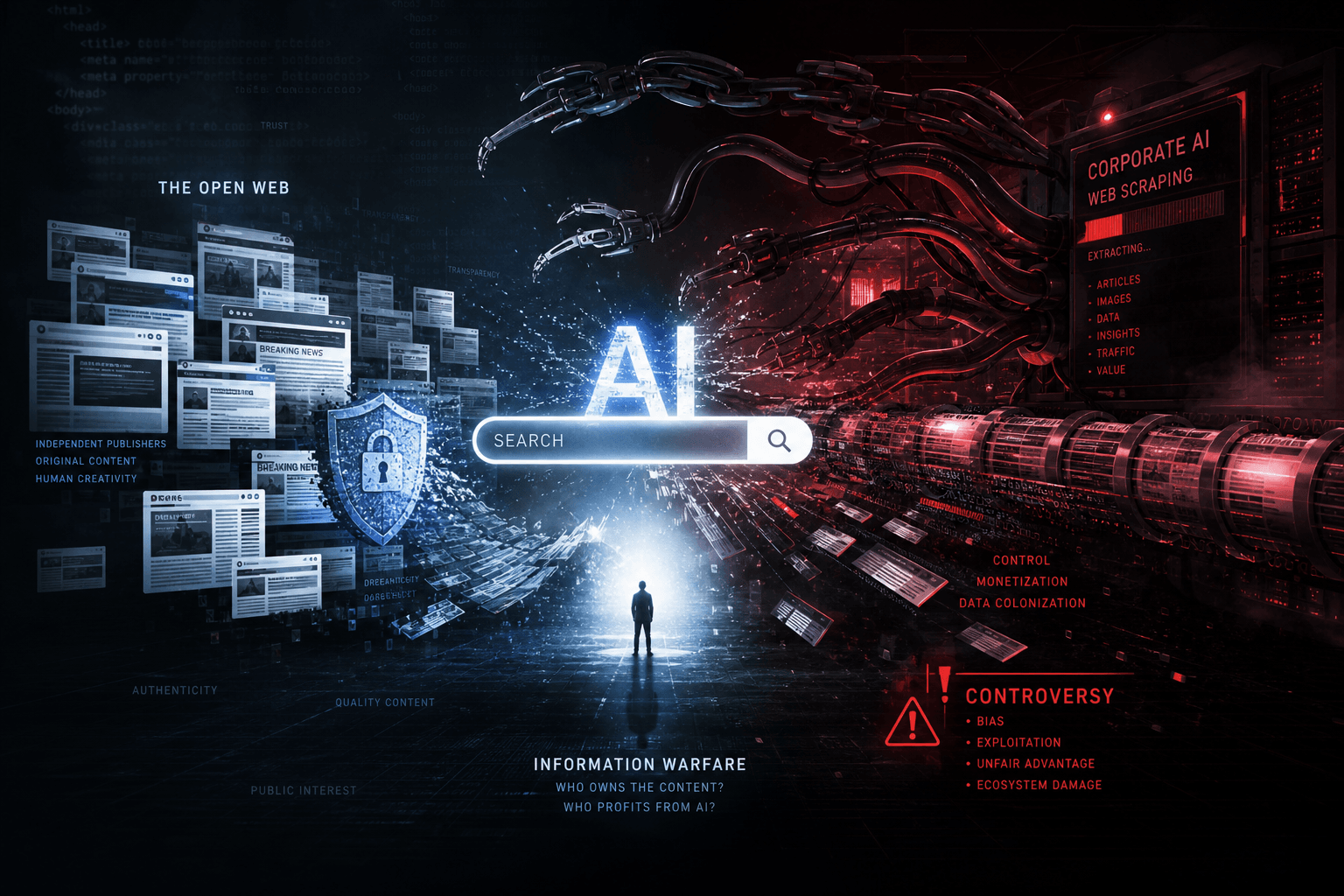
Perplexity AI's SEO Scraping Scandal: Inside the July 2024 Controversy Rocking AI Search

Table of Contents
Perplexity AI's SEO Scraping Scandal: Inside the July 2024 Controversy Rocking AI Search #
The AI search wars just got dirty. This week, Perplexity AI— Silicon Valley's $3 billion darling backed by Jeff Bezos and Nvidia—faces explosive accusations from Forbes and WIRED that it's systematically bypassing robots.txt protocols, plagiarizing investigative journalism, and potentially violating AWS terms of service. As someone building AI automation pipelines daily, I'm watching this unfold with a mix of technical fascination and professional concern.
The story broke in stages: Forbes first, with allegations of direct plagiarism. Then WIRED dropped network forensics evidence of systematic robots.txt violations. Now Amazon Web Services is investigating whether Perplexity breached its hosting terms. The implications stretch far beyond one startup's reputation. This controversy is stress-testing the boundaries of fair use, the enforceability of web standards, and the economic model that funds investigative journalism in the AI era.
Perplexity isn't some fly-by-night operation. As of April 2024, the company was reportedly raising $250 million at a near-$3 billion valuation. It has real users, real revenue, and real engineering talent. That's what makes these accusations so consequential—they suggest that even well-funded AI companies may be building on ethically and legally questionable foundations.
For SEO professionals, content creators, and anyone building AI-powered systems, this case matters. It's a real-time demonstration of what happens when technical capability outpaces ethical frameworks, and it's a preview of the regulatory and legal battles that will define the next decade of AI deployment.
What Happened: The Forbes Accusation That Started It All #
Forbes drops the bomb on Perplexity's content practices. The story begins with a legitimate investigative scoop about Eric Schmidt's secretive AI drone project—and ends with allegations of systematic content theft by a well-funded AI startup.
