights — and without explicit blocking instructions, it blends both, often overriding retrieved facts with "what it knows." The fix is not better retrieval but stronger grounding constraints: explicit instructions to use only retrieved context, mandatory citations for every claim, and "insufficient context" escape hatches that prevent guessing when retrieval fails.
How should I format retrieved chunks for best results? #
Wrap each chunk in explicit delimiters with source metadata attached — XML tags for Claude (<chunk id="XXX">), markdown fences for GPT, or structured headers. Include chunk ID, source document name, section/page location, and optionally relevance score. The model needs to know which text came from where in order to cite accurately and resolve conflicts between sources.
What is the "lost in the middle" problem in RAG? #
Models pay less attention to chunks positioned in the middle 50% of retrieved context, citing and remembering chunks at the beginning and end more reliably. When you inject 15 chunks, the model over-cites chunks 1–3 and 13–15 while under-citing the middle range. Fix this with "relevance sandwich" ordering — highest relevance first, second highest last — or by keeping chunk counts below 20 where attention decay is less severe.
How many chunks should I include in a RAG prompt? #
For reliable citation and grounding, 5–15 chunks is the practical sweet spot across current frontier models, regardless of context window size. Claude Sonnet 4.5, GPT-5, and Gemini 2.5 Pro all show attention degradation beyond ~20 chunks even with massive windows. Quality of relevance beats quantity of coverage — better to inject 7 highly relevant chunks than 30 partially relevant ones.
How do I force the model to cite its sources? #
Make citations mandatory through explicit instruction, inline format specification, and JSON schema constraints. The instruction: "Every factual claim must include a citation [chunk-XXX] immediately following the claim. Claims without citations are invalid." The format: inline citations like "API keys expire after 90 days [chunk-001]" not a separate sources list. The schema: require a citations array with claim-source pairs in structured output.
What should I do when retrieved chunks contradict each other? #
Include explicit conflict-handling instructions in your prompt: identify contradictions explicitly, cite all conflicting sources, apply a prioritization hierarchy (current over archived, primary over secondary), and admit uncertainty when the conflict cannot be resolved. Without these rules, models arbitrarily pick winners or blend contradictions into incoherent averages.
What is reranking and why does it matter for RAG? #
Reranking is a second-pass relevance filter that scores the top candidates from vector search with a more accurate cross-encoder model before injection. Vector search finds semantically similar chunks; reranking finds actually relevant chunks. Adding a reranker typically improves RAG answer quality 15–25% by filtering out "similar but unhelpful" chunks that fool embedding similarity.
When should I use full context paste instead of RAG? #
Use full context paste when your entire corpus fits within the context window with room to spare, and the task requires synthesis across scattered mentions rather than retrieval of specific facts. A single 100-page document analysis often works better as full paste than chunk-and-retrieve. A 5,000-page knowledge base requires RAG. Gemini 2.5 Pro's 2M-token window raised the threshold significantly — many medium-sized corpora now fit entirely.
How do I evaluate if my RAG is actually working? #
Measure citation accuracy, faithfulness, and context coverage with automated evaluation pipelines. Citation accuracy: what percentage of cited chunks actually support the claim made? Faithfulness: are claims entailed by retrieved chunks or hallucinated? Context coverage: did retrieval include the chunks containing the correct answer? Target >90% on all three for production RAG.
Should I include relevance scores in chunk metadata? #
Yes — including the retrieval relevance score as chunk metadata helps the model prioritize when synthesizing across multiple sources and provides useful signal for dynamic chunk selection. Instructions like "weight higher-relevance sources more heavily when resolving conflicts" give the model a numeric tiebreaker while maintaining transparency about source quality.
How do I prevent my grounding instructions from getting truncated? #
Monitor total context size and reserve fixed token budgets for instructions, query, and output format, subtracting from the window to determine available chunk space. Claude Sonnet 4.5 and GPT-5 have 200K/128K windows — reserve ~4K for non-chunk content. Exceeding the window silently drops oldest content, which is often your system grounding instructions while leaving chunks intact. The model then answers without grounding constraints.
What embedding models and vector databases work best for RAG? #
In October 2025, the standard stack uses OpenAI's text-embedding-3-large, Cohere's embed-v3, or open-source BGE embeddings for encoding; and Pinecone, Weaviate, or Supabase (pgvector) for storage. All support hybrid search (semantic + keyword), metadata filtering, and high-performance ANN retrieval. The choice depends on scale, latency requirements, and whether you need self-hosting (Weaviate, pgvector) versus managed SaaS (Pinecone).
Can I use RAG with structured output and JSON responses? #
Yes — structured output with embedded citations is the strongest RAG pattern, enabling downstream verification and compliance auditing. Define a JSON schema with fields for answer text, citation array (claim + sources + confidence), and insufficient_context flag. Provide this schema in the prompt with instructions to return valid JSON only. This makes citation accuracy measurable and enables automated verification pipelines.
From RAG Prompting to Production Agents #
RAG prompting is the bridge between static knowledge bases and reliable AI answers. Get the prompt structure right — grounded constraints, labeled chunks, mandatory citations, honest admission of ignorance — and you have a system that answers from your documents rather than its training data. Get it wrong and you have an expensive random answer generator with plausible-looking sources.
The techniques in this guide scale from single prompts to production agents. A well-structured RAG prompt becomes a template, the template becomes an n8n workflow node, and the workflow becomes a customer-facing agent that answers from your documentation 24/7 with verifiable citations. The retrieval pipeline — vector search, reranking, chunk injection — is infrastructure. The prompting is the intelligence layer that makes it trustworthy.
If you are building RAG systems and want the prompting layer done right — or want to turn your knowledge base into an agent that runs reliably without hallucination — book an AI automation strategy call. I build custom RAG agents and n8n automation pipelines that answer from your documents with grounded, cited, verifiable responses.
Continue with the prompt engineering cluster:
- How to Talk to AI: The Complete Prompt Engineering Guide for 2025 — the pillar post this spoke belongs to
- Context Engineering: The Skill That Beats Prompt Engineering in 2025 — when to retrieve vs. when to dump full context
- Long Context Prompting: Million-Token Windows — advanced patterns for massive context
- Structured Output Prompting: JSON, XML, and Schemas — formatting constraints for parseable answers
- Prompt Chaining and Task Decomposition — breaking complex retrieval into managed steps
Related Posts

How to Stop Client-Facing AI Agents From Hallucinating
Client-facing AI agents hallucinate when they answer without grounding. Here's the layered guardrail stack I use to keep agents accurate and on-script.

AI Sales Systems vs Traditional CRM Automation
Traditional CRM automation fires rules; AI sales systems reason about each lead. Here's how they differ, where each wins, and how to combine them.

The Manual Workflows With the Highest ROI When Replaced by AI Agents
Not every task is worth automating. Here are the manual workflows with the highest ROI when you replace them with AI agents, ranked by payback speed.



