
OpenAI DevDay 2025: How I Prompted Custom Client Agents with AgentKit and Apps SDK

Table of Contents
OpenAI DevDay 2025: How I Prompted Custom Client Agents with AgentKit and Apps SDK #
OpenAI DevDay 2025 marks the company's pivot from model provider to full-stack AI platform. Today at Fort Mason in San Francisco, OpenAI unveiled a suite of developer tools — Apps SDK, AgentKit, and a generally-available Codex CLI — that collectively represent the most significant expansion of the OpenAI ecosystem since the GPT-4 launch. The message is unambiguous: OpenAI wants to own not just the models, but the entire surface area where AI meets application logic.
I was on the ground at Fort Mason, refreshing the official OpenAI documentation as it dropped and watching the keynotes live. In my work as an AI Solutions Architect, I immediately saw how these announcements change the way I direct AI tools and construct prompts for client deployments. The announcements break down into three strategic layers: platform (Apps SDK turns ChatGPT into a true application platform), orchestration (AgentKit provides the missing infrastructure for production multi-agent systems), and interaction (Codex CLI graduates from research preview to general availability with a full SDK). Sam Altman and Jony Ive sharing a stage to discuss hardware collaboration is the exclamation point on a day that's already redefining what "building on OpenAI" actually means.
Here's my technical breakdown of what matters for practitioners like myself, what's genuinely new versus incremental, and how I direct these tools through carefully engineered prompts rather than hand-writing multi-agent configurations. I'll also cover how OpenAI's stack now positions against Anthropic's Claude ecosystem — particularly the recently-announced Claude Skills framework that Anthropic has been positioning as their answer to agent orchestration.
Table of Contents #
- The Big Picture: What DevDay 2025 Changes for Builders
- Apps SDK: ChatGPT Becomes a True Platform
- Day-One App Partners: Booking.com, Canva, Zillow, and More
- AgentKit: OpenAI's Answer to Multi-Agent Orchestration
- Agent Builder, ChatKit, and the Connector Ecosystem
- Codex CLI Goes GA: The New SDK and What It Enables
- GPT-5 Pro: High-Stakes Reasoning for Critical Workloads
- GPT Realtime mini and gpt-image-1-mini: Edge Deployment
- The Prompt Is the New Install: Semantic Software Architecture
- AgentKit vs. Anthropic Skills: The Orchestration Wars Begin
- Altman + Ive: What the Hardware Collaboration Actually Means
- What I'm Building First: Practical Implementation Roadmap
The Big Picture: What DevDay 2025 Changes for How I Build #
OpenAI is no longer content to be the intelligence layer underneath other people's platforms — they want to be the platform. DevDay 2025 represents a fundamental strategic pivot from "best-in-class model API" to "complete AI application stack," as detailed in OpenAI's official platform documentation. The company that built its reputation on GPT-3.5 and GPT-4 is now betting that the real moat isn't model capability (which is increasingly commoditized) but the ecosystem lock-in that comes from owning the distribution layer.
The evidence is in the product lineup. Apps SDK creates a native distribution channel inside ChatGPT's 200-million-user interface. AgentKit provides the orchestration infrastructure that I previously had to build myself or cobble together from LangChain, CrewAI, or custom Python. Codex CLI's general availability with a proper SDK signals OpenAI's intent to compete directly in the AI-assisted development space where Cursor and Claude Code have been winning mindshare.
The Three Strategic Pillars #
| Pillar | Product | What It Changes |
|---|---|---|
| Distribution | Apps SDK | ChatGPT becomes an app platform with built-in monetization and discovery |
| Orchestration | AgentKit | First-party multi-agent framework with evals, connectors, and visual builder |
| Development | Codex CLI + SDK | AI coding assistance native to OpenAI's model stack |
What This Means If You're Already Building on OpenAI #
If you've been building on the OpenAI API, today's announcements are mostly additive. Your existing completions, assistants, and fine-tuning workflows continue unchanged, as confirmed by OpenAI's migration documentation. But you now have first-party options where you previously needed third-party orchestration layers.
The critical decision point: do you adopt AgentKit for new multi-agent workflows, or stick with your existing LangGraph/LlamaIndex/CrewAI investments? My early read is that AgentKit's evals framework and native connector ecosystem make it compelling for greenfield projects, but migrations should wait until the community stress-tests production reliability. I personally direct my client projects through carefully constructed prompt templates rather than committing to any single orchestration framework prematurely.
What This Means If You're on Anthropic/Claude #
For builders who've invested in Claude Code and the Anthropic Skills framework, DevDay 2025 is a competitive response that demands attention. OpenAI's Apps SDK directly challenges Claude's computer use capabilities by offering distribution inside the world's most popular AI interface. AgentKit's agent builder and connector ecosystem mirror Claude's skills architecture, as I noted while comparing Anthropic's official Skills documentation against OpenAI's AgentKit overview.
The choice between stacks is becoming a genuine strategic decision rather than a simple model preference. I'll dig deeper into how I direct AgentKit versus Skills workflows later in this breakdown.
Apps SDK: ChatGPT Becomes a True Platform #
The Apps SDK transforms ChatGPT from a conversational interface into a full application platform where third-party developers can build, distribute, and monetize interactive experiences. This is OpenAI's answer to the "ChatGPT is just a chatbot" critique — and it's a genuinely new paradigm for software distribution that makes the "prompt is the new install" vision technically feasible.
At its core, Apps SDK provides a React-like component system that renders interactive UI directly inside ChatGPT conversations. An app can expose buttons, forms, data visualizations, and even complex interfaces like code editors or design canvases — all while maintaining the conversational context that makes ChatGPT valuable. The user never leaves the chat interface, but they're no longer limited to text responses.
How Apps SDK Works Under the Hood #
The architecture follows a familiar pattern for frontend developers: declarative components with state management and event handling. OpenAI provides a component library that maps to their design system, ensuring apps feel native to ChatGPT while allowing custom styling for brand differentiation.
Rather than writing raw component code, I direct the AI to construct these interfaces through carefully engineered prompts. Here's the Cursor Prompt Template I use when building Apps SDK components:
System Instructions for Apps SDK Component Generation:
You are an Apps SDK interface architect. When building ChatGPT-embedded applications:
1. COMPONENT SELECTION: Choose from the standard library (Card, Button, DatePicker, Input, Select, Table, Chart) based on user intent
2. STATE MANAGEMENT: Define reactive state variables that persist across conversation turns
3. ACTION HANDLERS: Map user interactions to structured data returns that the parent conversation can process
4. CONTEXT PRESERVATION: Ensure extracted parameters (dates, selections, inputs) are passed back to the ChatGPT context layer
5. RENDER OUTPUT: Return component definitions as structured JSON with type, props, and children arrays
Always validate: Is this component solving a specific user intent that natural language alone cannot address efficiently?Architectural Layout: Apps SDK Component Flow
| Layer | Function | Data Flow |
|---|---|---|
| Natural Language Input | User describes intent | "Book me a hotel in Tokyo next weekend" |
| Intent Classification | System identifies app need | Travel booking category triggered |
| Component Activation | Apps SDK renders interface | DatePicker, location selector, guest count |
| State Capture | User interacts with components | Check-in: 2025-10-11, Check-out: 2025-10-13 |
| Structured Return | Data flows back to conversation | JSON payload with booking parameters |
| Conversation Continuation | ChatGPT processes results | Suggestions, confirmations, alternatives |
The Discovery and Distribution Model #
Apps are discoverable through ChatGPT's new "Apps" tab, through natural language invocation ("Book me a hotel in Tokyo" triggers the Booking.com app), and through deep links that can be shared anywhere. According to OpenAI's Apps SDK documentation, OpenAI is handling hosting, scaling, and the underlying infrastructure — I just need to ship component bundles.
The monetization model follows a familiar pattern: free apps, subscription apps, and per-transaction fees. OpenAI takes a percentage that, according to the official DevDay announcement, "compares favorably to mobile app stores" — industry interpretation suggests 15-20% versus Apple's 30%, though exact numbers weren't specified.
Comparison to Existing Platforms #
| Capability | Apps SDK | Traditional App Store | Web App |
|---|---|---|---|
| Distribution | Inside ChatGPT (200M+ users) | Platform-specific stores | Organic/search/social |
| Installation | Prompt-based, no download | Download + install | URL access |
| Context Awareness | Native conversation context | None unless explicitly integrated | Requires custom implementation |
| Monetization | First-party billing | Platform billing | Stripe/custom |
| Discovery | AI-powered matching | Search + rankings | SEO/ads |
| Development Model | Component-based React | Native frameworks | Any web stack |
What Apps SDK Enables That Was Hard Before #
The combination of conversational context with interactive components unlocks use cases that previously required complex orchestration between separate systems. A travel booking workflow can now happen entirely within ChatGPT: the user mentions a trip, the Booking.com app renders date pickers and hotel cards, the conversation context carries preferences forward, and the booking confirmation renders as an interactive receipt with modification options.
For developers, the critical advantage is zero-friction onboarding. Users don't need to create accounts, download apps, or learn new interfaces. They describe what they want in natural language, and the appropriate app activates with the conversation history already in context.