The Eric Schmidt Drone Story Investigation #
On June 6, 2024, Forbes investigative reporter Sarah Emerson publishes an exclusive story: former Google CEO Eric Schmidt is secretly testing AI-powered military drones in a wealthy Silicon Valley suburb called Woodside. The piece represents weeks of reporting, source cultivation, and verification. It's the kind of original journalism that requires significant investment—exactly the content AI systems are most eager to access.
Within 24 hours, something strange appears. Perplexity Pages— the startup's beta feature for creating "visually stunning, comprehensive content"—has generated a page about Schmidt's drone project. Forbes editor John Paczkowski posts on X (Twitter) with a blunt assessment: "It rips off most of our reporting. It cites us, and a few that reblogged us, as sources in the most easily ignored way possible."
The Perplexity page contains what Forbes describes as "nearly identical wording" to their original scoop. This isn't aggregation with commentary; it's reproduction masquerading as synthesis. And it gathered tens of thousands of views while the journalists who actually did the work received minimal traffic and zero licensing revenue.
Perplexity Pages: The Feature at the Center #
Perplexity Pages launched in May 2024 as part of Perplexity's expansion beyond pure search. The feature promises to help users "turn research into visually stunning, comprehensive content"—essentially auto-generating articles from search queries.
In theory, Pages should create original synthesis. In practice, Forbes found it repackaging their entire investigative report. Perplexity didn't just reference the Forbes story; it reproduced the core narrative structure, key facts, and even included a modified version of Forbes' proprietary design assets—the image Forbes created for their story appeared in Perplexity's version with slight alterations.
The feature has been promoted with examples like "Beginner's Guide to Drumming" and "Steve Jobs: Visionary CEO"—benign content that hides the more problematic use case: reproducing paywalled investigative journalism at scale.
The Attribution Problem #
Forbes' most damning criticism centers on attribution mechanics. Perplexity does cite sources, but the citations appear as "small, easy-to-miss logos" linking to originals rather than meaningful in-text attribution. The Forbes name doesn't appear in the article body; readers consuming the Perplexity version may never realize the content originated with a specific investigative team.
This attribution model matters economically. Perplexity's page gathered tens of thousands of views. Forbes received minimal referral traffic and no licensing fees. The journalists who developed sources, verified facts, and structured the narrative got nothing while Perplexity captured the engagement value.
It's a pattern that, if scaled, threatens the economic model funding the original reporting AI systems depend on. Without revenue, publishers cut investigative budgets. Without investigation, there's nothing for AI to summarize. The feedback loop is obvious—but apparently not obvious enough for Perplexity's leadership to change course preemptively.
WIRED's Technical Investigation: Finding the Smoking Gun #
WIRED deploys network forensics to catch Perplexity red-handed. Their June 19, 2024 investigation provides technical evidence that goes beyond plagiarism accusations to reveal systematic circumvention of web standards.
The AWS Server Connection #
WIRED's investigative team identifies a specific machine tied to Perplexity: an Amazon Web Services server at IP address 44.221.181.252. Network logs show this server actively accessing content across multiple publications including WIRED itself, other Condé Nast properties (Vogue, Vanity Fair), The Guardian, Forbes, and The New York Times.
The critical finding: all these publications explicitly block automated access via robots.txt files. WIRED's robots.txt specifically prohibits scraping for purposes "including but not limited to training machine learning models or artificial intelligence systems." The AWS-hosted Perplexity infrastructure ignored these directives.
This isn't a technical glitch— it's systematic. The IP address shows up repeatedly across disparate publications, all with the same robots.txt instructions, all accessed despite explicit prohibitions.
Developer Robb Knight's Independent Confirmation #
Independent developer Robb Knight provides crucial verification. In a detailed blog post, Knight documents his own investigation into Perplexity's user agent behavior. Using similar methodology to WIRED—monitoring server logs while querying Perplexity with specific URLs—Knight reaches identical conclusions.
Knight's findings eliminate the possibility that WIRED's results were anomalies. Two separate investigators, using different infrastructure, observe the same behavior: Perplexity accessing content from URLs that publishers have explicitly marked as off-limits to automated systems.
The independent verification matters because Perplexity's initial response suggested the Forbes incident was an isolated edge case. Knight's work proves it's systemic—a fundamental aspect of how Perplexity operates.
The Dummy Website Test #
WIRED creates a controlled experiment: a "dummy website" with minimal, trackable content designed specifically to test Perplexity's behavior. The test produces the most damning evidence yet.
When WIRED reporters provide the dummy website URL to Perplexity, the system visits the site (confirmed via server logs) and returns content. But here's the critical finding: for the controlled test site, Perplexity returns text "verbatim" from the page rather than a transformed summary.
This demonstrates that Perplexity isn't always synthesizing information through its LLM layer— sometimes it's directly reproducing source material. The distinction between summarization and reproduction is legally significant. Direct reproduction without transformation is much harder to defend under fair use doctrine.
The dummy website test also controlled for other variables. Because WIRED created the content, they knew exactly what was on the page. They could verify that Perplexity's output wasn't just similar—it was identical in places. This controlled evidence is stronger than the Forbes observation because it eliminates any claim that similarities were coincidental or derived from common source material.
AWS Investigates: The Hosting Provider Takes Action #
Amazon Web Services launches formal investigation into its own customer. The cloud provider hosting Perplexity's infrastructure is reviewing whether the startup violated AWS terms of service—a development that puts Perplexity's technical foundation at risk.
AWS Terms of Service Implications #
AWS maintains terms of service that prohibit customers from using infrastructure for "abusive or illegal activities." While these terms are broadly written, systematic robots.txt violations combined with potential copyright infringement create plausible grounds for enforcement.