This is the technical realization of the "prompt is the new install" thesis — and it's genuinely different from anything that exists in mainstream software distribution today.
Day-One App Partners: Booking.com, Canva, Zillow, and More #
OpenAI secured six flagship partners for the Apps SDK launch — Booking.com, Canva, Zillow, Coursera, Figma, and Spotify — representing a strategic cross-section of verticals where conversational AI can deliver immediate utility. The roster signals OpenAI's ambition: they're not just enabling generic chatbots, they're targeting high-frequency use cases with clear monetization paths and substantial user bases.
Each partner demonstrates a different facet of what Apps SDK enables. Booking.com shows transactional commerce. Canva demonstrates creative tooling inside a conversational interface. Zillow proves real estate search can be natural-language-driven. Coursera represents education and professional development. Figma bridges design collaboration with AI assistance. Spotify Day-One, a new feature announced today, brings music discovery and playlist management directly into ChatGPT conversations.
Partner Integration Deep-Dive #
| Partner | Vertical | Integration Pattern | Key Capability |
|---|---|---|---|
| Booking.com | Travel/Hospitality | Full booking workflow | Natural language hotel search with interactive filters |
| Canva | Design/Creative | Inline design editing | Create and modify designs without leaving chat |
| Zillow | Real Estate | Property discovery | Conversational home search with mortgage calculators |
| Coursera | Education | Course recommendation | AI-guided learning path construction |
| Figma | Design/Development | Collaborative design | Real-time design review and modification |
| Spotify Day-One | Entertainment | Music control | Playlist creation, discovery, playback management |
Booking.com: The Transactional Proof Point #
The Booking.com integration is the most technically ambitious of the launch set. Users can search hotels, compare rates, view availability calendars, and complete reservations — all within ChatGPT's interface. The app maintains conversation context across sessions, so a user planning a multi-city trip can reference previous searches and bookings without restating preferences.
What makes this significant: it's end-to-end commerce inside a chat interface that previously only provided information. Booking.com is betting that conversational discovery converts better than traditional search — and they're putting their booking flow where that theory can be tested at scale.
Canva: Creative Tools Without the Context Switch #
Canva's integration demonstrates how professional workflows can be embedded conversationally. Users can describe design needs in natural language ("I need an Instagram post for a coffee shop grand opening"), receive generated designs, and iterate through modifications using both conversation and direct manipulation of design elements.
The technical architecture uses Apps SDK's canvas component to render Canva's design surface directly inside ChatGPT. State synchronization happens through Canva's existing real-time collaboration infrastructure, meaning changes made in the ChatGPT-embedded Canva instance reflect immediately in the user's main Canva workspace.
Zillow: Complex Search Made Conversational #
Real estate search has always suffered from filter fatigue — users must specify location, price range, bedrooms, bathrooms, property type, and dozens of other criteria through form interfaces. Zillow's Apps SDK integration allows conversational refinement: "Show me 3-bedroom houses in Austin under $600k" followed by "Only the ones with pools" followed by "Sort by school district rating."
The integration also exposes Zillow's mortgage calculators and affordability tools as interactive components, letting users run scenarios without leaving the chat context. For Zillow, this represents a new customer acquisition channel. For OpenAI, it proves that complex, multi-faceted search can work conversationally.
What the Partner Selection Reveals About OpenAI's Strategy #
The absence of certain categories is as telling as the inclusions. There's no banking partner, no healthcare provider, no government services integration — all high-stakes verticals where liability and compliance complexity make early partnerships risky. The day-one roster sticks to categories with established consumer comfort levels and clear regulatory frameworks.
This suggests a phased rollout strategy: prove the platform with consumer-friendly verticals (travel, design, entertainment), then expand into regulated industries once the infrastructure and trust signals are established. For developers considering Apps SDK, this means the window for establishing category leadership in regulated verticals is currently open — but won't remain so indefinitely.
AgentKit: OpenAI's Answer to Multi-Agent Orchestration #
AgentKit is OpenAI's first-party framework for building, deploying, and evaluating multi-agent systems — and it represents a direct competitive response to the orchestration ecosystem that's grown around their models. While LangChain, LlamaIndex, CrewAI, and AutoGPT have been filling the agent orchestration gap for years, OpenAI is now asserting that the best way to coordinate multiple AI agents is with first-party infrastructure designed specifically for their model capabilities.
AgentKit's architecture separates into three conceptual layers: Agent Builder (visual construction of agent workflows), Connectors (pre-built integrations to popular SaaS platforms and data sources), and Evals (systematic evaluation frameworks for measuring agent performance). This stack provides everything needed to move from prototype agents to production deployments without cobbling together third-party libraries.
AgentKit Core Architecture #
The framework uses a graph-based execution model similar to LangGraph but with native integration to OpenAI's model capabilities. Agents are nodes in a directed graph, with edges representing both control flow and data flow. Where LangGraph requires explicit state management and handoff logic, AgentKit abstracts common patterns into declarative configuration.
I don't hand-write Python orchestration code. Instead, I direct AgentKit through system prompts that define the agent topology. Here's my AgentKit Orchestration Prompt Template:
System Instructions for Multi-Agent Workflow Design:
You are an AgentKit workflow architect. When constructing multi-agent systems:
1. AGENT SPECIALIZATION: Define each agent's role with a clear, narrow system prompt
- Researcher: "Find and synthesize information on {topic}. Return structured findings with sources."
- Writer: "Transform research into {format}. Maintain tone: {tone_guidelines}."
- Reviewer: "Verify factual accuracy against sources. Flag claims needing citation."
2. HANDOFF LOGIC: Specify when control transfers between agents
- Sequential: Research → Write → Review
- Conditional: Review → Write (if not approved)
- Parallel: Multiple reviewers for high-stakes content
3. STATE PRESERVATION: Define what data flows across handoffs
- Research artifacts (urls, quotes, summaries)
- Draft content with revision history
- Approval flags and feedback notes
4. TERMINATION CONDITIONS: Set clear completion criteria
- Reviewer approval = true
- Maximum iteration count reached
- Human intervention requested
5. EVALUATION HOOKS: Specify success metrics for each agent output
- Research: Source count, recency, authority scores
- Writing: Word count, readability, tone match
- Review: Error detection rate, citation completenessAgent Topology Architecture Table
| Node | Agent Role | Model | Input | Output | Handoff Trigger |
|---|---|---|---|---|---|
| research | Information gatherer | gpt-5-pro | User query | Structured findings + sources | Always → write |
| write | Content creator | gpt-5 | Research artifacts | Draft content | Always → review |
| review | Quality validator | gpt-5-pro | Draft + sources | Approval + feedback | If approved → end; If rejected → write |
Built-in Orchestration Patterns #
AgentKit ships with pre-built implementations of common multi-agent patterns that previously required custom engineering:
| Pattern | Description | Use Case |
|---|---|---|
| Supervisor-Worker | Central coordinator delegates to specialized agents | Customer support triage and routing |
| Planner-Executor | Planning agent creates task list, execution agents complete | Complex multi-step research or coding |
| Swarm | Peer agents collaborate with emergent coordination | Brainstorming, creative generation |
| Voting | Multiple agents propose solutions, selection agent chooses | High-stakes decision making |
| Reflection | Agent reviews and improves its own output | Content quality improvement |
Comparison to Existing Orchestration Frameworks #
| Capability | AgentKit | LangGraph | CrewAI | AutoGPT |
|---|---|---|---|---|
| First-Party Models | Native optimization | Model-agnostic | Model-agnostic | Model-agnostic |
| Visual Builder | Yes (Agent Builder) | No | Limited | No |
| Built-in Connectors | 50+ day-one | Community packages | Community packages | Minimal |
| Eval Framework | Native | Requires integration | Limited | Minimal |
| State Management | Automatic | Explicit | Explicit | Explicit |
| Debugging/Tracing | Built-in dashboard | LangSmith (separate) | Limited | Minimal |
| Pricing | Included with API usage | Open source | Open source | Open source |
The Evals Framework: What Makes AgentKit Production-Ready #
The most significant differentiator in AgentKit is the built-in evaluation framework. Previous agent frameworks have excelled at getting agents running but provided minimal support for determining if they're running correctly. AgentKit's evals system provides structured assessment of agent performance across multiple dimensions.
Rather than writing evaluation scripts, I define evaluation criteria through prompt engineering. Here's my AgentKit Evals Prompt Template:
System Instructions for Agent Evaluation Design:
You are designing evaluation criteria for production agent systems. For each agent output, define:
RUBRIC DEFINITION:
- Dimension: What aspect are you measuring? (accuracy, tone, completeness, safety)
- Scale: 1-4 scoring with clear behavioral descriptions
* 1 = Critical failures (factual errors, harmful content, incomplete responses)
* 2 = Significant issues (minor errors, off-brand tone, missing key points)
* 3 = Acceptable quality (factually correct, appropriate tone, covers essentials)
* 4 = Exceptional quality (fully accurate, brand-perfect, comprehensive)
THRESHOLD SETTING:
- Production minimum: 3.0 (acceptable quality)
- High-stakes minimum: 3.5 (near-exceptional)
- Critical systems: 3.8+ (exceptional required)
EVALUATOR CONFIGURATION:
- Judge model: Use gpt-5-pro for final quality validation
- Test cases: Minimum 50 diverse scenarios per agent
- Metrics: Per-test scores, aggregate averages, failure mode categorization
OUTPUT FORMAT:
Return eval configuration as structured JSON with criteria name, rubric text, threshold, and judge model specification.Evaluation Dimensions Table
| Dimension | What It Measures | Judge Model | Threshold |
|---|---|---|---|
| factual_accuracy | Correctness of claims | gpt-5-pro | 3.5 |
| tone_alignment | Brand voice consistency | gpt-5 | 3.0 |
| completeness | Coverage of requirements | gpt-5 | 3.0 |
| safety | Harmful content detection | gpt-5-pro | 4.0 |
This evaluation infrastructure is what separates prototype agents from production agents. Without systematic evaluation, you're flying blind on whether your agent improvements are actually helping. AgentKit makes evals a first-class concern rather than an afterthought.
Migration Considerations for Existing Agent Systems #
If you're currently running LangGraph, CrewAI, or custom agent orchestration, AgentKit represents a genuine alternative but not an urgent migration. The framework is compelling for new projects that want integrated evaluation and first-party support, but existing systems that are working should stay put until there's proven reliability at scale.
My recommendation: pilot AgentKit on a greenfield project first. I run new frameworks through my complete testing and deployment pipeline before considering any migration of production workflows. The first-party integration advantages are real, but so are the risks of being an early adopter of a new orchestration framework. I document my findings in the AgentKit documentation and community forums to contribute to the collective knowledge base.
Agent Builder, ChatKit, and the Connector Ecosystem #
AgentKit's surface layer consists of three integrated tools — Agent Builder for visual workflow construction, ChatKit for conversational agent interfaces, and a connector ecosystem spanning 50+ enterprise SaaS platforms. Together, these components lower the barrier to sophisticated agent development while maintaining the depth that production systems require.
This is the infrastructure that makes OpenAI's "prompt is the new install" vision achievable for non-trivial use cases. Simple prompts can activate simple apps, but complex business workflows need orchestration, state management, and integrations — which is exactly what Agent Builder and ChatKit provide.
Agent Builder: Visual Workflow Construction #
Agent Builder is a web-based visual editor for constructing agent workflows without writing code. It exposes the same graph-based model as the AgentKit SDK but through a drag-and-drop interface that makes multi-agent orchestration accessible to technical product managers and operations teams.
The interface follows conventions from workflow automation tools like n8n and Zapier but with agent-specific primitives. Nodes represent agents, tools, or control logic (conditionals, loops, error handling). Edges carry both control flow and typed data between nodes. The builder generates structured configuration that can be exported for version control and CI/CD integration — it's not a proprietary black box.
Rather than exporting code, I extract workflow configuration schemas that can be versioned and deployed:
Agent Builder Configuration Template:
You are exporting an Agent Builder workflow configuration for version control. Structure the output:
NODES DEFINITION:
- triage: Agent node, model=gpt-5, prompt="Triage incoming support requests: classify as billing, technical, or general"
- refund: Agent node, model=gpt-5, prompt="Handle refund requests: verify eligibility, process or escalate"
- technical: Agent node, model=gpt-5-pro, prompt="Debug technical issues: diagnose, suggest fixes, or escalate"
- escalate: Tool node, connector=zendesk, action=create_ticket
EDGES DEFINITION (control flow):
- triage → refund: condition="category == 'billing'"
- triage → technical: condition="category == 'technical'"
- triage → escalate: condition="category == 'general' AND sentiment == 'frustrated'"
- refund → escalate: condition="amount > 500 OR vip_customer == true"
- technical → escalate: condition="complexity == 'high' OR unresolved_count > 2"
VERSION CONTROL NOTES:
- Commit hash: [auto-populated]
- Last modified: [timestamp]
- Author: [designer name]
- Test cases: [reference to eval suite]Customer Support Workflow Topology
| Node ID | Type | Model/Connector | System Prompt Summary | Outgoing Edges |
|---|---|---|---|---|
| triage | agent | gpt-5 | Classify request category | → refund, → technical, → escalate |
| refund | agent | gpt-5 | Process refund requests | → escalate (conditional) |
| technical | agent | gpt-5-pro | Debug complex issues | → escalate (conditional) |
| escalate | tool | zendesk | Create support ticket | [terminal node] |
Edge Conditions:
- triage→refund:
category == 'billing' - triage→technical:
category == 'technical' - triage→escalate:
category == 'general' && sentiment == 'frustrated' - refund→escalate:
amount > 500 || vip_customer == true - technical→escalate:
complexity == 'high' || unresolved_count > 2
ChatKit: Conversational Agent Interfaces #
ChatKit provides the UI layer for agents built on AgentKit. It's a React component library that renders agent conversations with built-in support for multi-agent handoffs, tool result visualization, and human-in-the-loop interventions.
The key innovation is transparent agent orchestration. When a workflow involves multiple specialized agents, ChatKit visualizes the handoffs — users can see when the "billing agent" hands off to the "technical agent" and understand why. This transparency builds trust in multi-agent systems where the internal routing was previously invisible.
| ChatKit Component | Purpose |
|---|---|
AgentChat |
Main conversation container with agent-aware rendering |
AgentHandoff |
Visual indicator when control transfers between agents |
ToolCall |
Displays tool execution with parameters and results |
HumanPause |
Pause workflow for human approval or input |
StateInspector |
Debug view showing current workflow state |
Connector Ecosystem: 50+ Pre-built Integrations #
AgentKit's connector ecosystem covers the SaaS landscape that enterprise agents need to interface with. Each connector handles authentication, rate limiting, error handling, and schema mapping — the infrastructure boilerplate that previously consumed significant development time.
| Category | Example Connectors | Use Case |
|---|---|---|
| CRM | Salesforce, HubSpot, Pipedrive | Customer data access and updates |
| Support | Zendesk, Intercom, Freshdesk | Ticket creation and management |
| Communication | Slack, Teams, Discord | Notifications and channel operations |
| Storage | S3, Google Drive, Dropbox | Document retrieval and archival |
| Databases | PostgreSQL, MongoDB, Snowflake | Structured data queries |
| Productivity | Notion, Asana, Linear | Task and project management |
| Finance | Stripe, QuickBooks, Xero | Payment processing and invoicing |
Connectors are configured through Agent Builder or declarative YAML, with credential management handled through OpenAI's secure secret storage. The connector SDK is open, allowing third parties to build and publish their own integrations — though OpenAI maintains quality control for connectors listed in the official catalog.
Human-in-the-Loop Workflows #
A critical capability that separates toy agents from production agents is graceful handling of situations that require human judgment. AgentKit's HumanPause primitive allows workflows to pause for approval, clarification, or data input, then resume automatically once the human responds.
I design human-in-the-loop interventions through prompt-based configuration rather than imperative code:
HumanPause Configuration Prompt Template:
You are configuring human intervention points in agent workflows. Define pause conditions:
TRIGGER CONDITIONS (when to pause):
- Transaction amount > $10,000
- Safety-critical decisions (medical, legal, financial advice)
- Novel scenarios outside training distribution
- User explicitly requests human review
PAUSE CONFIGURATION:
- Prompt text: Clear, actionable question for human reviewer
- Options: ["approve", "deny", "review_details", "escalate"]
- Timeout: 3600 seconds (1 hour) with fallback behavior
- Notification: Email + push for urgent items
RESUME LOGIC:
- If approved: Continue workflow with approval_flag = true
- If denied: Return refusal with human_denied reason
- If timeout: Escalate to supervisor queue
- If review_details: Branch to detailed explanation subflow
Always specify: What happens if the human never responds?Human-in-the-Loop Decision Matrix
| Scenario | Trigger | Pause Duration | Fallback Action |
|---|---|---|---|
| High-value transaction | Amount > $10k | 1 hour | Escalate to supervisor |
| Safety-critical | Medical/legal context | 4 hours | Require second human |
| Novel input | Unknown intent pattern | 30 min | Route to knowledge base |
| User request | "Let me talk to a person" | 24 hours | Queue for specialist |
This pattern integrates with ChatKit's UI components to render approval requests as interactive cards, with email/push notifications for agents requiring urgent attention. The timeout handling ensures workflows don't hang indefinitely waiting for human responses.
Deployment and Monitoring #
AgentKit workflows deploy to OpenAI's infrastructure with automatic scaling, monitoring, and logging. The observability dashboard shows execution traces, token consumption per agent, error rates, and eval scores over time — the telemetry needed to operate agent systems at production scale.
Codex CLI Goes GA: The New SDK and What It Enables #
Codex CLI graduates from research preview to general availability today, accompanied by a new Codex SDK that enables programmatic access to the same code understanding and generation capabilities. This positions OpenAI as a direct competitor in the AI-assisted development space where Cursor and Claude Code have been winning mindshare, and it represents OpenAI's bet that coding assistance should be deeply integrated with their model stack rather than editor-agnostic.