An AWS spokesperson confirms the investigation is ongoing: "AWS routinely investigates reports of abuse and takes appropriate action based on the findings. Customers must comply with our terms of service." The statement is standard AWS language, but the fact they're commenting at all signals this isn't a routine inquiry.
The terms of service angle matters because it creates a secondary enforcement mechanism beyond copyright law. Even if Perplexity's content practices survive legal challenge, AWS could determine they violate acceptable use policies. Cloud providers have broad discretion to terminate customers—discretion that can be exercised faster than legal proceedings.
The IP Address Evidence #
IP address 44.221.181.252 becomes the smoking gun connecting Perplexity to specific scraping incidents. Network logs from multiple publishers trace unauthorized access to this AWS-hosted server. The IP is registered to AWS infrastructure, and traffic patterns match Perplexity's operational behavior.
This technical evidence is difficult to dispute. IP addresses don't lie. The combination of AWS registration, Perplexity-specific traffic patterns, and documented robots.txt violations creates a compelling case that Perplexity's infrastructure is systematically accessing content publishers have marked as prohibited.
Potential Consequences for Perplexity #
Losing AWS hosting would be operationally catastrophic for Perplexity. Real-time AI search requires substantial compute resources, low-latency networking, and geographic distribution. Migrating away from AWS mid-scandal would be technically challenging and reputationally damaging.
The investigation threat alone creates strategic pressure. Perplexity must now manage crisis communications, legal defense, and technical compliance simultaneously—all while trying to close funding rounds at a $3 billion valuation. Each day the controversy continues erodes the growth narrative that justifies that valuation premium.
There's also competitive risk. AWS offers its own AI services (Amazon Bedrock, Q). If Perplexity is deemed to have violated terms, it creates both a compliance precedent and a potential competitive signal. AWS has no incentive to protect a customer competing with its own AI products while generating legal liability.
Perplexity's Defense: The Technical Arguments #
Perplexity denies wrongdoing but makes some telling admissions. Their defense hinges on semantic distinctions that publishers view as "without a difference." The response reveals both legal strategy and technical architecture.
The "Summarizing vs. Crawling" Defense #
Perplexity head of business Dmitry Shevelenko provides the company's core defense to TechCrunch: there's a fundamental difference between crawling and summarizing. Shevelenko defines crawling as "going around sucking up information and adding it to your index." Perplexity, he argues, doesn't crawl—it responds to specific user requests.
"We're just responding to a direct and specific user request to go to that URL," Shevelenko states. Under this framework, Perplexity isn't an autonomous scraper—it's a user agent, acting on behalf of humans who explicitly ask it to retrieve information.
The distinction has some technical basis. Traditional search engines like Google operate crawlers that systematically traverse the web, indexing content for later retrieval. Perplexity claims to operate differently: accessing content only when processing specific user queries. The robots.txt protocol was designed for autonomous crawlers; its applicability to on-demand retrieval is legally untested.
However, publishers reject this framing. To WIRED and Forbes, accessing a URL and extracting content thousands of times daily looks functionally identical to crawling. The fact that each access is "user-initiated" doesn't change the systematic, automated nature of the extraction.
CEO Aravind Srinivas Acknowledges Third-Party Crawlers #
In a critical admission that complicates the defense, CEO Aravind Srinivas confirms Perplexity uses third-party web crawlers alongside its own PerplexityBot. This disclosure raises questions about which crawler is responsible for specific violations and whether Perplexity fully controls its content acquisition pipeline.
Srinivas also acknowledges Perplexity has "rough edges" while defending the company's fundamental right to summarize web content. It's a combination of concession and defiance—admitting imperfect implementation while asserting legal and ethical legitimacy.
The third-party crawler admission matters because it suggests Perplexity may not have direct visibility into all scraping activity. If third-party services handle some content retrieval, Perplexity's ability to guarantee robots.txt compliance is inherently limited. This creates both legal exposure and operational risk.
The Robots.txt Loophole Argument #
Most critically, Perplexity admits PerplexityBot will ignore robots.txt when users include specific URLs in queries. This isn't a secret discovered by investigators— it's acknowledged company policy. The logic: robots.txt governs autonomous crawling, not user-directed access.
A Perplexity spokesperson confirms this behavior to WIRED: PerplexityBot respects robots.txt for autonomous crawling but ignores it when processing URLs users explicitly provide. This creates a massive loophole where prohibited content remains accessible through the simple expedient of user query formulation.
Publishers view this as sophistry. The Robots Exclusion Protocol's purpose is preventing automated access to content. Whether the automation is "autonomous" or "user-directed" makes no practical difference to publishers bearing the server load and losing the traffic. The legal system hasn't ruled on this distinction; Perplexity is essentially running a live test case with its own liability as the stakes.
The Technical Reality: How Perplexity Actually Works #
Understanding the architecture reveals why this controversy matters. Perplexity isn't a traditional search engine— it's an answer engine with fundamental architectural differences that have profound implications for content rights.
Perplexity's Architecture vs Traditional Search #
| Aspect | Traditional Search (Google) | Perplexity AI |
|---|---|---|
| Output | Link list with snippets | Direct synthesized answers |
| Content use | Indexing for retrieval | Real-time extraction + LLM synthesis |
| robots.txt compliance | Respects for crawling | Claims exemption for "user requests" |
| Attribution | Prominent links to sources | Embedded citations in generated text |
| Business model | Ad-supported links | Subscription + upcoming ads |
| Publisher traffic | Drives clicks to sources | Potentially substitutes for visiting sources |
| Content access pattern | Batch crawling, indexed storage | On-demand extraction per query |
The architecture difference explains why Perplexity creates friction where traditional search doesn't. Google indexes content, then serves search results that typically drive traffic to publishers. Perplexity extracts content per-query, synthesizes answers, and may satisfy user information needs without referral traffic.
Real-Time Extraction vs. Pre-Indexed Content #
Google's model involves batch crawling: systematically traversing the web, storing content in massive indexes, then serving search results from those indexes. Publishers can monitor crawl rates, understand indexing patterns, and predict traffic impacts. The model, while imperfect, provides transparency.
Perplexity's real-time extraction model operates differently. Each user query can trigger fresh HTTP requests to publisher servers. There's no indexing layer separating query processing from content access. When a user asks about a specific Forbes article, Perplexity may request that article in real-time, extract content, process it through an LLM, and return a synthesized answer.
This architecture has technical advantages— Perplexity can access information Google hasn't indexed yet. But it creates constant, unpredictable load on publisher infrastructure and offers no mechanism for publishers to manage or monitor access. Every query is a potential scraping event.
The LLM Synthesis Question #
Perplexity doesn't train its own foundational models. Instead, it uses commercially available LLMs— primarily OpenAI's models—to transform extracted content into answers. This creates a complex liability chain: when Perplexity reproduces copyrighted text, who bears responsibility?
The LLM synthesis layer was supposed to provide legal protection. The theory: if an LLM genuinely transforms input into original output, the result is fair use regardless of input copyright status. But WIRED's dummy website test suggests transformation isn't always happening—sometimes content passes through essentially unchanged.
This creates potential liability for multiple parties. Perplexity selected and configured the system. OpenAI built the model that produced the output. The user initiated the query. Courts haven't determined how responsibility distributes across this chain. Perplexity's legal position depends on convincing authorities that the LLM layer provides sufficient transformation to qualify as fair use—a claim the verbatim reproduction evidence directly contradicts.
Fair Use vs. Copyright Infringement: The Legal Battleground #
The controversy exposes fundamental gaps in copyright law for AI applications. No clear precedent exists for AI-powered search summarization. The courts haven't determined where fair use ends and infringement begins in the context of automated content transformation.
The Four Factors Test Applied to AI Search #
U.S. copyright law evaluates fair use through four statutory factors. Each creates interpretive challenges when applied to AI search:
| Factor | AI Search Application | Publisher Argument | Perplexity Counter |
|---|---|---|---|
| Purpose & character | Transformative summarization | Commercial competition with original | Information access service |
| Nature of work | Factual news (favors fair use) | Investigative journalism (creative effort) | Facts aren't copyrightable |
| Amount used | "Minimal necessary" extraction | Often substantial reproduction | Only what's needed for synthesis |
| Market effect | Potential traffic driver | Substitute for visiting original | Improves information access |
The factor analysis produces no clear winner. AI search is arguably transformative— creating something functionally different from the original articles. But it's also commercial and potentially substitutive. The "nearly identical wording" Forbes documented pushes the third factor toward publisher advantage.
The "Expression vs. Facts" Distinction #
UCLA law professor Mark McKenna provides the clearest legal framework for understanding the controversy. The critical distinction: facts aren't copyrightable, but expression is. "Nobody has a monopoly on facts," as Perplexity's Shevelenko notes. But the arrangement, selection, and presentation of facts—the expression—is protected.
Perplexity's vulnerability lies in how closely their summaries mirror original text structure and wording. When WIRED observed Perplexity reproducing sentences verbatim, that crossed from fact-use to expression-reproduction. The legal question becomes whether AI systems that sometimes reproduce verbatim and sometimes synthesize can claim fair use protection for the entire output category.
McKenna's analysis highlights the lack of "bright lines" in this area. Courts would examine whether summaries use "actual expression and text" versus "just facts and ideas." The more expression included, the more the activity "starts to look like reproduction, rather than just a summary." Perplexity's verbatim reproduction incidents suggest they're operating in legally dangerous territory.
Why Publishers Fear the "Substitution Effect" #
The core publisher concern transcends legal technicalities: if AI answers provide complete information, users never visit source sites. This is the "substitution effect"—AI search becomes a substitute for original journalism rather than a discovery mechanism for it.
Substitution kills the economic model. Publishers fund investigative reporting through advertising and subscriptions. Both require user visits. If Perplexity extracts the value of reporting while capturing the engagement, original reporting becomes economically unsustainable.
The feedback loop is obvious but apparently insufficient to motivate voluntary restraint. Less revenue means fewer journalists. Fewer journalists means less original reporting. Less original reporting means less source material for AI systems to summarize. Eventually, AI search becomes an ouroboros consuming its own tail—synthesizing synthetic summaries of already-synthesized content.
Publishers see the Perplexity controversy as existential. It's not about one story or one company—it's about whether the AI era will include economic incentives for the original reporting that makes informed societies possible.
The Broader AI Search Ethics Landscape #
Perplexity isn't alone— the entire AI search sector faces scrutiny. But the competitive landscape reveals dramatically different approaches to content rights, with Perplexity increasingly isolated in its aggressive stance.
Comparison Table: AI Search Engines and Scraping Practices #
| Platform | robots.txt Compliance | Content Deals | Attribution Method | Publisher Relations |
|---|---|---|---|---|
| Perplexity | Violates (per WIRED) | None announced | Minimal citations | Active conflict |
| OpenAI/ChatGPT | Claims compliance | Axel Springer, The Atlantic, others | Prominent source links | Partnership approach |
| Google SGE | Respects | Licensing discussions ongoing | Traditional search links | Active negotiation |
| Anthropic Claude | Claims compliance | None specific | Source highlighting in UI | Neutral/cautious |
| You.com | Unknown | Limited deals | Standard citation links | Limited conflict |
| Microsoft Copilot | Respects | Licensing discussions | Source attribution | Partnership exploration |
The table reveals a strategic divergence. The major players—OpenAI, Google, Microsoft—are pursuing partnership models involving licensing discussions and revenue sharing. Perplexity alone appears to be pursuing an extraction model: using content without negotiation and litigating disputes as they arise.