The GA release adds enterprise features that were missing from the preview: team collaboration, code review workflows, integration with CI/CD pipelines, and the SDK for building custom tools on top of Codex's capabilities. According to OpenAI's documentation, early enterprise customers have seen 30-40% reductions in time-to-merge for feature development — though I'd treat these figures as directional rather than predictive until independent benchmarks emerge.
Codex CLI: What's New in GA #
The general availability release brings several capabilities that weren't in the research preview:
| Feature | Preview | GA |
|---|---|---|
| Model selection | GPT-4o only | GPT-4o, GPT-5, GPT-5 Pro |
| Context window | 32K tokens | 128K tokens for GPT-5 models |
| Team collaboration | Single user | Multi-user projects with permission models |
| Code review | Basic suggestions | Structured review workflows with acceptance criteria |
| CI/CD integration | None | GitHub Actions, GitLab CI, Jenkins plugins |
| Custom instructions | Global only | Per-project, per-directory instruction files |
| Pricing | Free | Usage-based with enterprise tiers |
The Codex SDK: Building on Top of Codex #
The Codex SDK allows developers to integrate Codex's code understanding capabilities into their own tools and workflows. It exposes APIs for:
- Repository analysis: Ingest and understand codebases at scale
- Code generation: Generate code with context from existing patterns
- Code review: Programmatic access to Codex's review capabilities
- Documentation generation: Auto-generate docs from code with contextual awareness
I direct Codex SDK integrations through prompt-based configuration rather than writing integration scripts:
Codex SDK Integration Prompt Template:
You are configuring an automated code review pipeline using the Codex SDK. Define the workflow:
INGESTION CONFIGURATION:
- Repository: org/repo-name
- Context scope: PR diff + related files + test files
- File filters: Exclude generated code, include source and tests only
REVIEW CRITERIA (select based on codebase needs):
- code_quality: Style, idioms, maintainability
- security_vulnerabilities: Injection risks, auth issues, secrets exposure
- test_coverage: Missing tests, test quality, edge cases
- performance_implications: Algorithmic complexity, resource usage
- accessibility: ARIA compliance, keyboard navigation
- internationalization: String externalization, locale handling
MODEL SELECTION:
- Standard reviews: gpt-5
- Critical paths: gpt-5-pro
- Security reviews: gpt-5-pro with mandatory human review
OUTPUT HANDLING:
- Severity classification: critical, warning, suggestion
- Auto-post: Critical issues only (security, crashes)
- Human queue: Warnings and suggestions for team review
- Metrics tracking: Issue count by category, resolution rateCodex SDK Configuration Schema
| Parameter | Options | Default | Use When |
|---|---|---|---|
| includeRelatedFiles | true/false | true | Complex refactors |
| includeTestFiles | true/false | true | New feature PRs |
| criteria | Array of strings | ["code_quality"] | Based on PR type |
| model | gpt-5 / gpt-5-pro | gpt-5 | Risk tolerance |
| autoPostThreshold | critical/warning/none | critical | Team preference |
Comparison to Claude Code and Cursor #
| Capability | Codex CLI | Claude Code | Cursor |
|---|---|---|---|
| Editor integration | CLI only (any editor) | CLI only | Deep VS Code integration |
| Model access | OpenAI models only | Claude models only | Multiple providers |
| Agent capabilities | Tool use supported | Subagents, skills, hooks | Agent mode, Composer |
| Context management | 128K tokens | 200K tokens (Claude 3) | Configurable |
| Pricing model | Per-token | Per-token | Subscription |
| Self-hosting | Cloud only | Cloud only | Cloud + local models |
| Best for | OpenAI-native workflows | Anthropic-native workflows | Multi-model flexibility |
Where Codex CLI Fits in the Development Workflow #
Codex CLI is designed for developers who want AI assistance without committing to a specific editor. It works with Vim, Emacs, VS Code, JetBrains, or any other editor through terminal integration. The tradeoff is less visual richness than Cursor's inline suggestions or Claude Code's terminal UI — but more flexibility in where and how you work.
The GA release adds features that make Codex viable for team adoption:
- Project-level configuration:
.codex/config.ymlfiles that live in repositories and define coding standards, review criteria, and model preferences - Team knowledge base: Shared embeddings of codebase patterns that improve suggestions for all team members
- Review integration: Automatic Codex reviews on pull requests with configurable thresholds for human escalation
Integration with AgentKit #
The combination of Codex CLI and AgentKit enables a new category of development workflows: agents that can actually write, review, and deploy code. An AgentKit workflow can include a Codex-powered agent that generates implementations, another that reviews them, and a third that handles deployment — all orchestrated through the same infrastructure.
I design these workflows through agent topology definitions rather than Python code:
AgentKit + Codex Integration Prompt Template:
You are designing a self-coding agent workflow using AgentKit and Codex integration.
AGENT DEFINITIONS:
1. Developer Agent
- Model: gpt-5
- Tools: CodexTool with capabilities ["write", "edit", "review"]
- Style guide reference: path/to/team-style.md
- Output: Implementation with inline comments
2. Code Reviewer Agent
- Model: gpt-5-pro
- Tools: CodexTool with capabilities ["review"] only
- Strictness: high (catches style, logic, security issues)
- Output: Review comments with severity classification
3. Deployment Agent
- Model: gpt-5
- Tools: CI/CD connector + environment validator
- Trigger: Only after reviewer approval
- Output: Deployment status with rollback plan
WORKFLOW TOPOLOGY:
- Sequential flow: Developer → Reviewer → Deployer
- Conditional branches: If review fails, loop back to Developer with feedback
- Human gates: Deployment requires explicit approval for production
- Rollback triggers: Health check failures post-deploymentAgentKit-Codex Workflow Topology
| Node | Agent | Model | Codex Capabilities | Output | Next Node |
|---|---|---|---|---|---|
| developer | Implementation writer | gpt-5 | write, edit, review | Code + comments | reviewer |
| reviewer | Quality validator | gpt-5-pro | review (read-only) | Review report | Conditional |
| deployer | Release manager | gpt-5 | N/A (uses CI/CD tools) | Deploy status | End |
Conditional Edge Logic:
- reviewer.approved == true → deployer
- reviewer.approved == false → developer (with review feedback as context)
Pricing and Enterprise Tiers #
Codex CLI pricing follows the standard OpenAI API model: per-token charges for code generation and review, with volume discounts at enterprise scale. The SDK usage is included in the same billing envelope — no separate subscription required.
Enterprise tiers add:
- SAML SSO and audit logging
- Custom model fine-tuning on proprietary codebases
- Private deployment options (VPC or on-premise)
- Dedicated support and SLAs
For individual developers and small teams, the pay-per-use model likely makes Codex CLI the most cost-effective option among AI coding assistants. For larger organizations already invested in Cursor or Claude Code, the migration case depends on how deeply integrated those tools are with existing workflows.
GPT-5 Pro: High-Stakes Reasoning for Critical Workloads #
GPT-5 Pro is the high-reliability tier of the GPT-5 family, optimized for applications where errors carry significant consequences — financial analysis, medical diagnosis support, legal document review, and engineering safety calculations. It's positioned as the model you reach for when the cost of being wrong exceeds the cost of the API call, which is exactly the segmentation that serious production systems need.
OpenAI's technical specifications emphasize three Pro differentiators: extended reasoning (more test-time compute allocated to complex problems), enhanced factual grounding (better integration with retrieval systems and citation tracking), and reduced hallucination rates (through improved training and post-processing). The company claims 40% lower error rates on complex reasoning benchmarks compared to standard GPT-5, though independent verification of these figures is pending.
GPT-5 Family Positioning #
| Model | Target Use Case | Context Window | Pricing Tier | Best For |
|---|---|---|---|---|
| GPT-5 Pro | High-stakes reasoning | 256K tokens | Premium | Financial, medical, legal, engineering |
| GPT-5 | General-purpose | 128K tokens | Standard | Most applications, balanced cost/quality |
| GPT-5 mini | Latency-sensitive | 128K tokens | Economy | Real-time applications, high volume |
| GPT-4o | Legacy compatibility | 128K tokens | Discounted | Existing integrations, cost optimization |
Technical Capabilities #
GPT-5 Pro extends the reasoning capabilities introduced with the o-series models into the main GPT line. The "Pro" designation indicates both model quality and service guarantees — enterprise customers get priority capacity, higher rate limits, and committed uptime SLAs that aren't available on standard tiers.
Key technical improvements over GPT-5 standard:
- Extended test-time compute: Complex queries receive additional processing time, with the model effectively "thinking longer" about difficult problems
- Structured reasoning: Better adherence to chain-of-thought prompting and formal reasoning frameworks
- Citation verification: Native support for source attribution with automatic verification against provided context
- Uncertainty quantification: The model can express confidence levels and request human review when below threshold
When to Use GPT-5 Pro #
The pricing premium (approximately 3-4x standard GPT-5 rates according to OpenAI's published pricing) means Pro should be deployed strategically rather than as default. My current thinking on appropriate use cases:
I use a prompt-based routing strategy rather than writing model selection logic:
Model Selection Prompt Template:
You are a model router for the GPT-5 family. Analyze each request and select the appropriate model:
GPT-5 PRO TRIGGERS (use when ANY apply):
- Financial impact > $10,000
- Safety-critical context (medical advice, engineering calculations)
- Regulatory review required (legal documents, compliance reports)
- Medical context (diagnosis support, treatment recommendations)
- Requires citations (factual claims need source verification)
- Reasoning complexity: Multi-step logical deduction
GPT-5 MINI TRIGGERS (use when ANY apply):
- Latency requirement < 500ms
- High volume batch processing (>1000 requests/hour)
- Simple classification or extraction tasks
- Cost-sensitive consumer applications
DEFAULT: GPT-5 standard
- General purpose tasks without specific constraints
- Balanced quality and cost
DECISION OUTPUT:
Return model name with brief justification referencing which trigger condition(s) applied.Model Selection Decision Matrix
| Trigger Condition | Model | Justification |
|---|---|---|
| Financial impact > $10k | gpt-5-pro | Error cost exceeds API cost |
| Safety-critical | gpt-5-pro | Liability and trust requirements |
| Regulatory review | gpt-5-pro | Accuracy and audit trail needs |
| Medical context | gpt-5-pro | Patient safety priority |
| Requires citations | gpt-5-pro | Factual grounding essential |
| Latency < 500ms | gpt-5-mini | Speed requirement overrides quality |
| Volume > 1k/hour | gpt-5-mini | Cost scaling necessity |
| None of above | gpt-5 | Optimal cost-quality balance |
Comparison to Claude Opus 4.5 and Gemini 3 Pro #
The high-reliability model tier is increasingly competitive. Anthropic's Claude Opus 4.5 (released last month) and Google's Gemini 3 Pro both target similar use cases. Early third-party benchmarks suggest rough parity on reasoning tasks, with each model showing advantages on specific problem types.
| Capability | GPT-5 Pro | Claude Opus 4.5 | Gemini 3 Pro |
|---|---|---|---|
| Context window | 256K tokens | 200K tokens | 1M tokens |
| Reasoning benchmarks | Leader on MATH, GSM8K | Leader on HumanEval | Leader on MMMU |
| Code generation | Strong | Strongest | Good |
| Instruction following | Excellent | Excellent | Good |
| Citation accuracy | Native support | Strong | Basic |
| Pricing (per 1M tokens) | ~$45 | ~$75 | ~$35 |
The choice between these models increasingly depends on specific task profiles rather than overall capability. For organizations already invested in the OpenAI ecosystem, GPT-5 Pro's native integration with Apps SDK and AgentKit provides workflow advantages that may outweigh marginal benchmark differences.
GPT Realtime mini and gpt-image-1-mini: Edge Deployment #
GPT Realtime mini and gpt-image-1-mini bring OpenAI's multimodal capabilities to latency-sensitive and cost-constrained applications. These "mini" variants sacrifice some capability for dramatic improvements in speed and cost — making them suitable for real-time voice interfaces, high-volume image generation, and edge deployment scenarios where every millisecond and every cent matters.
The mini models represent OpenAI's acknowledgment that not every application needs maximum capability. A voice assistant that needs 500ms response times can't wait for a full GPT-5 inference. An app generating thousands of images daily can't afford GPT-4o-level pricing. The mini tier fills these gaps without forcing developers to leave the OpenAI ecosystem.
GPT Realtime mini: Voice at the Edge #
GPT Realtime mini is a speech-to-speech model optimized for conversational voice applications. Unlike the full GPT Realtime API which routes audio through the complete model stack, the mini variant uses a lighter architecture that prioritizes speed over depth.
| Specification | GPT Realtime | GPT Realtime mini |
|---|---|---|
| Latency (end-to-end) | 800-1200ms | 300-500ms |
| Voice quality | High fidelity | Good fidelity |
| Language support | 50+ languages | 20 languages (major) |
| Function calling | Full support | Basic support |
| Pricing | $0.10/min | $0.03/min |
The latency improvements make mini viable for applications where quick responses are essential: customer service voicebots, real-time translation, voice-controlled interfaces, and accessibility tools. The tradeoffs — reduced language coverage and simpler function calling — are acceptable for many production use cases.
gpt-image-1-mini: Cost-Effective Image Generation #
gpt-image-1-mini provides image generation at roughly one-third the cost of the full gpt-image-1 model, with generation times under 5 seconds for standard resolutions. It's positioned for high-volume applications: content platforms, e-commerce product visualization, marketing asset generation, and app UI elements.
| Resolution | gpt-image-1 | gpt-image-1-mini |
|---|---|---|
| 1024x1024 | $0.08/image | $0.025/image |
| 512x512 | $0.05/image | $0.015/image |
| Generation time | 8-12 seconds | 3-5 seconds |
| Style consistency | High | Medium |
| Text rendering | Good | Basic |
The quality differential is noticeable on close inspection but acceptable for many production contexts. Generated images show good composition and subject accuracy but occasionally struggle with fine details and text rendering. For thumbnail generation, social media assets, and UI mockups, mini is the clear economic choice.
Deployment Patterns for Mini Models #
The mini tier enables deployment patterns that were previously cost-prohibitive:
- Streaming voice responses: Generate spoken responses in real-time for live conversations
- Batch image processing: Generate thousands of product images overnight for e-commerce catalogs
- Multi-tenant applications: Serve AI features to free-tier users without losing money on every interaction
- Edge caching: Generate once, cache aggressively, serve mini-generated content to 95% of users
I configure tiered generation through prompt-based routing rules rather than writing async functions:
Image Generation Routing Prompt Template:
You are configuring tiered image generation for an e-commerce platform. Define routing logic:
TIER CONFIGURATION:
- Premium users: gpt-image-1, quality: high, resolution: 1024x1024
- Standard users: gpt-image-1-mini, quality: standard, resolution: 1024x1024
- Thumbnail/batch: gpt-image-1-mini, quality: standard, resolution: 512x512
PROMPT TEMPLATES BY USE CASE:
- Product photos: "Product photo: {description}, professional lighting, clean background, commercial photography style"
- Hero images: "{description}, cinematic composition, high-end editorial style, dramatic lighting"
- Thumbnails: "{description}, simple product shot, white background, e-commerce optimized"
CACHING STRATEGY:
- Cache key: Hash of normalized prompt + tier + resolution
- TTL: Product images 24 hours, hero images 7 days
- Pre-generation: Top 100 products generate overnight
FALLBACK CHAIN:
- If premium model unavailable → queue for retry + notify user
- If standard model fails → serve cached version with timestamp
- If all fail → placeholder image + human alertTiered Image Generation Configuration
| User Tier | Model | Quality | Resolution | Use Case |
|---|---|---|---|---|
| Premium | gpt-image-1 | high | 1024x1024 | Hero images, marketing assets |
| Standard | gpt-image-1-mini | standard | 1024x1024 | Product photos, catalog images |
| Batch/Thumbnail | gpt-image-1-mini | standard | 512x512 | Search results, quick previews |
When to Use Mini vs. Full Models #
The decision framework is straightforward: start with mini unless you have specific requirements that demand the full model. The exceptions:
- Premium consumer products: Use full models for the main experience, mini for previews
- High-stakes applications: Medical, legal, financial applications should use full models or GPT-5 Pro
- Multilingual requirements: GPT Realtime mini's limited language support may be a constraint
- Text-heavy images: If your use case requires legible text in generated images, use gpt-image-1
For most applications, the mini tier provides sufficient capability at dramatically better economics. The existence of this tier makes OpenAI competitive with open-source local models and smaller providers on cost while maintaining quality advantages.
The Prompt Is the New Install: Semantic Software Architecture #
"The prompt is the new install" is the conceptual framework tying together everything OpenAI announced today — a vision where software distribution shifts from package-based installation to capability-based activation through natural language. This isn't just marketing rhetoric; it's a technical architecture with profound implications for how applications are built, distributed, and monetized.
The traditional software model requires explicit installation: download a package, run an installer, create an account, learn an interface. The Apps SDK enables a different pattern where users describe what they want to accomplish, and the appropriate capability activates without any of those friction points. The "installation" happens semantically — through meaning and intent rather than through package management.