OpenAI's Partnership Strategy vs. Perplexity's Aggressive Approach #
While Perplexity generates headlines for conflict, OpenAI has been systematically signing content deals. The Axel Springer partnership (December 2023) provides access to current and archival content from Bild, Welt, and other publications. The Atlantic deal (May 2024) follows similar terms—payment for content access with prominent attribution.
These deals aren't charity—they're strategic positioning. OpenAI recognizes that sustainable AI requires sustainable content sources. Publishers with viable economic models continue producing the original reporting that differentiates quality AI outputs from synthetic nonsense.
Perplexity's approach inverts this logic. Rather than building partnerships, they're building user base and revenue first, potentially settling with publishers later from a position of strength. It's the classic "move fast and break things" strategy applied to content rights—with the difference that "things" in this case are the economic foundations of journalism.
The divergent approaches create a natural experiment. If OpenAI's partnership model produces comparable or superior results without legal conflict, Perplexity's extraction strategy becomes harder to justify economically. The market will ultimately determine which approach is sustainable, but the regulatory and legal overhead of Perplexity's position may prove prohibitive regardless of user adoption.
The robots.txt Protocol: Technical Standard vs. Legal Requirement #
The Robots Exclusion Protocol operates in an unusual legal space. It's a voluntary technical standard, not a legally binding requirement. No statute mandates robots.txt compliance. However, systematic violations can create liability through other mechanisms:
- Computer fraud statutes: Unauthorized access to protected computer systems
- Terms of service violations: Breach of website terms prohibiting scraping
- Copyright infringement: Reproduction of protected works without authorization
- Trespass to chattels: Interference with server resources (less commonly invoked)
The voluntary nature of robots.txt has led some AI companies to treat it as optional guidance rather than mandatory constraint. Perplexity's defense—that robots.txt doesn't apply to user-directed access—pushes this interpretation to its logical extreme.
However, the standard's voluntary nature doesn't mean it's meaningless. robots.txt represents a consensus mechanism for managing automated access to web resources. Systematic violation undermines the cooperative infrastructure that makes scalable web operation possible. Legal or not, respecting robots.txt is a baseline expectation for legitimate web participants.
What This Means for SEO Professionals and Content Creators #
The Perplexity scandal reshapes how we think about content protection. The techniques and assumptions that governed the Google era are inadequate for AI search. Here's what practitioners need to implement today.
Immediate Actions for Content Protection #
The Perplexity controversy proves that robots.txt alone is insufficient. Content creators need layered protection:
Technical Measures:
- Implement rate limiting at the server/CDN level to throttle aggressive scrapers
- Deploy bot detection systems that identify headless browsers and automated tools
- Monitor server logs for suspicious patterns—repeated requests from AWS IP ranges, unusual user agents
- Consider requiring JavaScript execution or CAPTCHA challenges for high-value content
- Use fingerprinting techniques to identify repeat offenders for blocking
Legal/Administrative Measures:
- Audit terms of service to explicitly prohibit AI training and summarization scraping
- Document scraping violations with timestamps and server logs for potential legal action
- Register copyright for high-value investigative content to strengthen enforcement options
- Consider paywalls or authentication for premium content that shouldn't be freely scraped
Strategic Measures:
- Evaluate whether public-by-default content models remain appropriate
- Consider API-first distribution where you control access and attribution
- Build direct audience relationships through newsletters and apps that bypass search intermediation
The Shifting SEO Value Proposition #
| Traditional SEO | AI Search Era SEO |
|---|---|
| Optimize for ranking | Optimize for citation |
| Click-through traffic | Answer panel inclusion |
| Meta descriptions | AI-readable structured data |
| Backlinks | AI attribution links |
| Keyword density | Semantic entity coverage |
| Page speed for ranking | Page speed for user retention |
| Index coverage | Control over indexing |
The fundamental shift: traditional SEO assumed search engines would send traffic to your site. AI search assumes search engines will extract value from your site without necessarily sending traffic. SEO strategy must adapt to optimize for visibility within AI answers rather than just rankings that generate clicks.
Why Original Reporting Becomes More Valuable #
Paradoxically, AI search may increase the value of original reporting while decreasing the value of commoditized content. Here's why: AI systems fundamentally require source material. They can't synthesize what doesn't exist. The creators who produce genuine scoops, original analysis, and investigative breakthroughs become critical infrastructure for the AI ecosystem.
This creates strategic leverage for original content creators. While Perplexity may resist paying for commodity content, they can't operate without access to quality sources. Publishers with exclusive investigative capabilities— Forbes, The New York Times, WIRED— have negotiating power that generic content farms don't.
For SEO practitioners, this suggests a strategic pivot. The content that ranks well in AI search isn't necessarily the content that ranks well in traditional search. Original insight, unique data, and exclusive reporting become differentiation factors that both humans and AI systems prioritize. The "content is king" cliché takes on new meaning: original content isn't just valuable for audience engagement—it's essential for AI system operation.
Industry Reactions and Expert Analysis #
The controversy generates intense debate across media and tech. The reactions reveal strategic positioning that will shape how the conflict resolves.
Publisher Industry Response #
The News Media Alliance, representing over 2,200 North American news organizations, immediately seizes on the Perplexity case as evidence for stronger content protection. CEO Danielle Coffey issues statements connecting the Perplexity controversy to broader legislative priorities including the Journalism Competition and Preservation Act and various state-level AI transparency proposals.