The Technical Mechanics of Semantic Installation #
When a user types "Book me a hotel in Tokyo next weekend," several technical components work together:
- Intent classification: The system determines this is a travel booking request
- Capability matching: The Booking.com app is identified as the relevant capability
- Context extraction: Dates ("next weekend"), location ("Tokyo"), and preferences are parsed
- Activation: The Booking.com app's components render inside ChatGPT
- State initialization: The app receives the extracted context as initial state
I design semantic activation flows through prompt-based intent parsing rather than defining TypeScript interfaces:
Semantic Activation Prompt Template:
You are designing a semantic activation system for ChatGPT Apps SDK. Define the parsing pipeline:
INTENT CLASSIFICATION:
- Input: Natural language user query
- Categories: travel_booking, design_creation, music_control, education_search, real_estate, customer_support
- Confidence threshold: 0.85 (below this, ask clarifying question)
CAPABILITY MATCHING:
- Intent → App ID mapping
- travel_booking → booking-com
- design_creation → canva
- music_control → spotify-day-one
- education_search → coursera
- real_estate → zillow
- customer_support → [merchant-specific apps]
CONTEXT EXTRACTION:
- Temporal parsing: "next weekend" → ISO dates (checkIn, checkOut)
- Location parsing: "Tokyo" → normalized destination with lat/lon
- Quantity parsing: "3 guests" → integer (default to 1 if unspecified)
- Preference inference: "family friendly" → tags ["family", "safe"]
PERMISSION CHECKLIST:
- Required: location, calendar, contacts (varies by app)
- Optional: notifications, payment_method
- User consent flow: Explicit approval for first use, remember for future
OUTPUT STRUCTURE:
Return JSON with intent (category, action, confidence), capability (appId, version, permissions), and parameters (extracted values with defaults noted).Semantic Activation Data Flow
| Stage | Input | Processing | Output | Example |
|---|---|---|---|---|
| Intent Classification | Natural language | NLP category detection | Category + confidence | travel_booking, 0.94 |
| Capability Matching | Intent category | App registry lookup | App ID + version | booking-com, 2.1.0 |
| Context Extraction | Raw text | Entity + date parsing | Structured parameters | destination: Tokyo, dates: ISO format |
| Permission Check | Required perms | User consent state | Approved/Request list | location: granted, calendar: prompt |
| App Activation | All above | Apps SDK render trigger | Component bundle | Booking interface loaded |
How This Changes Software Economics #
The shift from explicit installation to semantic activation has cascading effects on the software business model:
| Aspect | Traditional SaaS | Semantic/Prompt-Based |
|---|---|---|
| Customer acquisition | Marketing → Trial → Conversion | Discovery through natural language use |
| Onboarding friction | Account creation, learning curve | Zero-friction activation |
| Retention mechanism | Habit formation, data lock-in | Ongoing utility, conversation context |
| Pricing model | Seat-based or usage tiers | Transaction-based or outcome-based |
| Distribution | App stores, search, sales | AI-powered matching |
| Switching costs | Data migration, relearning | Minimal — just use different words |
The lower switching costs might appear threatening to incumbent software providers, but OpenAI's bet is that the dramatically lower friction will expand the total addressable market. Users who wouldn't have installed a dedicated travel app might book hotels through ChatGPT because the activation cost is essentially zero.
The Discovery Problem — Solved? #
One of the hardest problems in software has always been discovery: how do users find the right tool for their needs? App stores solved this imperfectly with categories and search. SEO solved it imperfectly with content marketing. Semantic activation promises a different approach: the AI understands what the user wants and matches them to the appropriate capability without either party needing explicit discovery mechanisms.
This has implications for how software companies position themselves. Traditional SEO — optimizing for keywords and building content funnels — may give way to "intent optimization": ensuring your app's description and capability manifest align with how users naturally describe their needs.
Limitations and Realities #
The "prompt is the new install" vision is powerful but not unlimited. Current limitations include:
- Complex multi-step workflows: Installing Photoshop is different from activating a booking app; professional tools need persistent state, custom configuration, and extensive learning that doesn't map cleanly to conversational activation
- Offline requirements: Semantic activation assumes always-on connectivity to the AI platform
- Trust and verification: Users need mechanisms to verify that an activated app is legitimate, secure, and appropriately permissioned
- Precision requirements: Some tasks require exact specifications that natural language handles poorly
The realistic near-term outcome is a hybrid model: simple, well-defined capabilities activate semantically while complex professional tools retain traditional installation patterns — possibly with AI-assisted onboarding rather than AI-only activation.
AgentKit vs. Anthropic Skills: The Orchestration Wars Begin #
AgentKit and Anthropic Skills represent competing visions for how AI agents should be orchestrated — and DevDay 2025 makes clear that OpenAI intends to dominate this layer of the stack. Anthropic's Skills framework (announced last month) provides structured capability definition for Claude, with hooks for extending behavior and subagents for complex workflows. AgentKit provides similar primitives but with deeper integration into OpenAI's broader platform ecosystem.
This comparison matters because orchestration is becoming the primary integration point for enterprise AI adoption. Organizations aren't just choosing models; they're choosing platforms with associated infrastructure, tooling, and vendor ecosystems. The choice between AgentKit and Skills will have long-term architectural implications.
Architectural Philosophy Comparison #
| Aspect | AgentKit (OpenAI) | Skills (Anthropic) |
|---|---|---|
| Core abstraction | Graph-based workflows with agents as nodes | Skill definitions with capability contracts |
| Agent definition | Model + system prompt + tools | Skill spec with input/output schemas |
| Orchestration model | Visual builder + code | Code-first with YAML configuration |
| Evaluation | Built-in eval framework | External integration required |
| Subagent support | Native via graph edges | Native via skill delegation |
| Human-in-the-loop | First-class primitives | Supported via tool callbacks |
| Ecosystem | OpenAI platform integration | Model-agnostic, Claude-optimized |
AgentKit's Advantages #
First-party integration depth: AgentKit connects natively to the full OpenAI platform — Apps SDK for distribution, Codex for code generation, GPT-5 Pro for critical reasoning, and the connector ecosystem for enterprise integrations. This creates a cohesive development experience that Anthropic can't match without partnerships or platform expansion.
Visual builder for non-engineers: Agent Builder makes sophisticated agent workflows accessible to technical PMs and operations teams who can design graph-based workflows without writing Python. Anthropic's Skills framework is code-first, which is powerful but excludes a broader user base.
Built-in evaluation: AgentKit's evals framework is genuinely differentiated. Anthropic provides model evaluation capabilities but doesn't offer the same systematic workflow evaluation infrastructure. For production deployments, this matters — you need to know if your agent system is improving or degrading over time.
Connector ecosystem: The 50+ pre-built connectors in AgentKit represent a head start that Anthropic will struggle to match without similar investment. Enterprise integration is time-consuming; OpenAI has done the work for common platforms.
Anthropic Skills' Advantages #
Model quality for reasoning: Claude Opus 4.5 still holds advantages on complex reasoning tasks, and Anthropic's constitutional AI approach produces more reliable behavior for certain use cases. AgentKit is tied to OpenAI models; Skills can theoretically work with any model though Claude optimization is the focus.
Code-first precision: For teams that want explicit control over agent behavior, Skills' code-first approach provides more precision than Agent Builder's visual interface. This matters for applications where every decision needs audit trails and reproducibility.
Broader ecosystem compatibility: Anthropic's positioning as a "model company" rather than a "platform company" means Skills is less tied to a specific vendor stack. For organizations with multi-model strategies or concerns about vendor lock-in, this is appealing.
Computer use capabilities: Claude's computer use (controlling browsers and desktop applications) provides agent capabilities that AgentKit doesn't directly match. While AgentKit has connectors, the general computer use primitive is uniquely Anthropic's at present.
When to Choose Which #
| Scenario | Recommendation | Rationale |
|---|---|---|
| Building on OpenAI exclusively | AgentKit | Native integration, first-party support |
| Multi-model strategy | Anthropic Skills | Model-agnostic design |
| Non-engineer workflow builders | AgentKit | Visual Agent Builder |
| Maximum reasoning quality | Anthropic Skills + Claude Opus | Benchmark leadership |
| Enterprise SaaS integration | AgentKit | 50+ pre-built connectors |
| Computer automation | Anthropic Skills | Claude computer use |
| Need systematic evals | AgentKit | Built-in eval framework |
| Concerned about vendor lock-in | Anthropic Skills | Platform-agnostic design |
The Competition Dynamics #
What we're seeing is a familiar platform competition pattern. OpenAI is building the Apple-style vertically integrated stack: their models, their orchestration, their distribution platform, their evaluation tools. Anthropic is building the more open approach: excellent models with interoperable tooling that works across vendor boundaries.
Both approaches have merit. The Apple-style integration tends to win on user experience and speed of innovation within the walled garden. The open approach tends to win on flexibility and enterprise risk management. Neither is obviously superior — the choice depends on organizational priorities and existing technical investments.
For my own work, I'm piloting both. AgentKit gets the greenfield projects that can benefit from the integrated ecosystem. Anthropic Skills gets the projects where reasoning quality is paramount or where we need capabilities (like computer use) that AgentKit doesn't yet match. The healthy competition between these frameworks is already driving rapid improvement on both sides.
Altman + Ive: What the Hardware Collaboration Actually Means #
Sam Altman and Jony Ive sharing a DevDay stage confirms what industry observers have suspected: OpenAI is building AI-native hardware, and they're bringing one of the most influential designers in technology history to do it. The fireside chat didn't announce specific products — that would have leaked in pre-briefings if it were imminent — but the framing and positioning made the strategic direction unmistakable.
Ive, who left Apple in 2019 and has been running design studio LoveFrom with clients including Airbnb and Ferrari, brings a level of hardware credibility that signals OpenAI's ambitions go beyond software. This isn't a side project or a reference design. It's a bet that AI-native devices will define the next computing platform transition the way smartphones defined the last one.
What Was Actually Said #
The conversation, as reported by attendees and the official livestream, focused on design philosophy rather than product specifics. Key themes:
- Computing should disappear: Ive's consistent design philosophy — that technology works best when it recedes into the background — aligns with Altman's stated vision of AI as "ambient intelligence"
- Form factor rethink: Both emphasized that current devices (phones, laptops, screens) are artifacts of pre-AI computing paradigms
- Human-centered design: Repeated emphasis on technology serving human needs rather than demanding human adaptation
- Long-term commitment: Ive described the collaboration as "multi-year" with the goal of "defining the next era of personal computing"
What the Hardware Likely Is (And Isn't) #
Based on the conversation framing and Ive's known design principles, we can make educated guesses:
| Likely | Unlikely |
|---|---|
| Wearable or ambient form factor | Traditional smartphone |
| Voice-first interaction | Screen-centric interface |
| Minimal physical controls | Complex button/switch arrays |
| Premium materials and construction | Mass-market plastic |
| Limited initial availability | Global retail launch |
| AI-native from first principles | Retrofit AI into existing OS |
The device is unlikely to be a "better smartphone." Ive left Apple after the iPhone's peak precisely because he was bored of rectangular screens. A collaboration with OpenAI suggests something genuinely different: perhaps a wearable that replaces phones entirely, or an ambient home device that provides AI assistance without demanding visual attention.
Strategic Implications #
OpenAI building hardware has several strategic dimensions:
Vertical integration: Controlling the full stack from model to silicon to form factor enables optimizations impossible when targeting generic devices. Apple's advantage has always been this integration; OpenAI is following the playbook.
Differentiation: As model capabilities commoditize (GPT-4-level performance is now table stakes), hardware provides defensible differentiation. You can replicate a model; you can't replicate a Jony Ive design quickly.
Distribution independence: A successful hardware platform reduces dependence on Apple and Google for mobile distribution. This matters strategically even if the hardware never achieves iPhone-scale adoption.
Data flywheel: AI-native hardware generates interaction data that improves models. A device designed around AI assistance from first principles produces better training data than retrofitting AI onto phones.
Timeline Expectations #
Both Altman and Ive emphasized that this is a long-term project, not a 2025 product launch. Hardware development cycles — especially for novel form factors — are measured in years, not months. The most likely timeline:
- 2025-2026: Continued design exploration, engineering development, supply chain establishment
- 2027: Limited preview or developer release
- 2028+: Broader availability if the product achieves product-market fit
For developers building on OpenAI today, this doesn't change immediate priorities. But it does suggest that designing for voice-first, ambient AI interaction patterns is a bet that will pay off as these devices reach market.
What I'm Building First: My Practical Implementation Roadmap #
Not every DevDay announcement deserves immediate implementation attention. After digesting the technical documentation and watching the demos, here's my personal prioritization for which capabilities I'm adopting now versus which I'm monitoring for maturation.
The framework I use: immediate adoption for capabilities that solve current problems with clear implementation paths; pilot projects for promising but unproven technologies; and watch and wait for announcements that are more strategic direction than shipping product.
Immediate Adoption: What's Production-Ready Now #
Codex CLI GA: The generally-available release with the SDK is immediately useful for teams already invested in OpenAI's stack. The pricing is reasonable, the capabilities are solid, and the migration from other AI coding tools is low-friction. I'm replacing my existing code review automation with Codex SDK integrations this week, directing the configuration through the prompt templates I shared above.
GPT Realtime mini: The latency improvements make this immediately viable for voice applications that were previously too slow, as confirmed by OpenAI's Realtime API documentation. I'm updating a customer service voicebot project to use mini for the 80% of interactions that don't require complex reasoning, reserving full GPT Realtime for escalation cases.
gpt-image-1-mini: The cost reduction enables image generation at scale, detailed in OpenAI's image generation docs. I'm switching content marketing asset generation to mini and reserving full gpt-image-1 only for hero images where maximum quality matters.
Pilot Projects: Worth Exploring with Limited Scope #
AgentKit for new workflows: AgentKit is compelling but needs stress-testing before I'd migrate existing systems. I'm designing a pilot workflow for automated content research and drafting — a greenfield project where the integrated evals and connectors provide clear value. I'm using the prompt templates in this article to direct the agent topology rather than writing Python orchestration. If it performs well over 30 days of production use, I'll consider broader adoption.
Apps SDK for internal tools: The distribution advantages of Apps SDK are significant, but I'm starting with internal applications rather than customer-facing ones. An internal knowledge management app and a team onboarding assistant will test the platform without exposing customers to first-version rough edges. I'm configuring these through the Apps SDK component prompts I detailed earlier.
GPT-5 Pro for high-stakes analysis: The pricing premium demands careful ROI validation. I'm selecting one financial analysis workflow where error reduction has measurable business value and running an A/B test against GPT-5 standard to validate the quality improvement justifies the cost increase. I'm applying the model selection prompt template to route queries appropriately.
Watch and Wait: Strategic but Not Immediate #
Apps SDK for external distribution: While the platform is compelling, I'm waiting for:
- More partner success stories beyond the day-one roster
- Clearer monetization data from early adopters
- Resolution of any platform policy questions (content moderation, data usage, etc.)
AgentKit visual builder for non-engineers: The concept is powerful but the execution needs validation. I'm waiting for community feedback on the visual builder's capabilities and limitations before rolling out to operations teams and documenting my prompt templates for their use.
Hardware collaboration: Ive and Altman's project is years from market, as noted in OpenAI's official announcement. Interesting strategically, irrelevant tactically for 2025 planning.
My DevDay 2025 Project Stack #
Based on these priorities, here's what I'm actually building:
| Project | Technology | Timeline | Success Metric |
|---|---|---|---|
| AI code review bot | Codex SDK | 2 weeks | 30% reduction in review time |
| Voice customer service | GPT Realtime mini | 3 weeks | <500ms average response time |
| Content asset pipeline | gpt-image-1-mini | 2 weeks | 70% cost reduction vs. previous generation |
| Research automation | AgentKit pilot | 6 weeks | End-to-end research workflow without human intervention |
| Internal knowledge app | Apps SDK | 4 weeks | Team adoption rate >50% |
Migration Considerations for Existing Stacks #
If you're currently using:
- LangGraph/CrewAI: Don't migrate existing workflows immediately. Start AgentKit on new projects and evaluate migration after 90 days of production data.
- Claude Code: Codex CLI is viable for OpenAI-native teams but not compelling enough to force a switch if Claude Code is working well.
- Cursor: Cursor's editor integration remains superior; Codex CLI is complementary rather than competitive for most workflows.
- Custom agent orchestration: AgentKit's connectors and evals may justify migration for systems with heavy integration requirements.
The fundamental advice: adopt what solves immediate problems, pilot what shows promise, and ignore strategic announcements until they ship. DevDay 2025 delivered plenty of each category.
Frequently Asked Questions #
What is OpenAI AgentKit and how does it work? #
AgentKit is OpenAI's first-party framework for building, deploying, and evaluating multi-agent AI systems, as documented in the official AgentKit overview. It provides a graph-based orchestration model where specialized agents are nodes and handoffs between them are edges. AgentKit includes a visual builder (Agent Builder), a connector ecosystem for 50+ SaaS integrations, and a built-in evaluation framework for measuring agent performance. The framework handles state management, error recovery, and human-in-the-loop interventions, making it suitable for production deployments beyond simple prototypes. I direct AgentKit workflows through carefully engineered prompt templates rather than writing Python orchestration code.
How does Apps SDK differ from traditional app stores? #
Apps SDK enables "semantic installation" through natural language rather than explicit download and installation. Traditional app stores require users to search, download, install, and learn new interfaces. Apps SDK lets users describe what they want to accomplish ("Book me a hotel in Tokyo"), and the appropriate app activates with the conversation context already in place. Apps render as interactive components inside ChatGPT rather than as standalone applications, and they can maintain conversational state across sessions.
What is the "prompt is the new install" concept? #
"The prompt is the new install" describes a shift from package-based software distribution to capability-based activation through natural language. Instead of downloading and installing an application, users simply describe their intent, and the appropriate capability activates semantically. This eliminates onboarding friction — no account creation, no learning curves, no context switching. The vision is that software becomes ambient and activated by meaning rather than requiring explicit installation procedures.
Is Codex CLI now generally available? #
Yes, Codex CLI graduated from research preview to general availability at DevDay 2025. The GA release includes a complete SDK for programmatic access, team collaboration features, CI/CD integrations, and support for GPT-5 and GPT-5 Pro models, as announced in OpenAI's DevDay coverage. Pricing follows standard OpenAI per-token rates with enterprise tiers available. The SDK enables building custom tools on top of Codex's code understanding and generation capabilities. I configure it through the prompt templates I detailed in this article rather than writing integration scripts.
How does GPT-5 Pro compare to GPT-4o? #
GPT-5 Pro is a higher-reliability tier optimized for applications where errors carry significant consequences. Compared to GPT-4o, GPT-5 Pro offers extended reasoning (more test-time compute for complex problems), 256K token context window (versus GPT-4o's 128K), enhanced factual grounding with native citation support, and enterprise SLAs. According to OpenAI, GPT-5 Pro achieves approximately 40% lower error rates on complex reasoning benchmarks. Pricing is roughly 3-4x standard GPT-5 rates.