Individual publishers are less vocal publicly—likely because they're engaged in private negotiations or considering legal options. The Condé Nast properties (WIRED, Vogue, Vanity Fair) have obvious legal standing given WIRED's documented evidence. Forbes has both the plagiarism claims and the reputational incentive to pursue redress.
The publisher community views Perplexity as a test case. If Perplexity faces significant legal or financial consequences, it establishes precedent for content licensing requirements. If Perplexity escapes meaningful sanction, it signals that extraction models can operate with minimal risk. The stakes extend far beyond one startup's fate.
The VC and Startup Ecosystem Position #
Venture capital's response is more nuanced than expected. Despite the escalating controversy, Perplexity continues raising capital. The bet: regulatory and legal challenges won't significantly slow AI search adoption, and first-mover advantage in AI search is worth considerable legal risk.
The calculation is straightforward. A $3 billion valuation implies expectations of massive scale. If Perplexity settles with publishers for tens of millions down the line, that's a rounding error if they've captured significant market share. The Uber playbook—grow first, comply later, settle if necessary—translates directly to AI content conflicts.
However, the AWS investigation introduces uncertainty cloud providers haven't figured into the model. If cloud providers become enforcement points for scraping compliance, the growth-first strategy faces infrastructure-level constraints that venture capital can't easily solve.
SEO Industry Divides #
SEO professionals split into two camps. The "opportunity" camp sees AI search optimization as the next frontier—figuring out how to ensure content gets cited in AI answers, optimizing for answer panel inclusion, and building technical infrastructure that AI systems can reference effectively.
The "existential threat" camp views Perplexity's behavior as symptomatic of a broader dynamic that undermines the content ecosystem. If AI systems extract value without generating traffic, the economic model funding content creation collapses. Without content creation, there's nothing for AI to summarize. This camp advocates for defensive measures—aggressive robots.txt enforcement, litigation, and technical barriers to extraction.
The division maps roughly onto business model differences. SEO practitioners serving publishers and content creators lean defensive. Those serving AI-native applications or working on AI search optimization lean opportunistic. The fundamental disagreement is whether AI search expands the information ecosystem or extracts value from it until collapse.
Technical Deep Dive: Detecting and Blocking AI Scrapers #
For practitioners wanting to protect their content, here's the technical reality. Current protection mechanisms have significant limitations against sophisticated AI scraping operations.
Current robots.txt Limitations #
The standard robots.txt implementation assumes good-faith compliance:
User-agent: PerplexityBot
Disallow: /
User-agent: *
Disallow: /premium/
Disallow: /api/This directive works when bots voluntarily respect the protocol. Perplexity's admission that they ignore robots.txt for user-requested URLs reveals the fundamental weakness: robots.txt is a social contract, not an enforceable technical barrier. It relies on bot operator honesty in an environment where honesty may conflict with competitive imperatives.
The protocol's design reflects a different era—when search engines were cooperative infrastructure, not competitive threats. Modern AI scraping operates at different scale and with different incentives than the 1990s crawlers robots.txt was designed to manage.
Advanced Bot Detection Techniques #
Modern content protection requires behavioral analysis that goes beyond user agent strings:
Request Pattern Analysis:
- Frequency: Legitimate users don't request 100 pages/second
- Timing: Automated systems often show regular intervals between requests
- Sequencing: Scrapers follow predictable traversal patterns (alphabetical, chronological)
- Referrer anomalies: Missing or suspicious referrer headers
JavaScript Execution Testing:
- Headless browser detection via JavaScript challenge/response
- Canvas fingerprinting to identify automated browsers
- Execution timing analysis—headless browsers often execute faster than human-driven ones
Fingerprinting and Reputation:
- IP range analysis—identifying cloud provider IP blocks associated with scraping
- Browser fingerprinting to recognize repeat offenders across sessions
- TLS fingerprinting to identify automated request libraries
Behavioral Biometrics:
- Mouse movement patterns (for interactive content)
- Scroll behavior analysis
- Time-on-page metrics—scrapers often extract and exit rapidly
Rate Limiting and Access Control Strategies #
Effective protection requires layered defense:
Progressive Rate Limiting:
- Tier 1: Soft limits (requests/second) with gentle throttling
- Tier 2: Hard limits for persistent offenders
- Tier 3: Temporary blocks for clear abuse
- Tier 4: Permanent bans for confirmed malicious actors
CAPTCHA Integration:
- Trigger CAPTCHA challenges when behavioral signals indicate automation
- Use modern CAPTCHA (reCAPTCHA v3, hCaptcha) that minimize user friction for legitimate users
- Consider proof-of-work challenges that impose computational cost on scrapers
Geo-Fencing and IP Management:
- Block or throttle known problematic IP ranges (specific AWS/Azure/GCP blocks associated with abuse)
- Implement geo-fencing for content that should be geographically restricted
- Use CDN-level blocking to prevent requests from reaching origin servers
API-First Architecture:
- Move high-value content behind authenticated APIs
- Implement granular access controls and rate limits at the API gateway
- Require API keys that can be revoked for abuse
- Use OAuth or similar authentication that imposes higher friction on automated access
The uncomfortable reality: sophisticated AI scrapers like Perplexity will likely penetrate standard protections. The goal isn't perfect prevention—it's increasing extraction cost to the point where licensing becomes economically rational.
The Future of AI Search and Content Rights #
This controversy marks an inflection point. The resolution will establish precedent shaping AI search economics for the next decade.