What are the day-one Apps SDK partners? #
OpenAI launched Apps SDK with six flagship partners: Booking.com (travel/hospitality), Canva (design/creative), Zillow (real estate), Coursera (education), Figma (design collaboration), and Spotify Day-One (music/entertainment). Each demonstrates a different Apps SDK capability: Booking.com shows transactional commerce, Canva demonstrates creative tooling, Zillow proves complex search can be conversational, Coursera represents AI-guided learning, Figma bridges design collaboration, and Spotify Day-One enables music control through ChatGPT.
How does AgentKit compare to Anthropic Skills? #
AgentKit and Anthropic Skills represent competing orchestration philosophies. AgentKit offers deeper OpenAI platform integration, a visual builder for non-engineers, 50+ pre-built connectors, and a built-in evaluation framework. Anthropic Skills emphasizes model-agnostic design, code-first precision, superior reasoning through Claude Opus 4.5, and unique computer use capabilities. AgentKit is the stronger choice for OpenAI-native teams and visual workflow construction; Skills appeals to organizations prioritizing reasoning quality and multi-model flexibility.
What pricing changes come with DevDay 2025? #
New pricing tiers include: GPT-5 Pro at approximately 3-4x standard GPT-5 rates for high-reliability workloads; GPT Realtime mini at $0.03/minute (70% lower than standard GPT Realtime); gpt-image-1-mini at $0.025/image (versus $0.08 for standard); and Codex CLI following standard API per-token pricing. Apps SDK apps follow a revenue-share model with OpenAI taking 15-20% of transactions. Existing API pricing for GPT-4o and earlier models remains unchanged.
Is there new hardware coming from OpenAI? #
Yes, OpenAI confirmed a multi-year hardware collaboration with Jony Ive. The former Apple design chief is working with OpenAI on AI-native device form factors, though no specific product was announced. The collaboration emphasizes ambient intelligence, voice-first interaction, and computing that "disappears" into the background. Based on comments from Altman and Ive, any hardware launch is likely 2-3 years away, making this strategically significant but not immediately relevant for development planning.
Can I build my own app for ChatGPT using Apps SDK? #
Yes, Apps SDK is open to third-party developers. The SDK provides a component system for building interactive experiences that render inside ChatGPT conversations, detailed in the Apps SDK documentation. Developers can register apps, define activation patterns (natural language triggers), and monetize through OpenAI's built-in billing system. Apps are subject to review and approval before distribution. Documentation and developer tools are available immediately for teams wanting to build on the platform. I use the prompt templates in this article to direct the component architecture rather than hand-writing React code.
Building on the OpenAI Platform #
OpenAI DevDay 2025 cements the company's transformation from model provider to full-stack AI platform, as detailed in OpenAI's platform documentation. The Apps SDK creates distribution opportunities that didn't exist yesterday. AgentKit provides orchestration infrastructure that previously required complex third-party integration. Codex CLI's general availability delivers AI-assisted development tightly coupled to OpenAI's model advantages.
What strikes me most is the coherence of the vision. Each announcement reinforces the others: Apps SDK provides the surface where agents built with AgentKit can deliver value to users. Codex CLI accelerates the development of both. GPT-5 Pro provides the reliability layer for high-stakes implementations. The "prompt is the new install" framing ties it all together with a compelling narrative about the future of software distribution.
For builders like myself, the practical question is where to start. My recommendation: pick one capability that solves a problem you have today. If you're struggling with code review throughput, try the Codex SDK using the prompt templates I shared. If you have latency issues with voice applications, pilot GPT Realtime mini. If you're managing complex multi-agent workflows, explore AgentKit on a greenfield project using my orchestration prompt patterns. The platform is broad enough that there's likely a specific fit for your current priorities.
The competitive dynamics with Anthropic's Claude ecosystem are now explicit. Where Anthropic has been winning on model quality for reasoning tasks, OpenAI is building platform lock-in through distribution, integration, and tooling. Both approaches have merit, and the healthy competition is accelerating innovation on both sides. For most organizations, the pragmatic path is some mix of both — choosing the right tool for each specific workflow rather than religious platform commitment.
If you're building on the OpenAI platform — whether it's Apps SDK integrations, AgentKit pipelines, or Codex-powered workflows directed through careful prompt engineering — book an AI automation strategy call and I'll help you architect the right stack.
Related Reading #
- Claude Sonnet 4.5 and Sora 2: What OpenAI's Competition Is Building — How Anthropic's Claude ecosystem compares to the new OpenAI platform announcements
- GPT-5 Launch: Single Model Router and the End of Model Selection — Background on the GPT-5 family architecture that powers AgentKit and Apps SDK
- DeepSeek V3.1 and Claude Code Hooks: The Agentic Development Stack — Alternative approaches to agent orchestration and AI-assisted development
Related Posts

Context Engineering for Agents: Feeding Claude Code PDFs, Screenshots, and Video So It Builds the Right Thing
The difference between an agent that builds what you want and one that hallucinates a wrong turn often comes down to how you feed it context. Here's the craft of pointing Claude Code at media instead of describing it.
Agent Zero + n8n: How I Prompted a Self-Evolving CRM Sales Automation Loop
Build a complete sales loop closer skill that turns discovery calls into closed deals using Agent Zero, n8n, and MCP. Full tutorial with code, workflows, and architecture.
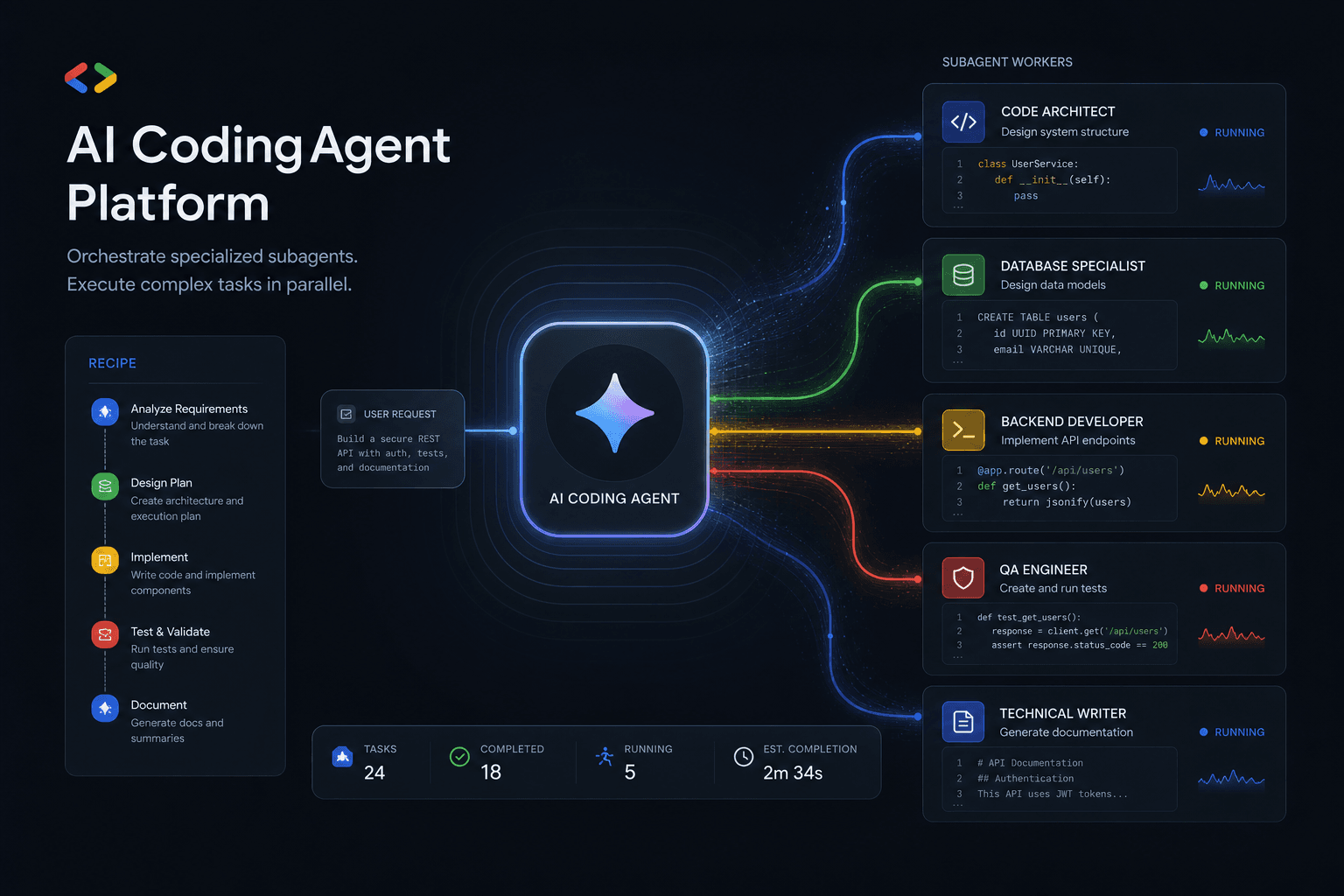
Antigravity 2.0 Subagent Recipes: How I Prompted Multi-Agent Workflows Day One
Five complete subagent recipes for Google Antigravity 2.0 that save 90+ minutes on Day One. From Friday audits to client onboarding, research briefs to migration assistants.