Potential Regulatory Responses #
Lawmakers in multiple jurisdictions are already considering AI content legislation that would fundamentally change the landscape:
US Federal Level:
- The Journalism Competition and Preservation Act would allow publishers to collectively negotiate with AI platforms
- Proposed AI transparency requirements would mandate disclosure of training data sources
- Copyright Office review of AI and fair use is ongoing with preliminary indications that more licensing may be required
State Level:
- California's proposed SB 1047 includes provisions on AI training data transparency
- New York is considering legislation requiring AI systems to identify training sources
- Illinois has introduced bills on biometric data and AI training that may expand to content
International:
- EU AI Act includes transparency requirements for training data
- UK's proposed text/data mining exception remains under review
- Japan's flexible AI copyright approach is being reconsidered
The most likely near-term outcome: mandatory disclosure and revenue-sharing requirements for AI systems using publisher content. The Perplexity case accelerates these regulatory timelines by demonstrating what happens without clear rules.
Business Model Evolution: Licensing vs. Scraping #
The industry is bifurcating into two distinct models:
Partnership Model (OpenAI, emerging Google/Microsoft):
- Proactive licensing deals with publishers
- Revenue sharing agreements
- Transparent attribution mechanisms
- Higher upfront costs, lower legal risk
- Better relationships with content sources
Extraction Model (Perplexity):
- Use content without negotiation
- Handle disputes as they arise
- Minimize upfront costs
- Maximum legal and reputational exposure
- Competitive friction with publishers
The market will determine which model prevails, but several factors favor partnership:
- Regulatory pressure is increasing globally
- Publisher consolidation through collective bargaining increases negotiating power
- Legal precedent from early cases likely favors content creators
- Cloud provider enforcement creates infrastructure-level constraints
- Reputational costs affect enterprise adoption
The question isn't whether licensing becomes standard—it's how quickly extraction models can pivot before legal and regulatory costs exceed growth benefits.
What Publishers Should Demand #
Sustainable AI search requires a new social contract between content creators and AI systems:
Economic Terms:
- Revenue sharing for content used in AI training and inference
- Fair compensation models that reflect content value (exclusive investigative work deserves premium rates)
- Transparent reporting of content usage frequency and value generated
Attribution Requirements:
- Clear, prominent attribution in AI outputs
- Direct links that drive traffic to source sites
- Source identification that helps users distinguish original from derivative
Technical Standards:
- Respect for robots.txt and emerging technical protection protocols
- Standardized APIs for licensed content access
- Rate limiting and access controls that protect publisher infrastructure
Governance Mechanisms:
- Dispute resolution procedures for attribution and compensation disagreements
- Audit rights to verify compliance
- Termination rights for systematic violations
The publishers who secure these terms will participate in the AI ecosystem on favorable terms. Those who don't will face extraction without compensation until they're eventually forced into defensive postures that may limit their reach.
FAQ: Perplexity AI Scraping Controversy #
What exactly is Perplexity accused of doing? #
Perplexity faces accusations of systematically bypassing robots.txt protocols, plagiarizing investigative journalism, and republishing content without proper attribution. Forbes documented Perplexity Pages republishing their exclusive reporting with "nearly identical wording." WIRED's technical investigation identified Perplexity servers hosted on AWS (IP 44.221.181.252) accessing content from publications including Forbes, The Guardian, and The New York Times that explicitly block automated scraping via robots.txt. The investigation also revealed Perplexity reproducing content verbatim from test websites, demonstrating direct reproduction rather than transformative summarization.
Did Perplexity violate copyright law? #
The copyright question remains legally unsettled, but Perplexity's position is precarious. Perplexity claims fair use protection for summarization under the four-factor test. However, UCLA law professor Mark McKenna notes that reproducing substantial expression—not just facts—crosses into potential infringement territory. The Poynter Institute's "seven consecutive words" plagiarism standard suggests some Perplexity outputs exceed fair use boundaries. Forbes documented "nearly identical wording" to their original reporting, while WIRED observed verbatim reproduction from test content. These specific instances of direct reproduction are much harder to defend than pure summarization.
What is robots.txt and why does it matter? #
robots.txt is the Robots Exclusion Protocol—a voluntary standard websites use to communicate crawling preferences to automated systems. First developed in 1994, it's a simple text file placed at a website's root that tells well-behaved bots which areas to avoid. While not legally binding, systematic violations can constitute terms of service breaches or computer fraud under statutes like the Computer Fraud and Abuse Act. Perplexity's admission that PerplexityBot ignores robots.txt when processing user URL requests undermines a 30-year cooperative infrastructure standard that has governed web scraping behavior since the early search engine era.
Is AWS actually going to shut down Perplexity? #
AWS launched an investigation but hasn't announced enforcement action as of mid-July 2024. An AWS spokesperson confirmed to WIRED that they "routinely investigate abuse reports" and require customer compliance with terms prohibiting abusive activities. The threat alone creates significant business risk for Perplexity, which depends on AWS infrastructure for real-time AI search operations. Losing AWS hosting would be operationally catastrophic for a service requiring substantial compute resources, low-latency networking, and geographic distribution. The investigation signals that cloud providers may become enforcement points for scraping compliance—a development that would fundamentally constrain extraction-based business models.
How does Perplexity differ from Google in content usage? #
Google indexes content for later retrieval; Perplexity extracts and synthesizes content into direct answers in real-time. This architectural difference has profound implications: traditional search provides links that typically drive traffic to publishers, while Perplexity's AI answers may completely satisfy user information needs without referral traffic. Google's batch crawling model gives publishers visibility into access patterns; Perplexity's on-demand extraction means every query can trigger fresh scraping without publisher awareness. Additionally, Google has maintained robots.txt compliance as a core operational principle, while Perplexity explicitly acknowledges ignoring robots.txt for user-requested URLs—a distinction publishers view as legally and ethically meaningless.
What did Perplexity CEO Aravind Srinivas admit? #
Srinivas confirmed Perplexity uses third-party web crawlers alongside its own PerplexityBot, complicating the company's defense. This admission suggests not all scraping activity may be properly disclosed or directly controlled by Perplexity. He also acknowledged the product has "rough edges" while defending the company's fundamental right to summarize web content. Additionally, Perplexity head of business Dmitry Shevelenko admitted to TechCrunch that PerplexityBot specifically ignores robots.txt when users include URLs in their queries—framing this as user-directed access rather than autonomous crawling. These admissions transform potential deniability into documented policy.
Are other AI search engines doing the same thing? #
Industry practices vary dramatically, with Perplexity increasingly isolated in its aggressive approach. OpenAI has pursued content licensing deals with Axel Springer, The Atlantic, and other publishers—paying for access and building partnership relationships. Google continues respecting robots.txt while developing Search Generative Experience and engaging in licensing discussions. Anthropic's Claude claims robots.txt compliance with source highlighting in its interface. Perplexity's extraction-without-negotiation approach contrasts sharply with competitors who have chosen partnership models. This divergence suggests the industry is bifurcating: companies that build sustainable publisher relationships versus those that extract value and litigate disputes.
What should content creators do to protect their work? #
Implement layered technical protection beyond robots.txt, which Perplexity's case proves is insufficient alone. Technical measures include rate limiting at server/CDN levels, bot detection systems identifying headless browsers, server log monitoring for suspicious IP patterns (particularly AWS ranges like 44.221.181.252), and JavaScript challenges for high-value content. Legal measures include auditing terms of service to explicitly prohibit AI scraping, documenting violations with timestamps, and registering copyrights for high-value content. Strategic measures include evaluating paywalls or authentication for premium content and building direct audience relationships through channels AI can't intercept. Most critically: focus on creating genuinely original content—AI systems fundamentally require source material, making original reporting increasingly valuable and strategically defensible.
The Bottom Line: What Builders Should Take From This #
The Perplexity controversy reveals a fundamental tension in AI infrastructure that every builder must navigate. As someone deploying AI automation systems daily, I face the same ethical and technical decisions about data sourcing that Perplexity got wrong.
Perplexity's case demonstrates that technical capability doesn't justify technical overreach. The robots.txt protocol, while voluntary, represents a social contract that underpins the open web. Systematic violations—regardless of semantic distinctions about "crawling" versus "summarizing"—destroy the trust ecosystem that makes AI development possible. When well-funded startups treat cooperative infrastructure standards as optional, they poison the well for everyone else.
The technical defense Perplexity offers—that user-directed access isn't "crawling"—is sophistry that won't survive contact with either legal systems or business reality. Publishers don't care about taxonomy; they care about sustainable economics. AWS doesn't care about distinctions; it cares about terms of service compliance. Users may not care today, but they'll care when the investigative journalism AI search depends on disappears for lack of funding.
For SEO professionals and content creators watching this unfold, this is a wake-up call. The content-protection mechanisms we've relied on for decades—robots.txt, canonical tags, crawl rate management—are inadequate against AI-scale extraction. New technical and legal frameworks are inevitable. The practitioners who adapt early, implementing layered protection and direct audience relationships, will maintain competitive advantage.
For AI companies and builders, the strategic divide is clear: partnership or extraction. OpenAI's licensing deals with Axel Springer and The Atlantic suggest one path—pay for value, build relationships, create sustainable supply chains. Perplexity's escalating conflicts with publishers, AWS investigations, and reputational damage suggest another—extract first, litigate later, accept friction as cost of growth. The market will ultimately decide which approach sustains, but the regulatory and legal pressure on extraction models is only intensifying.
The deeper lesson for engineers and technical founders: your architecture decisions have legal and ethical implications that compound over time. Perplexity's real-time extraction model, while technically elegant, creates constant friction with content sources. Google's index-and-link model, while less responsive, built the publisher relationships that sustained search for decades. Technical choices are strategic choices. Choose architectures that align with the ecosystem you depend on.
As AI builders, we have an obligation to build systems that don't just extract value but create sustainable value for all participants. The AI automation I build for clients—from n8n workflows that orchestrate data pipelines to custom agents that process information—follows this principle: respect sources, attribute properly, and build relationships that outlast any single workflow. Short-term extraction always costs more than long-term partnership.
The Perplexity story isn't over. The AWS investigation continues. Publisher legal action likely looms. Regulatory responses are percolating. But the lessons are already clear: AI infrastructure built on extraction without compensation is infrastructure built on sand. The builders who recognize this early—who treat content creators as partners rather than resources—will define the next decade of AI development.
Need AI automation that respects both technical capabilities and ethical boundaries? I build production AI systems—from n8n workflows to custom agents—that drive growth without cutting corners.
Book an AI automation strategy call →
Related Articles #
Related Posts

Google I/O 2026 Action List: How I Prompted Gemini 3.5 Flash and Antigravity Workflows
Google I/O 2026 just reset the AI tooling landscape. Here's the 9-action checklist for builders who want to ship this week, not just watch the keynote.

Anthropic vs. OpenAI vs. Google: The State of the Frontier in May 2026
A head-to-head breakdown of the three AI giants in May 2026: Claude Opus 4.6, GPT-5.3 and 5.4, Gemini 3.1 Pro. Real specs, real pricing, and what actually matters for builders.

Kimi K2 Open Weights: How I Prompted Moonshot's Frontier Model for Agentic Tool Use
How I direct Kimi K2 by Moonshot AI for agentic workflows, long-context tool calling, and workflow automation. A 1 trillion parameter MoE model with competitive benchmarks at 5-17x lower cost than GPT-5 and Claude.




